Frage von hokusfokus79:Hallo zusammen, hier mal ein kurzes
BEISPIELVIDEO :
mir tut sich nun folgende Fragestellung auf :
wenn ich - egal mit welcher kamera - 4k aufnehme,
und dieses 4k footage dann zb in PP CC
re-rendere auf 1080..
(zb links den 4k CLIP MOV nach rechts ziehe, dann eigenschaften
und dort die Auflösung von 3840 x 2160 auf 1920x1080 ändere
habe ich dann DEFINITIV ein 1080 4:4:4 ?? oder
gibt es diese mathematische Faustregel nicht ?
wie kann es sein, dass es kaum consumer kameras gibt, die FHD 1920 10bit 422/444 können ? aber gleichzeitig behauptet wird, dass dann praktisch durch softwareeingriff 4k->1080 ein 1080 4:4:4 entstünde ? ist das so korrekt verstanden von mir ?
Vielen Dank
HF
UPDATE : Oder habe ich das alles falsch verstanden und es geht nur darum : "lade dein Videomaterial in höchstmöglicher 4k Qualität zu youtube und es schaut weltweit auf allen 1080 monitoren BESSER aus, als dasselbe Video, wenn in FHD 1080 hochgeladen... ?
(was mathematisch keinen sinn ergäbe...optisch mathematisch*aargh*)
Antwort von mash_gh4:
du kannst ja auch schon in 4K 4:4:4 haben. ist zwar bei den meisten sensoren auf bayer pattern basis eher unrealistisch, aber prinzipiell möglich.
es geht also um ein verkleinern, bei dem jeweils vier pixel des ursprünglichens bilds zusammenfasst werden, aber die farbkanäle nicht in gleicher weise skaliert werden. so kommt man dann tatsächlich 4k 4.2:0 zu 2K 4:4:4.
die gründe, warum das nicht nicht gleich in der kamera angeboten wird, haben eben einerseits mit den physischen vorgaben durch den sebser zu tun. ein sensor mit bayer pattern liefert eben auch nicht viel mehr farbauflösung als die 4:2:2 oder 4:2:0, aber auch die meisten consumer video-codecs kommen mit entsprechender farbunterbatatsung in der bildrepräsenation besser klar.
Antwort von TomStg:
habe ich dann DEFINITIV ein 1080 4:4:4 ?? oder
gibt es diese mathematische Faustregel nicht ?
Du meinst nicht "runtersamplen", sondern downscalen.
Du erhälst definitiv kein 4:4:4, sondern es bleibt bei 4:2:2. Genausowenig entsteht aus 4:2:0 kein 4:2:2. Was vom Sensor nicht aufgenommen wurde, fällt nicht plötzlich vom Himmel. Es gibt dazu völlig andere Ansichten, siehe oben, aber keinen Beweis.
Dieses Thema wurde hier schon 3125x ausführlichst diskutiert. Dieses Gerücht hält sich hartnäckig, macht es aber physikalisch nicht wahrer.
Antwort von hokusfokus79:
du kannst ja auch schon in 4K 4:4:4 haben. ist zwar bei den meisten sensoren auf bayer pattern basis eher unrealistisch, aber prinzipiell möglich.
es geht also um ein verkleinern, bei dem jeweils vier pixel des ursprünglichens bilds zusammenfasst werden, aber die farbkanäle nicht in gleicher weise skaliert werden. so kommt man dann tatsächlich 4k 4.2:0 zu 2K 4:4:4.
die gründe, warum das nicht nicht gleich in der kamera angeboten wird, haben eben einerseits mit den physischen vorgaben durch den sebser zu tun. ein sensor mit bayer pattern liefert eben auch nicht viel mehr farbauflösung als die 4:2:2 oder 4:2:0, aber auch die meisten consumer video-codecs kommen mit entsprechender farbunterbatatsung in der bildrepräsenation besser klar.
Danke dafür.. also besteht tatsächlich immer eine Art "problemchen" wenn es darum geht :
a.) ein in 4k gedrehtes video, sollte in 4k zu youtube etc hochgeladen werden, WEIL weltweit wird es dann tatsächlich selbst auf allen 1080er monitoren besser aussehen als wenn man
b.) ein in 4k gedrehtes video, zuhause in 1080 umrendert und dieses dann zu youtube etc hochlädt ?
sprich : will ich das maximale auf einem 1080er monitor herausholen, wäre es anzuraten alles in 4k zu drehen oO...
mist, dann brauch ich mindestens ne Blackmagic ! :D
Antwort von hokusfokus79:
habe ich dann DEFINITIV ein 1080 4:4:4 ?? oder
gibt es diese mathematische Faustregel nicht ?
Du meinst nicht "runtersamplen", sondern downscalen.
Du erhälst definitiv kein 4:4:4, sondern es bleibt bei 4:2:2. Genausowenig entsteht aus 4:2:0 kein 4:2:2. Was vom Sensor nicht aufgenommen wurde, fällt nicht plötzlich vom Himmel. Es gibt dazu völlig andere Ansichten, siehe oben, aber keinen Beweis.
Dieses Thema wurde hier schon 3125x ausführlichst diskutiert. Dieses Gerücht hält sich hartnäckig, macht es aber physikalisch nicht wahrer.
"danke, ja, dazu müsste man wohl von kindauf assembleraffin gewesen sein, um richtig zu verstehen wie in maschinensprache aus sensordaten/bildern einsen und nullen werden, wie diese pakete dann als "Container" verfrachtet werden und letzendlich von kompressoren, webstandards und heimischen 8bit geräte wieder dekompiliert visualisiert werden"
(bitte nicht lachen, aber ich denke man könnte das so umschreiben?)
aber natürlich meinte ich : wenn ich ein 4k "herunterrendere" zu einem fertigen 1080 projekt und es anschließend zb neu lade zum bearbeiten, dann hätte ich also tatsächlich viel mehr möglichkeiten der nachbearbeitung , so zb helligkeit/kontrast/RGB, als wie wenn ich das ganze in pur gedrehtem FHD 1920x1080 bearbeite... ..
(ich vermute, dann bräuchte ich aber auch einen 10bit 444 monitor, um das zu verstehen und zu sehen)
Antwort von WoWu:
Du bekommst weder bei einer Unterabtstung (Downscaling) 4:4:4 noch werden aus 8 Bit 10 Bit.
Bei einer Unterabtastung in der Kamera (4:2:0) werden Farben interpoliert. An einer Schnittstelle von 2 Farben, z.B. Rot und Grün, entsteht ein gelber Wert.
Der ist jetzt im Bild 4:2:0 enthalten, obwohl er in der Szene gar nicht vorhanden war. Das ist das Produkt einer Unterabtstung in der Kamera.
Wenn Du jetzt weiter unterabtastest, z.B. von 4K nach 2K, wird dieser Farbfehler ja nicht kleiner, sondern größer, weil an den beiden Übergängen von GB nach RT und GB nach GN jeweils wieder eine Interpolation stattfindet.
Statt das der Farbfehler weggeht, kommen zwei weitere Mischfarben hinzu, die in der Szene ebensowenig waren.
Es ist also Quatsch, was da in Bezug auf Video erzählt wird.
Rechnerisch kann man eine andere Matrix zwar erstellen, das bezieht sich aber nur auf Farben, die im Rechner neu erstellt werden, was bei Video nicht der Fall ist, weil Du fertige Bilder vorgibst.
Das mit 4 K YouTube liegt daran, dass ein 4K Film eine höhere Bandbreite bei der Ausspielung alocated, als mit einer höheren Bitrate übertragen wird, als wenn ein 2K Film übertragen wird.
Liegen beide Bandbreiten jeweils am unteren Limit, geht der Verlust jeweils von den oberen Frequenzen ab, also von den feinen Auflösungen.
Nimmt man sich von 4K was weg, ist immernoch reichlich für 2K vorhanden, anders wenn 2K in der Ünertragung beschnitten wird, da geht gleich etwas von Deinem Nutzsignal weg.
Das ganze funktioniert aber nur mit Bandbreiten um die 40 MBit/s weil das zu DASH Videos verarbeitet wird und die Fragen die Bandbreite am Empfänger ab und senden bei mangelnder Bandbreite sowieso nur eine herunterskalierte Version.
Also ... funktioniert auch nur bei sehr wenigen, die über eine gute "Letzte Meile" verfügen.
Antwort von mash_gh4:
Es gibt dazu völlig andere Ansichten, siehe oben, aber keinen Beweis.
so bald du grundsätzlich verstehst, was 4:2:0 und 4:2:2 in der digitalen bildrepräsentation tatsächlich bedeuten -- das also das bild in drei
planes gegliedert ist, wovon nur die erste, die die helligkeitsangaben enthält, voll aufgelöst ist, während die andern beiden, also die farbinformation, eben nur ein viertel od. die hälfte der pixel enthalten -- ist das ganze eigentlich ziemlich trivial nachzuvollziehen. da braucht man keine großen beweise, sondern nur ein bisserl sachkundigkeit.
aber natürlich überlass ich es gerne den kollegen aus der analogfraktion, das auch weiterhin im sinne eines glaubenskriegs zu stilisieren, satt einfachst nachzuvollziehende fakten zur kenntnis zu nehmen. es hat wirklich keinen sinn darüber mit denen zu streiten, die es einfach nicht verstehen wollen.
Antwort von Axel:
4:4:4 wäre ohnehin nur für einen Teilaspekt der Farbkorrektur besser: das Keying.
Und hier ist es kein moderner Mythos, sondern ein wichtiger Erfahrungswert, dass eine höhere Pixelauflösung (als die Ausgabegröße vorsieht, ob nun reell UHD oder bloß nominell) wichtiger für saubere Mattekanten ist als genauere Farbabtastung. (EDIT - Zur Erklärung: man erfasst ja in der Farbkorrektur sowohl Farbwerte als auch die von ihnen gefüllten Bildflächen, das ist also Keying)
Und hier stimmt, auf Umwegen, die Gleichung. UHD in einer HD-Comp lässt sich keyen
als wäre es HD 444.
Allerdings ist die Erkenntnis nicht neu. Schon zu SD-Zeiten wurde geraten, zu keyende Bildpartien immer möglichst bildfüllend aufzunehmen und in der Comp kleiner zu skalieren. Vertikale Motive (sitzende oder stehende Menschen) sollte man sogar hochkant aufnehmen.
Wie gut oder schlecht ein 4k-Bild ist, kann ich zum Beispiel jetzt auf meinem 5k-Display besser beurteilen. Dort sieht 4k aus wie ehemals HD. HD sieht aus wie ehemals 720p. Der Bildschirm ist ja nicht wesentlich größer geworden. UHD haut mich nicht vom Hocker. Ich stelle aber fest, dass ich beginne, HD entweder zu klein oder matschig zu finden.
Ich fürchte, das Ende der Fahnenstange ist noch lange nicht erreicht. Man gewöhnt sich an das Neue nicht deswegen, weil es besser ist, sondern weil man am Alten Mängel entdeckt.
Antwort von WoWu:
Es gibt dazu völlig andere Ansichten, siehe oben, aber keinen Beweis.
so bald du grundsätzlich verstehst, was 4:2:0 und 4:2:2 in der digitalen bildrepräsentation tatsächlich bedeuten -- das also das bild in drei
planes gegliedert ist, wovon nur die erste, die die helligkeitsangaben enthält, voll aufgelöst ist, während die andern beiden, also die farbinformation, eben nur ein viertel od. die hälfte der pixel enthalten -- ist das ganze eigentlich ziemlich trivial nachzuvollziehen.
Ja, das war im C64 so der Fall, dass mit Bitplanes zur Grafikanwendung gearbeitet wurde. Da waren die Farbinformationen der Pixel in einer oder mehreren Bitplanes gespeichert, weil kein ausreichender Arbeitsspeicher verfügbar war, mit dem entsprechenden Nachteil im Zugeiff, wenn einzelne Bits im Speicherwort nicht direkt zugreifest waren.
Was haben wir heute ? 2016. .... Das war 1986.
Ansonsten erklär' doch einfach mal, wie man heute damit mit wenig Rechenaufwand umgehen kann, weil sich an der Funktionsweise und den Nachteilen nichts geändert hat und erklär' auch am Besten gleich mit, wie bei Planes die bereits vorhandenen Interpolationsfehler beseitigt werden, denn wir sprechen hier nicht über Computergrafik sondern über Video.
Antwort von mash_gh4:
Ja, das war im C64 so der Fall, dass mit Bitplanes zur Grafikanwendung gearbeitet wurde. Da waren die Farbinformationen der Pixel in einer oder mehreren Bitplanes gespeichert, weil kein ausreichender Arbeitsspeicher verfügbar war, mit dem entsprechenden Nachteil im Zugeiff, wenn einzelne Bits im Speicherwort nicht direkt zugreifest waren.
Was haben wir heute ? 2016. .... Das war 1990.
schau dir vielleichtt besser den beispielcode ganz unten auf folgender seite an (einfach nach "plain" suchen :)):
https://en.wikipedia.org/wiki/YUV
das sind wirklich die basics, wenn es um digitale bildverarbeitung geht, die ein bisserl bunter aussehen soll...
und erklär' auch am Besten gleich mit, wie bei Planes die bereits vorhandenen Interpolationsfehler beseitigt werden, denn wir sprechen hier nicht über Computergrafik sondern über Video.
die interpolation ist von anfang an in den daten enthalten -- die werte in den beiden color planes beziehen sich ja jeweils auf eine größere gruppe von pixeln in der Y plane bzw. deren mittelwert. es kommt da also nichts hinzu, sondern es wird vielmehr nur ein teil der information anders behandelt und in der ursprünglichen auflösung
erhalten, während der rest tatsächlich verkleinert wird.
das einzige was bei dieser zauberei notwendig ist, ist ein unabhängiges skalieren der helligkeitsinformation, ohne die farbkanäle in gleicher weise mitzuverkleinern...
wenn man das allerdings nicht sauber macht, sondern alle kanäle einfach in gleicher weise behandelt bzw. skaliert, ist das ergebnis natürlich auch wieder unterabgetastet -- aber dafür natürlich kleiner.
EDIT: letzter fall ist aber ohnehin nicht wirklich von relevanz, weil es im wesentlichen ja um die frage geht, wie sich das in der praxis bemerkbar macht. und dort ist es einfach so, dass das material intern in den bildbearbeitungsprogrammen normalerweise als RGB ohne farbunterabtastung verarbeitet wird. dank dieses umstands zeigt sich der beschriebene effekt auch ohne irgendwelche komplizierten umwege, wenn man einfach nur 4:2:0 4K material in einer 1080p timeline verwendet.
Antwort von WoWu:
Ist nur schade, dass die Kamera bereits unterabgetastet hat und der Fehler bereits im Bildinhalt vorhanden ist.
Wie reden hier über Video einer Kamera und nicht über die Verarbeitung einer Computergrafik.
Selbst also, wenn es gelänge ohne weitere Unterabtastung (Interpolation) das Kameramild zu erhalten (nicht zusätzlich zu beeinträchtigen), bliebe es 4:2:0, (egal wie die Farbmatrix rechnerisch beschaffen ist) weil der vorhandene Fehler nicht rück-rechnenbar ist.
Außerdem, wenn das mit einem solchen Algorithmus ginge, hätte jede Schrottkamera in HD ein 444 Bild.
Das würde sich doch kein Hersteller entgehen lassen.
Antwort von mash_gh4:
Ist nur schade, dass die Kamera bereits unterabgetastet hat und der Fehler bereits im Bildinhalt vorhanden ist.
wie gesagt: es geht hier nicht um ein reinzaubern von nichtvorhandenen daten, sondern ausschließlich darum, das angaben wie 4:2:2 und 4:2:0 nichts anderes als das
verhältnis der verhandenen bildauflösung in den verschiedenen kanälen od. planes des bilds angeben.
wenns't ein bild also in der beschrieben weise verkleinert hast, liegt tatsächlich in allen kanälen die selbe auflösung vor -- also 4:4:4
dass das bild dadurch nicht schärfer wird, wird keinen verwundern -- an farbinformation geht dabei allerdings wirklich nichts verloren!
du kannst es auch mit drei körben voll äpfel, birnen und orangen durchspielen.
in diesem fall würden sich in analogie zur videoinformation im korb mit den äpfen genaue die vierfache anzahl an äpfen bezogen auf die anzahl der biinen und orangen befinden. beim verkleinern der menge geht man nun so vor, dass nur die anzahl der äpfel auf ein viertel reduziert wird, nicht aber die der birnen und orangen. man hat also schließlich drei körbe, die genau die selbe anzahl an jeweiligem obst enthalten. und genau dieses verhältnis wird eben durch das 4:4:4 ausgedrückt. und wie du an hand dieser illlustration auf grundschulniveau unschwer erkennen kannst, ist es dabei gar nicht notwendig irgendwelche äpfel zu spalten! die birnen und orangen sind zwar nicht mehr geworden, aber den äpfeln gegenüber nun zumindest im selben verhältnis vorhanden. mehr als das kann man wohl ohnehin nicht erwarten.
Wie reden hier über Video einer Kamera und nicht über die Verarbeitung einer Computergrafik.
da ist in dem fall kein unterschied!
jpeg standbilder nutzen bspw. genau die selben mechanismen.
das spannendere ist eher die tatsache, dass heutige kameras in fast allen fällen ihre farbinformation aus mehreren nebeneinanderliegenden sensel gewinnen. obwohl dafür -- so wie du das immer wieder verlangst -- eigentlich viel mehr bunte sensel vorhanden sein müssten, um ein vollwertiges 4K RGB bild ohne farbunterabtastung zu gewinnen, reichen die tatsächlich vorhanden bzw. in den auflösungensangeben gewöhnlich genannte anzahl aber sehr wohl aus, um ein bild mit 4:2:0 od. 4:2:2 farbsubsampling mit vertretbaren abweichungen vom technischen ideal (=einem runtersamplen von in übermaß vorhandener bzw. nicht übertragbarerer information) zu gewinnen.
Antwort von Roland Schulz:
Aus 4K/UHD 4:2:2 oder 4:2:0 wird DEFINITIV 2K/FHD 4:4:4!!!!!!!!
Unterabtastung verstehen und schlau ins Bett gehen...
Es spielt keine Rolle was die Kamera vorher gemacht hat, in vielen Fällen wissen wir das auch nicht. Wenn"s nach dem Downscale kein 4:4:4 wird war"s vorher auch weder sauberes 4:2:0 noch 4:2:2!!!
Hat die Kamera vorher schon durch Oversampling ein "sauberes" 4K/UHD Bild gemacht oder nicht, hatten wir ggf. eine voll auflösende 3 Chip Kamera... für die Theorie gilt Zeile 1, darum gehts!
Die Quelle spielt keine Rolle, es geht um"s Downscale der Unterabtastung!
Die aus 8bit UHD wird 10bit FHD Nummer ist dagegen völliger Blödsinn, auch wenn Barry Green und Panasonic was anderes verkaufen wollen!
Nach "deren Methode" kann maximal an einem Pixelübergang/4er Block eine Interpolation mit Abbildung einer höheren Quantisierung erfolgen. Ob dieser Zwischenwert aber vorher da war und richtig ist weiß niemand!
Was passiert wenn zwei größere, homogene Flächen im Bild sind, die nach der Umrechnung aus einer beliebigen Dynamik auf 8bit ihre vorherige Differenz zueinander verlieren. Nach Downscale und Dynamikerweiterung auf 10bit ist die Information futsch, da wird keine Differenz mehr zurückgewonnen!
8bit UHD -> 10bit FHD -> Quatsch!!!
Das alles heißt nicht, dass eine Verarbeitung von 8bit Material in einer 10bit Kette sinnlos ist. Das macht dann Sinn, wenn Signale mit Faktoren verrechnet werden, darüber gab"s hier kürzlich nen Thread...
Bei allem darf man auch nicht vergessen, ob das in der Praxis eingesetzte NLE und der Codec überhaupt 4:4:4 beherrschen...
Antwort von Roland Schulz:
Ist nur schade, dass die Kamera bereits unterabgetastet hat und der Fehler bereits im Bildinhalt vorhanden ist.
wie gesagt: es geht hier nicht um ein reinzaubern von nichtvorhandenen daten, sondern ausschließlich darum, das angaben wie 4:2:2 und 4:2:0 nichts anderes als das
verhältnis der verhandenen bildauflösung in den verschiedenen kanälen od. planes des bilds angeben.
wenns't ein bild also in der beschrieben weise verkleinert hast, liegt tatsächlich in allen kanälen die selbe auflösung vor -- also 4:4:4
dass das bild dadurch nicht schärfer wird, wird keinen verwundern -- an farbinformation geht dabei allerdings wirklich nichts verloren!
du kannst es auch mit drei körben voll äpfel, birnen und orangen durchspielen.
in diesem fall würden sich in analogie zur videoinformation im korb mit den äpfen genaue die vierfache anzahl an äpfen bezogen auf die anzahl der biinen und orangen befinden. beim verkleinern der menge geht man nun so vor, dass nur die anzahl der äpfel auf ein viertel reduziert wird, nicht aber die der birnen und orangen. man hat also schließlich drei körbe, die genau die selbe anzahl an jeweiligem obst enthalten. und genau dieses verhältnis wird eben durch das 4:4:4 ausgedrückt. und wie du an hand dieser illlustration auf grundschulniveau unschwer erkennen kannst, ist es dabei gar nicht notwendig irgendwelche äpfel zu spalten! die birnen und orangen sind zwar nicht mehr geworden, aber den äpfeln gegenüber nun zumindest im selben verhältnis vorhanden. mehr als das kann man wohl ohnehin nicht erwarten.
Wie reden hier über Video einer Kamera und nicht über die Verarbeitung einer Computergrafik.
da ist in dem fall kein unterschied!
jpeg standbilder nutzen bspw. genau die selben mechanismen.
mash_gh4: +10 ;-)!!!!!
...nehmt einfach ne nativ auflösende 3-Chip Kamera oder generischen Inhalt. Es interessiert nen S...... was die Kamera vorher unterschlagen hat, die Antwort der theoretischen Frage nach UHD 4:2:0 -> FHD 4:4:4 ist HUNDERTPROZENTIG JA!!!
Antwort von WoWu:
Schau einfach mal auf das Kamerabild 4:2:0 denn da sind in Deinem Apfelkorb bereits Orangen drin (gelbe Linien) die Du hinterher auch nicht mehr raus bekommst.
Dein Bild bleibt ... wie immer Dein Farbraster hinterher ausfällt .... 4:2:0
Es geht nicht um die Verhältnisse der Farbmatix zueinander, sondern um die Effekte im Bild.
Wie gesagt ... jeder Hersteller würde mit Kusshand seine Kameras in 4:4:4 anbieten und was die Anzahl der verwendeten Farbwerte im De-Bayering angeht, so verändern sich zwar die Resultate, nicht aber der Umstand, dass bei einer Farbinterpolation (und die findet bereits in der Kamera statt) eine Fehlfarbe entstehet. Der Algorithmus sagt nur noch etwas darüber aus, wie die Fehlfarbe aussieht.
Wir reden über zwei verschiedene Dinge. Du redest über die Matrix und ich über den Bildinhalt.
Leider richtet sich ein gutes oder schlechtes Bild immer nach dem Inhaltsergebnis, nicht nach der dahinterliegenden Matrix, die übrigens durch die Differenz der Abtastfrequenz des Sensors bestimmt wird.
Ich müsste also das De-Bayering neu durchführen, wenn die Farbwerte nicht im selben Verhältnis mit verändert werden, weil kein Bezugspunkt aus dem ursprünglichen De-Bayering mehr stimmt.
Aber lassen wir das ... vielleicht schließen sich Hersteller ja Deiner Theorie an und werfen alle Camcorder als 4:4:4 zukünftig auf den Markt.
Bisher hat die Idee aber den Level der Internetblogs noch nicht verlassen.
Daher sag ich immer, das Internet nutzt nur dem, der nicht alles glaubt.
@Roland Schulz
Tja, wenn Dir egal ist, ob gelbe Linien (Beispiel) in Deinem Bild sind, die der Keyer nicht mag und die ja auch nicht so hübsch aussehen und wenn Dir egal ist, was die Kamera an Bild abliefert, dann kann man das natürlich verstehen, dass Du so einen Scheiss glaubst.
Aber Du sagst ja selbst "theoretisch" ... dann brauchst Du ja auch keine Kamera mehr.
Und ist Dir schon mal aufgefallen, das eine 3-Chip was ganz anderes ist ?
Kennst Du den Unterschied überhaupt ?
Die 3-Chip macht (mit dem richtigen Prozessing) sowieso 4:4:4, da kannst du hinterher skalieren, soviel Du willst.
Der Unterschied scheint Dir nicht wirklich klar zu sein.
Antwort von mash_gh4:
Schau einfach mal auf das Kamerabild 4:2:0 denn da sind in Deinem Apfelkorb bereits Orangen drin (gelbe Linien) die Du hinterher auch nicht mehr raus bekommst.
am besten du verkleinerst dein besipielbild genau acht mal -- die letzten beiden male bitte gemäß dem oben beschriebenen prozedere und zeigst mir dann die unterschiede! :)
dann kann ich dir sagen, wie die bilder ursprünglich generiert wurden bzw. welche abweichungen sie vom technischen ideal aufweisen. ich bin mir jedenfalls ziemlich sicher, dass wir beide den unterschied nicht mit freiem auge erkennen werden können.
Antwort von WoWu:
Man kann das natürlich auch soweit verkleinern, dass man Bildinhalte nicht mehr erkennen kann.
Das änder aber nicht daran, das es immernoch ein 4:2:0 ist.
Antwort von mash_gh4:
Das änder aber nicht daran, das es immernoch ein 4:2:0 ist.
nein 4:4:4 ist es auf jeden fall, wenn man es richtig macht!
was man allerdings u.u. trotzdem sehen kann, sind farbfehler an den konturen, die auf unzulänglichkeiten beim debayering zurückzuführen sind -- aber auch das sollte mittlerweile eigentlich eher der vergangenheit angehören.
Antwort von Roland Schulz:
@Roland Schulz
Tja, wenn Dir egal ist, ob gelbe Linien (Beispiel) in Deinem Bild sind, die der Keyer nicht mag und die ja auch nicht so hübsch aussehen und wenn Dir egal ist, was die Kamera an Bild abliefert, dann kann man das natürlich verstehen, dass Du so einen Scheiss glaubst.
Aber Du sagst ja selbst "theoretisch" ... dann brauchst Du ja auch keine Kamera mehr.
Und ist Dir schon mal aufgefallen, das eine 3-Chip was ganz anderes ist ?
Kennst Du den Unterschied überhaupt ?
Die 3-Chip macht (mit dem richtigen Prozessing) sowieso 4:4:4, da kannst du hinterher skalieren, soviel Du willst.
Der Unterschied scheint Dir nicht wirklich klar zu sein.
Er kann"s nicht lassen, ich hatte doch bereits Waffenstillstand angeboten... Warum versuchst Du immer noch mit Schwimmflossen die Niagarafälle hochzukommen??
Ich werde nicht wieder eine Stunde damit verbringen Aufklärungsmaterial zu erstellen um den Blinden das Sehen beizubringen.
Merkst Du eigentlich nicht dass Du dir selbst widersprichst???
Der 3-Chiper tat weh, richtig?! Den hattest Du nicht auf dem Schirm, was?! Da wusste jemand vor Dir das es sowas noch gibt, was es ist, wie"s funktioniert und hat die ganze Argumentation in Null Komma nix erstickt, aufgelöst und vor die Wand gefahren - ...schon wieder ;-)!!!
Aber nen 3-Chipper klammern wir dann aus - weil der unfair und "ganz was anderes ist"? Klappt"s noch?! Niemand hat hier irgendeine Kamera referenziert!
Wenn ich aus ner 8k SD mache und daraus SIF ist das dann immer noch kein 4:4:4??
Was klammerst Du dich immer an irgendwelchen Kameras fest die irgendwas gelbes grünes oder pinkes produzieren? Das interessiert hier überhaupt nicht!! Wieso brauchen wir 70 Pixel um den Pixel in der Mitte zu interpolieren?! Schon mal mitgekriegt dass es u.A. auch verschiedene De-Bayering Algorithmen gibt?!?!
Es geht hier um Skalierung einer Unterabtastung, dafür brauchen wir keine Kamera, schon gar keine von der wir die Qualität nicht kennen aber sofort in Frage stellen!
Immer diese ungewichteten, fadenscheinigen Praxisbezüge. Musst mal lernen Theorie von der Praxis zu trennen wenn die Praxis nicht definiert, unbekannt bzw. "breit" ist! Mal nen technisches Studium abgeschlossen??? Da kommt man "so" nicht weit!!!
Wenn ich irgendwie oder irgendwann mal an diese "ich bin 50 Jahre blind durch die Welt gerannt, aber überzeugt alles gesehen und verstanden zu haben" Memoiren kommen sollte würde ich über den nächsten Schlechtwetter Winter mal Lektor spielen.
Die Korrekturen würden zur Speicherung wahrscheinlich aber ne Jahresproduktion bei Seagate in Anspruch nehmen und bei der Dokumentation aufzeigen, dass selbst ne ORACLE Datenbank FULL WELL erreichen kann!!
Leider bin entweder ich zu doof oder sämtliche Browser meiner verschiedenen Systeme zu sehr am "Standard" angelehnt die zugrundeliegende Webseite zu bedienen, geschweige denn wild überlagerte Inhalte lesbar darzustellen...
Antwort von WoWu:
Hast Du auch Fakten oder nur Polemik.
Weißt Du was ein De-Bayering ist und warum eine 3-Chip Kamera das nicht braucht ?
Ich denke mal, Du weist das nicht, sonst wäre der Schwachsinn nicht gekommen.
Bölck nur weiter, aber Lautstärke ist auch kein Argument sondern ein Zeichen des Mangels an Kenntnis.
@mash
Schade dass die Hersteller Dein Verfahren noch nicht kennen, dann würden wir nur noch 4:4:4 Kameras haben, trotz (oder gerade wegen) zweifacher Unterabtastung und eigentlich ist es ja totaler Blödsinn, dass Hersteller noch 3 oder 4-Chip Kameras herstellen, wenn man 4:4:4 mit einer kleinen Unterabtastung hinbekommt ("wenn man's richtig macht")
Mann, zu blöd, dass die das alle falsch machen.
Zu schade, dass Kamerahersteller keine Internetblogs lesen.
Antwort von Roland Schulz:
Hast Du auch Fakten oder nur Polemik.
Weißt Du was ein De-Bayering ist und warum eine 3-Chip Kamera das nicht braucht ?
Ich denke mal, Du weist das nicht, sonst wäre der Schwachsinn nicht gekommen.
Na das war jetzt aber nochmal ganz schwaches Gepaddel.
Sag mal, warum führe ich die Punkte hier wohl zielführend und unmissverständlich an, weil ich nicht verstehe worums geht?!?!
Mit diesen Deinen obigen Kommentaren säufst Du hier immer weiter ab, scheinste aber nicht zu merken...
Natürlich braucht eine 3-Chip Kamera kein Debayering und natürlich ist die - bei nativer Auflösung (auch NUR dann!!!!) 4:4:4, deshalb habe ich die doch rausgekramt!!!
Jetzt nenne mir aber mal einen Prozentsatz der 3-Chip Kameras welche auch 4:4:4 übergeben oder gar als Camcorder aufzeichnen, der ist aber GANZ WEIT von 100 weg!!! Trotzdem wird bei diesen Cams bei k=2 Downsampling aus deren echtem (End-)4:2:2/0 dann 4:4:4, Dein "16:0:0" Debayering mit 40 notwendigen umgebenden Pixeln bla bla bla trifft nicht zu!! Deshalb hab ich diese "Brechstange" angesetzt!!!
Du sagsts dass ein Downsampling um Faktor 2 (z.B. UHD->FHD) 4:2:0 nicht zu 4:4:4 werden lässt. Wenn Du die Unterabtastung mal halbwegs verstanden hättest wüsstest Du dass das zwingend so ist
Es geht nur darum!!!
Du hast Recht dass eine nativ auflösende Bayer Kamera kaum 4:2:0 schafft und somit auch 4:2:2 bei vielen Cams Quatsch und Marketing ist, aber es geht hier um den Grundsatz (3-Chip auch "Praxis"!!) und der ist so wie von denen die's hier kapieren wie oben nochmals beschrieben!! Niemand hat irgendeine Kamera erwähnt die wir auf das Topic hin überprüfen wollen. Deshalb brachte ich den 3-Chipper, der spielt mir und einigen anderen 100%ig in die Karten!!!
Davon ab, Kameras die bei der Aufnahme bereits ein Oversampling machen und min. 4:2:0 trotz Bayer erreichen können gibt's bereits in der Konsumerklasse (FDR-AX100, a6300, NX1...)!!
Wenn ich bei Themen nur Halbwissen aufweisen kann würde ich das mit etwas weniger Vehemenz verteidigen und diplomatischer "diskutieren", häufig kann man sogar was lernen!
Anders landet man am Ende durch energische Strampelei hochwahrscheinlich (wieder) im Sumpf und "das Volk" pfeifft irgendwann auf die ganzen "Medaillen". Im Leben gibt's immer einen der mehr drauf hat!! Hier läuft mitunter mehr Qualifikation rum als um den Stammtisch in ner Kneipe!!
...manchmal frage ich mich auch ob "man" auf seine alten Tage einfach nur noch provozieren will oder echt keinen Plan hat...
Das war's jetzt - 4:2:0 wird bei Faktor 2 Downsampling (h/v) 4:4:4 - ist's kein 4:4:4 war's kein 4:2:0 - PUNKT
Antwort von Jott:
Wenn das Eis dünn wird, geht's mit Beleidigungen los. Verläßliches Schema! :-)
Antwort von Roland Schulz:
Wenn das Eis dünn wird, geht's mit Beleidigungen los. Verläßliches Schema! :-)
...er hat aber (wieder) angefangen *petz* ;-) ;-) ;-)!!
Ich denke ich stehe recht sicher auf einfachen, soliden und festen Grund(-lagen). Ich lasse mich da recht ungern unqualifiziert angreifen und denunzieren.
Manche kriegen einfach das Ruder nicht rum wenn sie in die falsche Richtung treiben. Irren ist menschlich, das darf man hin und wieder auch gern mal einsehen und zugeben, dafür wird niemand verhauen.
Antwort von Darth Schneider:
Ist schon komisch, viele reden von mehr Schärfe ? Wozu denn ? Was dreht ihr denn was so unglaublich knackig sein muss ? Ich Filme und fotografiere nur mit einer RX 10 Mark1.
Dennoch drehe ich meistens die Schärfe schon vor dem Dreh mal weit runter, weil mir persönlich diese Videobilder eh für die meisten Motive viel zu Scharf sind. ich meine, sogar Kinofilme sind vielfach viel weniger Scharf als das Bild von meiner Fotoknipse, nicht weil die Kinokameras das nicht können, sondern weil es vielfach nicht gut und künstlich aussieht. Genau aus diesem Grund mag ich 4K nur bedingt, es ist Schön und Toll, aber eigentlich viel zu Scharf, was ja gerade bewegte Bilder nervös/unruhig macht. Ob jetzt 4:4:4 oder 4:2:0 gedreht wird ist nur relevant bei komplizierten Greenscreen Aufnahmen oder bei viel Colorcorection, sonst sieht man das nicht. Aber da Keying und simple Colorcorection sogar mit meiner RX 10 bestens klappt, denke ich nicht darüber nach etwas zu ändern, weil die Bilder am Schluss sowiso immer noch mehr als scharf genug sind. Was doch für YouTube genügt weil die meisten Menschen die Filme auf Smartphones, auf Tablets, i Pads, und billigen 4KFernsehern mit lahmem Internet anschauen, und nicht auf 5K Monitoren wo Workstations dran hängen. Für mich klar ist, je mehr ich eine Orginal Filmdatei verändere, je schlechter wird die Qualität. Also wer viel Videodateien konvertiert, der braucht eine teure Kamera, wer wenig konvertiert, der kann sich eine günstige Kamera kaufen und zufrieden sein.
 |
Antwort von beiti:
Dennoch drehe ich meistens die Schärfe schon vor dem Dreh mal weit runter, weil mir persönlich diese Videobilder eh für die meisten Motive viel zu Scharf sind. Genau aus diesem Grund mag ich 4K nur bedingt, es ist Schön und Toll, aber eigentlich viel zu Scharf, was ja gerade bewegte Bilder nervös/unruhig macht. Vorsicht! Jetzt würfelst Du zwei völlig unterschiedliche Sachen durcheinander: Scharfzeichnung und Detailschärfe.
Detailschärfe ist das, was eigentlich zählt - und was man z. B. mit dem Downscale von 4k auf 2k in den meisten Kameras verbessern kann (weil diese Kameras im 2k-Modus aus sensortechnischen Gründen noch nicht die optimale 2k-Detailschärfe liefern können).
Hohe Detailschärfe macht bewegte Bilder nicht unruhig. Sie ist allenfalls unnötig, wenn man sie fürs Motiv nicht braucht und/oder wenn das Wiedergabemedium sie ohnehin wieder verschwimmen lässt. Aber sie macht ein Bild keinesfalls schlechter.
Ein völlig anderes Thema ist die Scharfzeichnung. Das ist eine (heute überall gebräuchliche) Steigerung des subjektiven Schärfeeindrucks durch Verstärken von Kontrastkanten im Bild. Das Bild wirkt dadurch schärfer (unser Auge nimmt hohe Kontraste als Verbesserung der Schärfe wahr), aber es zeigt in Wirklichkeit nicht mehr Details als ohne die Scharfzeichnung.
Mit starker Scharfzeichnung kann man in der Tat viel Unheil anrichten. Es sieht schnell künstlich aus - denn es ist ja auch künstlich. Manche Hersteller schrauben die Scharfzeichnung an ihren Kameras hoch, um mangelnde Detailschärfe zu kompensieren. Laien fällt der Unterschied nicht auf den ersten Blick auf, aber je nach Motiv können die Nachteile dann doch überwiegen.
Ideal ist: Möglichst viel echte Detailschärfe, dafür möglichst wenig künstliche Scharfzeichnung.
PS: Das heißt aber trotzdem nicht, dass das Filmen im 4k-Modus heute immer erste Wahl sein muss. Bekanntlich leiden heutige Kameras im 4k-Modus ja noch an diversen Einschränkungen (geringere Frameraten, geringere Farbtiefe, geringere Farbauflösung), so dass für viele Zwecke der 2k-Modus noch besser ist.
Antwort von Darth Schneider:
An Berti. Danke, für Deine ausführliche Erklärung. Das ergibt durchaus Sinn was du schreibst. Warum habe ich manchmal das Gefühl das bei günstigeren 4K Kameras die Bilder unruhig aussehen und bei anderen (teureren ) Kameras nicht ? Hat das vielleicht mit künstlicher Nachschärfung zu tun, odervieleicht auch mit den zu kleinen Sensoren in Verbindung mit zu vielen Megapixeln ?
Antwort von beiti:
Warum habe ich manchmal das Gefühl das bei günstigeren 4K Kameras die Bilder unruhig aussehen und bei anderen (teureren ) Kameras nicht ? Hat das vielleicht mit künstlicher Nachschärfung zu tun, odervieleicht auch mit den zu kleinen Sensoren in Verbindung mit zu vielen Megapixeln ? Wenn ein bereits rauschiges Bild (wie es bei kleinen Sensoren nicht ungewöhnlich ist) künstlich geschärft wird, wird meist auch das Rauschen mitgeschärft - und das wirkt dann besonders unruhig.
Antwort von Roland Schulz:
...wobei's hier eigentlich darum ging, was mit der Farbunterabtastung bei nem Downscale passiert ;-)...
Antwort von mash_gh4:
Wenn ein bereits rauschiges Bild (wie es bei kleinen Sensoren nicht ungewöhnlich ist) künstlich geschärft wird, wird meist auch das Rauschen mitgeschärft - und das wirkt dann besonders unruhig.
das schärfen ist sehr oft ein notwendiger teil der rauschunterdrückung.
im einfachsten fall werden hier ja bekanntlich einfach nur benachbarte pixel statistisch gemittelt, was aber natürlich einen ausgesprochen unscharfen eindruck hinterlässt, also müssen in einem weiteren schritt die tatsächlich vorhandenen konturen im bild wieder verstärkt werden. wenn das mit einiger umsicht und gut aufeinander abgestimmter einstellungen passiert, kann das allerdings für das resultierende bild durchaus vorteilhaft sein.
ganz grundsätzlich ist es natürlich immer gut, wenn das ausgangsmaterial möglichst viel information und detailwiedergabe enthält. weichzeichnen kann man die bilder nachträglich immer noch, nur leider keine bessere detailwiedergabe aus nicht vorhandenem hineinzaubern...
Antwort von Roland Schulz:
Die Nachschärfung dient primär zur Kompensation des Schärfeverlustes, der durch den häufig vor dem Sensor angebrachte Antialiasingfilter entsteht. Dieser "weicht" den einfallenden Bildinhalt i.d.R. etwas auf, um Aliasingfehler oder Moire zu vermeiden, welches bei Bayer Sensoren technisch bedingt entstehen kann. Mittlerweile wird häufig auf ein Antialiasingfilter verzichtet und es wird versucht, die negativen Effekte durch Softwarealgorithmen zu kompensieren, was in der Praxis mehr oder weniger gut funktioniert.
Antwort von domain:
Schon vor längerer Zeit, als wir all dies ohne übereinstimmendes Ergebnis schon mal diskutierten, sah WoWu bei der Interpolation von benachbarten Pixeln, also bei der "Erfindung" neuer Pixel, dass aus der Mischung der reinen Komplementärfarben Rot und Grün danach Gelb entstehen würde.
Das stimmt meiner Meinung nach nicht, denn es wird nicht additiv sondern subtraktiv interpoliert.
Alles andere wäre ja auch widersinnig, aber er wiederholt es hier erneut.
Kann aber auch sein, dass ich mich irre.
So sieht die subtraktive Farbmischung aus, da gibt es kein Gelb, sondern nur die gegenseitige Aufhebung der Farben ins Grau und damit eine Abdunkelung und keine Anhebung ins additive helle Gelb.
zum Bild
Antwort von cantsin:
Wenn man in Photoshop in 4x4-Pixel-Schachbrett aus 100% roten (RGB 255:0:0) und 100% grünen (RGB 0:255:00) Pixeln erzeugt und das bikubisch runterskaliert auf einen Pixel, resultiert ein olivgrünes Pixel (RGB 153:153:0), siehe angehängte Dateien.
Also stimmt es schon, dass beim Runterskalieren einer Farbkante interpolierte Pseudofarben resultieren, die es im Originalbild nicht gibt.
Antwort von domain:
Das ist klar, weil Grün auch nicht die exakte Komplementärfarbe von Rot ist.
Jedenfalls aber kann bei der Interpolation von Rot und Grün niemals ein helles additives Gelb entstehen, wie es WoWu bis heute behauptet.
Nur eines erscheint mir auch klar, wenn mal solche "erfundenen" Farben (egal welche) entstanden sind, wie will man die wieder wegbringen?
Die müssten ja durch einen sehr gezielten Algorithmus beim Downscaling wieder entfernt werden.
Antwort von Jott:
Was vielleicht hilft, mal zu überlegen: wo sind denn falsche Farben in einer realen 8Bit-UHD-Aufnahme zu sehen? Und wo tauchen welche auf, wenn man das Material in eine reale HD-Timeline wirft? So ganz praktisch, mit den Augen gecheckt.
Antwort von Rudolf Max:
Ein FHD Bild betseht aus 1920 Pixeln horizontal... richtig...?
Ein UHD Bild besteht also aus 3840 Pixeln... richtig...?
Wenn ich nun eine bildgrösse bei FHD von 192cm Breite annehme, immerhin schon knapp 2m, dann ist ein Pixel auf dem Schirm gerade mal 1mm gross...
Bei UHD verdoppelt sich also die Breite auf massive 3,84m, und ein Pixel ist immer noch gerade 1mm klein...
Bei normalem Betrachtungsabstand, den sich jeder für sich selber anhand seiner eigenen Glotze zuhause messen kann, sieht niemand einen einzelnen Pixel. Also mal soviel...
Nun sollen da sogar fremdfarbige Pixel im Bild sein...? Kann ja so sein... bloss, sehen kann dies niemand... also würden solche falschen Pixel auch nicht stören... sofern es dann wirklich geben sollte...
Alles klar...?
Antwort von mash_gh4:
Jedenfalls aber kann bei der Interpolation von Rot und Grün niemals ein helles additives Gelb entstehen, wie es WoWu bis heute behauptet.
ich glaube, man muss bei der ganzen geschichte aufpassen, dass man die wesentlichsten tatsächlichen technischen probleme nicht aus den augen verliert.
es macht nämlich leider einen riesigen unterschied, ob man die betreffenden farben einfach gleich behandelt, wie sich das in der physischen welt draußen verhält, oder aber aber mit tlw. stark davon abweichenden digitalen farbrepräsentation konfrontiert ist. speziell im video-umfeld, mit seinen ganz eigentümlichen historisch gewachsenen bezugssystemen, kommt da leider an den farbgrenz immer wieder etwas ganz anderes heraus als man es gemeinhin erwarten würde.
ich glaube in folgendem artikel aus dem gimp-entwickler-umfeld ist der grund dafür ziemlich anschaulich und gut nachvollziehbar erklärt:
http://ninedegreesbelow.com/photography ... blend.html
aber das ist wieder ein ganz spezielles problem, das mit den hier diskutierten auswirkungen des farbsubsamplings nicht viel zu tun hat.
auch im bezug auf die unschärfen, wie sie durch anti-aliasing-filter tlw. bewusst herbeigeführt werden, spielt das keine rolle, weil es dort eben wirklich noch um bloße physik geht, während es sich bei ähnlich gelagerten bildaufbereitungsschritten an späterer stelle in der verabeitungskette deutlich anders verhält.
was hier aber zur debatte steht, ist im wesentlich 4:2:2 und 4:2:0 farbsubsampling bezogen auf einen rec709/sRGB farbbezugsraum. dort geht's wirklich nur um die tatsache, dass die farbinformation eben immer nur für eine gruppe von 2 bzw. 4 benachbarten pixeln an helligkeitsinformation angegeben wird. wenn man nun aber die entsprechende gruppe von pixeln in der helligkeitsinformation beim skalieren zu einem einzigen pixel zusammenfasst, verfärbt sich dabei natürlich gar nichts!
selbstverständlich muss man es aber richtig machen und die eigenheiten der vorliegenden farbrepräsentation beachten.
trotzdem ist das im grunde ohnehin alles eine ziemlich überflüssige diskussion, weil das meiste davon auf anderen umwegen ganz von selbst passiert, wenn betreffendes material in unseren programmen sachgemäß verarbeitet und abschließend verkleinert wird. man kann es nur in diesen simplifizierenden beschreibungen besser erfassen und nachvollziehen, aber praktisch umgesetzt wird es normalerweise völlig anders.
Antwort von Roland Schulz:
Das ist klar, weil Grün auch nicht die exakte Komplementärfarbe von Rot ist.
Jedenfalls aber kann bei der Interpolation von Rot und Grün niemals ein helles additives Gelb entstehen, wie es WoWu bis heute behauptet.
Nur eines erscheint mir auch klar, wenn mal solche "erfundenen" Farben (egal welche) entstanden sind, wie will man die wieder wegbringen?
Die müssten ja durch einen sehr gezielten Algorithmus beim Downscaling wieder entfernt werden.
Ich bin mit Wolfgang auch nicht immer einer Meinung, aber hier gebe ich ihm "halb" vollkommen Recht.
Rot und Grün ergibt in der additiven Farbmischung GELB!!!
Nehmt in Photoshop den Farbwähler und fahrt Rot und Grün hoch, da kommt gelb bei raus. Das ist eine ganz klassische additive Farbmischung!
Das selbe passiert, wenn ihr eine rote Ebene und eine grüne Ebene übereinanderlegt und als Ebenenmodus "Linear abw. (Add.)", also ADDIEREN wählt.
Aus 255,0,0 Rot und 0,255,0 Grün wird so 255,255,0 , und das ist nunmal Gelb ;-)!!
Im Prinzip müssten die farbigen Pixel/Sensel auf dem Sensor auch übereinander liegen (vgl. Foveon) bzw. in "gleicher Ebene" (3 Chip hinter Prisma) bzw. als RGB RGB nebeneinander mit pro RGB Gruppe angeordnetem Diffusor->Tiefpassfilter, so das jeder Bildpunkt des abzubildenden Bildes immer alle Primärfarben (der additiven Farbmischung) des Sensors trifft. Die resultierende Pixelfarbe ist wieder die Summe der RGB Einzelsignale. Jeder Pixel(-verbund) könnte so alle Farben darstellen - was auch nicht gaaaanz richtig ist, da sich die Farbfilter vor dem Pixel ggf. zwar überlagern aber trotzdem Lücken und Nichtlinearitäten im Spektrum aufweisen.
Die vollständige Erfassung eines Lichtspektrums/Farbe ist nur mit einem Beugungsgitter und einer unendlich hohen Abtastung des Intensitätsverlaufs über die Wellenlänge möglich.
In der einfacheren RGB RGB Darstellung hätte man zudem den Nachteil, am Ende pro Fläche weniger Auflösung bereitzustellen, deshalb das Bayer Pattern in GRGBGRGB...
Auch hier "vermatscht" der Tiefpassfilter in überschaubareren Konstruktionen das einfallende Bild, um möglichst nicht nur einen Sensel, sondern auch umliegende zu treffen und der Bestimmung der eintreffenden Lichtfarbe pro Bildpunkt der Quelle näher zu kommen.
Jetzt gehe ich aber nicht ganz mit Wolfgang dass es an einem Rot/Grün Übergang zwangsweise zu Gelb kommen muss. Das ist sicherlich für überschaubare Algorithmen zum Debayering nicht ganz falsch, muss aber technisch nicht zwingend zutreffen. In der Praxis (ja ja...) sehe ich sowas kaum noch bzw. hängt das ganz klar von der Qualität und der "Intelligenz" des Demosaicing Algorithmus ab.
Auch bei der Farbunterabtastung muss an einem Übergang nicht zwangsweise eine Addition (oder Gelb ;-) ) entstehen. Das ist alles eine Frage der Qualität des Algorithmus, gilt also nicht zwingend.
Das alles hat aber mit dem Downsampling bzgl. der Unterabtastung relativ wenig zu tun.
Antwort von Roland Schulz:
...trotzdem ist das im grunde ohnehin alles eine ziemlich überflüssige diskussion, weil das meiste davon auf anderen umwegen ganz von selbst passiert, wenn betreffendes material in unseren programmen sachgemäß verarbeitet und abschließend verkleinert wird. man kann es nur in diesen simplifizierenden beschreibungen besser erfassen und nachvollziehen, aber praktisch umgesetzt wird es normalerweise völlig anders.
Richtig: ES ist im Grunde relativ überflüssig!!!! +10 ;-)
Wir hätten in verschiedenen Nachbearbeitungsszenarien vielleicht den ein oder anderen Vorteil, nur die kann ich mir wie Wolfgang immer so schön anführt auch tatsächlich nur auf Basis von Bildern einer Kamera vorstellen. Da haben wir aber gelernt dass es verschiedene Faktoren gibt, warum eine Kamera seltenst echtes 4:2:2 oder auch nur 4:2:0 schafft, geschweige denn "4:n:n" (Ausreizen der Auflösung bzgl. Systemgrenze).
Selbst wenn wir jetzt eine Quelle hätten die 4:2:2/0 -> "echtem" 4:4:4 Downscale wirklich schafft (Einblendung toller Grafiken, Tabellen oder farbiger Text oder was weiß ich) und auch das NLE und der Codec das am Ende unterstützt (da wird"s auch schon recht dünn), Hand auf"s Herz, wer von uns hier kann 4:4:4 "Video" auf nem Endgerät darstellen??
Bei der Bildbearbeitung (Fotografie) sieht das dagegen schon anders aus, da kann nen TIF wirklich "4:4:4" sein und auch dargestellt werden, besonders nach Downscale eines Bayer Bildes oder z.B. einer Hasselblad "Multishoot".
Die Theorie wie von Dir im letzten Post noch mal beschrieben leistet aber 4:2:2/0 -> 4:4:4 im Downscale, definitiv!!
Warum das in der Praxis scheitert liegt an "Fehlern" bzw. Vereinfachungen der Geräte, nicht der zugrundeliegenden Theorie oder Technik.
Antwort von cantsin:
Nun sollen da sogar fremdfarbige Pixel im Bild sein...? Kann ja so sein... bloss, sehen kann dies niemand... also würden solche falschen Pixel auch nicht stören... sofern es dann wirklich geben sollte...
Alles klar...?
Nein, denn die Empfehlung, 4K auf 2K runterzuskalieren und dadurch (vermeintlich) Farbtiefe zu gewinnen, richtet sich ja i.d.R. an Leute, die Colorgrading oder Keying machen wollen.
Mein Beispiel mit dem Falschfarbsaum, der entsteht, wenn man ein 8bit-4K-Bild mit harter Rot-Grün-Kante auf 2K runterskaliert, würde ja gerade dazu führen, dass man sich den Greenscreen-Key versaut.
Antwort von WoWu:
Ihr seid ja immer noch dabei ....
Ich hab jedenfalls erst mal das Wochenende genossen.
Das alles hat aber mit dem Downsampling bzgl. der Unterabtastung relativ wenig zu tun.
Da bin ich nicht Deiner Meinung, denn gerade um das Rückgängigmachen der Unterabtastung von 4:2:0 nach 4:4:4 war das Thema.
mash_gh4"s Behauptung war ... man kann aus 4:2:0 wieder 4:4:4 machen, weil die Energieverteilung in YCbCr (nicht YUV) so gestaltet ist, dass aus den Paters eine verlustlose Rückrechnung erfolgen kann.
Mein Standpunkt war, dass keine verlustlose Rückrechnung erfolgen kann.
Das war der Punkt, zuzüglich noch de Umstands, dass durch die Unterabtastung das Bild bereits mit Artefakten belastet worden ist.
Nun gibt es dazu eine Reihe wissenschaftlicher Arbeiten, die sich mit dem Thema beschäftigen, allerdings "lediglich" mit der Vorgabe, aus einem 4:4:4 Bild, dass eine 4:2:0 Unterabtastung durchläuft, wieder ein 4:4:4 Bild zu generieren, also von einem Bild, dessen YCbCr die entsprechende Komponentenenergie enthält.
Ausgangsmaterial, das bereits vom Sensor unterabgetastet ist, erfüllt die Bedingungen ohnehin nicht.
Aber selbst die gemachten Versuche führten über unterschiedliche Methoden nur zu Ergebnissen von 20-70% der ursprünglichen Componenen.
Einer 4:2:0 Interpolation liegt eine lineare 7-Tap-FIR-Filter Operation zugrunde, die Unschärfen und Farbartefakte über die Kanten und Details mit sich bringt.
Die Idee, ist es, die Interpolation durch adaptive Filterung zu verbessern.
Das heisst, die Korrelation zwischen Luminanz- und Chrominanz-Kanäle unabhängig von der Farbdarstellung zu verbessern.
Diese Korrelation kann die Interpolation von niedrig aufgelösten Chrominanzwerten, unter Verwendung von Detailinformationen aus der Luminanzkomponente in höherer Auflösung extrahiert zu unterstützen genutzt werden.
Das heisst, den signifikanten Verlust von Hochfrequenzdaten im Downsampling nachfolgenden signifikant durch die Verwendung von Algorithmen zu verringert.
Das war auch die Grundidee von mach_gh4.
Die Bilddaten Rekonstruktion erfordert upsampling der Chrominanz-Komponenten zum 4: 4: 4-Auflösung vor Umwandlung in den RGB-Farbraum.
Der Prozess der Unterabtastungs beinhaltet gewöhnlich linear Antialiasing Vorfilterung, durch ein entsprechendes Tiefpaß-FIR-Filter.
In ähnlicher Weise wird der Prozess des Wiederaufbaus auf der Grundlage der FIR-Filter als Interpolator verwendet.
Während Dämpfung von Aliasing-Komponenten bietet, stellt Tiefpaßfilterung Farbartefakte in Form von Unschärfen und ringing.
Solche Effekte sind nicht besonders störend in natürlichen Szene und glatten Inhalten, sind aber sichtbar bei scharfen Kanten und Bilder mit künstlichen Inhalt (Computergrafik) und sorgen dafür, dass Key-Verfahren nicht einwandfrei funktionieren.
Es gibt zahlreiche Versuche in der Literatur die Qualität von Bildern nach Chrominanz subsampling zu verbessern.
Dumitras und Kossentini haben einen alternativen Ansatz zur Unterabtastung zur Herstellung nichtlinearen Operators basierend auf neuronalen Vorwärtsnetzes entworfen.
Eine neuronales-Netzwerk-Technik mit adaptivem Lernen ​​wurde auch von
Qiu und Schaefer zur Rekonstruion regelmäßig unterabgetastete Chrominanz-Komponenten eingesetzt.
Dieser zweite Ansatz nutzt eine binäre Kanteninformationen aus Luminanz extrahiert, um das neuronale Netz zu führen, das zuvor trainiert wurde, natürlicher Szene zu interpolieren.
Anstelle einer komplexen neuronalen Netzwerkverarbeitung, verwenden Wissenschaftler der "Poznan University of Technology" eine sehr einfache lineare Interpolation anhand von 4 am nearest Samples mit adaptiver Einstellung der jeweiligen Gewichtungen.
Adaptives Filtern ermöglicht, zumindest teilweise die fehlenden Hochfrequenzinhalt zu rekonstruieren, die im Unterabtastungsprozess verloren gegangen sind, wodurch die Herstellung weniger verzerrt und Schärfe dazugewonnen wird.
Hierbei handelt es sich um Bild-Enhancement, nicht aber um die Rekonstruktion eines ursprünglichen Bildes.
Es werden also nicht die ursprünglich verloren gegangenen Werte rekonstruiert sondern neue Werte geschätzt, von denen man annimmt, dass sie den ursprünglichen Werten ähneln und einen schärferen Bildeindruck im Chrombereich vermitteln.
Sie greifen dabei auf Studien von Pirsch und Stenger über das "Statistical analysis and coding of colour video Signals" , Limb und Rubinstein, und Wan und Kuo zurück.
Diese Arbeiten deuten darauf hin, dass es eine starke Korrelation zwischen den Farbkomponenten, vor allem in der nicht RGB-Umgebung gibt, wie beispielsweise YCBCR, die eine bedeutende Energieverdichtung gegenüber RGB bietet.
Mit anderen Worten, der Großteil der Signalenergie liegt in der Luminanzkomponente, während die Chrominanz-Komponenten durch schmale Bandbreite begrenzt sind.
Abel, Bhaskaran und Lee berechnet in ihrer Ausarbeitung "Colour image cod- ing using an orthogonal decomposition" die Kreuzkorrelation zwischen Luminanz und Chrominanz-Komponenten und kommen eben zu diesem Schluss, dass eine signifikante Energieverdichtung im Vergleich zu RGB, in der Luminanz-Chrominanz-Darstellung eine noch starke Korrelation zwischen den Komponenten besteht.
Die Untersuchung der statistischen Abhängigkeiten zwischen Luminanz- und Chrominanzkomponenten zeigen, dass die Abhängigkeit erster Ordnung nicht sonderlich von einer RGB-Farbraum-Transformation + Chrominanz auf Helligkeit, abweicht.
Er belegt das in seiner Studie mit den Histogrammen und gibt die Verbesserung gegenüber der Unterabtastung mit 20% - 70% an da die Werte unterschiedlich stark korreliert sind.
Keine der Studien stellt eine funktionierend Reproduktion eines 4:2:0 Bildes zu 4:4:4 in Aussicht.
Alle Methoden basieren auf Enhancementalgorithmen, also einer Bildnachbearbeitung und Schätzung der Werte.
Dabei werden teilweise auch "unechte" Werte, die erst durch die Unterabtastung entstanden sind, nicht beseitigt, sondern als Vorgabewerte weiter verarbeitet. (berühmte "gelbe" Linie, dessen Farbe schnurz egal ist, @domin)
Weil Bilder instationären Signale sind und die Korrelation zwischen ihren Farbkomponenten ieher eine lokale Eigenschaft als eine globale Eigenschaft sind, ist linear Entkorrelation durch eine statischen (nicht-adaptiven) Farbraum -Transformation, nicht in der Lage alle statistischen Abhängigkeiten zwischen den Komponenten zu entfernen.
Experimentelle Überprüfung der vorgeschlagenen Interpolationsmethode ermöglicht seine Leistung zu herkömmlichen Interpolation unter Verwendung von Standard-FIR-Filter zu vergleichen.
Für die Zwecke dieses Tests wurden mehrere Farbbilder von RGB 4:4:4 umgewandelt nach YCBCR das so die volle 4: 4: 4-Auflösung enthielt und anschließend unterabgetastet auf 4: 2: 0 Auflösung.
Die unterabgetasteten Bilder wurden getrennt interpoliert zurück nach 4: 4: 4, die vorgeschlagene adaptive Interpolation und Standard-lineare Interpolation mit FIR-Filter.
Diese rekonstruierten Bilder wurden mit dem ursprünglichen 4: 4: 4 Bild verglichen.
Die Interpolationstechnik verursachte Rekonstruktionsfehler von 33,6 bis 43,7 db.
Die Leuchtdichte in den Bildern war konstant und gleich, während die Farbsättigung größe lokale Fehler aufwies.
Mit andern Worten ... es geht nicht und wenn sich überhaupt eine Verbesserung einstellt, dann nur mit Softwareaufwand, der ganz sicher nicht in jedem x-beliebigen NLE steckt und wenn, dann auch nur, wenn die Kamera bereits 4:4:4 raus tut.
Wer die Aufsätze nachlesen will ... ich suche gern die Links raus, lassen sich aber auch easy googeln.
Antwort von mash_gh4:
ist dir aufgefallen, dass in deinem ganzen langen langen beitrag der umstand der 4k->1080p skalierung konsequenzen ausgeklammert, ignoriert oder übersehen wurde?
Antwort von WoWu:
Für' Verfahren völlig irrelevant.
Antwort von mash_gh4:
Für' Verfahren völlig irrelevant.
ja -- so kann man das natürlich auch sehen...
hat halt dann mit der restlichen diskussion hier nicht mehr viel zu tun.
Antwort von WoWu:
Es würde die Sache nur erschweren, weil alle Korellationen zusätzlich neu hergestellt werden müssten.
Und es funktioniert schon bei einem einfachen Bild nicht (444-420-444)
Das ist das Verfahren, das nur 20-70% und auch nicht Rekonstruktion sondern Enhancement bring.
Also selbst unter der Annahme, 4K würde das ursprüngliche 444 Bild ersetzen, funktioniert es nicht. (mal von den spatialen Problemen ganz abgesehen).
Aber das hatte ich in einem früheren Posting schon angerissen.
Antwort von HJS:
hallo WoWu,
ich habe dich bisher als ein kompetentes Forenmitglied angesehen.
Dein obigen Artikel erzeugt bei mir den Eindruck, als wolltest du mit einem Redeschwall von scheinbar wissenschaftlichen Gehalt alle anderen zum Schweigen bringen und ihnen deine Meinung aufzwingen??
Das verstehe ich nicht. Du bist sonst doch sachlich!
Gruß Jürgen
Antwort von WoWu:
Dabei ist das schon die kürzeste Form, ein solches Verfahren, das mach gh4 ja nur nibulös in seinem Posting angesprochen hat, mal zu substantiieren und darzulegen, dass es nicht funktioniert und warum es nicht funktioniert.
Undzwar nicht auf der Basis eigener Bildbetrachtung, sondern auf der Basis einiger universitärer Ausarbeitungen.
Anders kämen wir hier sowieso nicht weiter ...
Oder hättest Du neue (sachbezogene) Erkenntnisse, die uns hier weiter helfen würden ?
Antwort von Roland Schulz:
ist dir aufgefallen, dass in deinem ganzen langen langen beitrag der umstand der 4k->1080p skalierung konsequenzen ausgeklammert, ignoriert oder übersehen wurde?
mash_gh4: +100.000 ;-) ;-) ;-) !!!!!!!!!
Richtig, NIEMAND hat behauptet dass wir aus 4K 4:2:0 -> 4K 4:4:4 machen wollten, das GEHT auch NICHT!!!!
Wir wollen aus 4:2:0 durch min. Faktor 2 Downsampling 4:4:4 machen, und das ist ganz einfach und richtig und 100%ig!!
Was bedeutet 4:2:0 bzw. 4:4:4 eigentlich, glaube das scheint hier noch nicht so ganz klar zu sein.
Die abgetasteten 2x2 Pixelblöcke, welche 4 Helligkeitsinformationen beinhalten und 1 Farbinformation beinhalten (4:2:0) fassen wir zu einem 1x1 Block / 1 Pixel zusammen, welcher nur noch 1 gemittelte Helligkeitinformation und DIE Farbinformation beinhaltet. Damit hat jeder downgesampelte Pixel eine individuelle Farbinformation -> so einfach ist das ;-)!!
Davor ging hier aber noch mal bei cantsin was schief, dazu später...
Antwort von Roland Schulz:
Nun sollen da sogar fremdfarbige Pixel im Bild sein...? Kann ja so sein... bloss, sehen kann dies niemand... also würden solche falschen Pixel auch nicht stören... sofern es dann wirklich geben sollte...
Alles klar...?
Nein, denn die Empfehlung, 4K auf 2K runterzuskalieren und dadurch (vermeintlich) Farbtiefe zu gewinnen, richtet sich ja i.d.R. an Leute, die Colorgrading oder Keying machen wollen.
Mein Beispiel mit dem Falschfarbsaum, der entsteht, wenn man ein 8bit-4K-Bild mit harter Rot-Grün-Kante auf 2K runterskaliert, würde ja gerade dazu führen, dass man sich den Greenscreen-Key versaut.
Leider nicht ganz: wir gewinnen überhaupt keine "Farbtiefe"! Was meinst Du damit, die Quantisierung, also statt 8bit 10bit?? Das passiert NICHT!!
Es bringt demnach nichts für Colorgrader.
Für Keyer bringt es auch nichts, es sei denn der Keyer (Plugin) kann kein 4k sondern nur 2k und dann in 4:4:4, dann ja!
Das Downscaling bringt am Ende ÜBERHAUPT nichts, da keine Informationen dazugefügt werden sondern eher vernichtet werden, und das sind Helligkeitsinformationen, von denen nur noch 25% übrig bleiben (bei 4:2:2 am Eingang bleiben auch nur noch 50% der Farbinformationen übrig).
Was richtig ist, dass nach dem Downscale einer 4K Datei eine 2K Datei mit 4:4:4 Farbinformationen übrig bleibt. Wenn man also nur 2k weiterverarbeiten kann könnte das ein Vorteil sein, ansonsten NICHT! Die ursprüngliche Datei kann nicht "verbessert" werden!
Bezogen auf die 2K Datei hätte man bei 4:4:4 gegenüber 4:2:0 eine höhere Chrominanzauflösung, es können mehr farbige Details abgebildet werden. Solange wir 4K verwenden können bringt das aber keinen Vorteil!
Antwort von Roland Schulz:
Wolfgang, diese "Dissertation" oben haben vielleicht >50% hier nicht verstanden oder haben wie ich einfach aufgehört weiterzulesen - weil"s wie mash_gh4 beschrieben hat einfach am Topic vorbei geht und einfache Grundlagen nicht umwerfen wird.
Es geht NUR um die Farbauflösung einer 2K Datei, die aus einem Downscale einer 4K Datei (4:2:2 oder 4:2:0) entstanden ist.
(TOPIC: 4k -> 1080 444? FHD/1080<->2K etc. lassen wir mal außen vor...)
Die downgescalte Datei hat 4:4:4.
Das liegt doch ganz einfach darin begründet, dass in der 4K 4:2:0 Datei 2x2 (h/v) Pixel angeordnet sind und jeder Pixel eine Helligkeitsinformation und der gemeinsame Block eine Farbinformation enthält (4:2:0).
Wenn wir die 2x2 Pixel jetzt im Downscale auf 1x1 also 1 Pixel reduzieren/zusammenfassen, wie auch immer, dann bleibt eine gemittelte Helligkeitsinformation und DIE eine Farbinformation übrig.
Jeder downscaled 2K Pixel hat damit eine aus 4 Pixeln gemittelte Helligkeitsinformation und eine individuelle Farbinformation (ich wiederhole mich...).
DAS entspricht dann 4:4:4!
Ganz ehrlich, falsch verstanden oder "einfach dagegen"?!?!
Ist es so schwer einfach mal das Ruder rumzureissen und zuzugeben - Ok, so ist es, vielleicht habe ich mich geirrt oder es falsch verstanden?!?!
Keine Ahnung wem hier wie viel an seinem "Ruf" liegt, aber irgendwo ist der Punkt erreicht wo man sich vielleicht den eigenen Ast absägt.
Antwort von Jott:
Wusste gar nicht, dass das Thema so weite Kreise zieht, inclusiv international agierendem Roland Schulz:
http://www.hdwarrior.co.uk/2015/10/08/w ... rry-green/
http://www.provideocoalition.com/can-4k ... it-matter/
Sehr schön!
Antwort von domain:
Verstehe größtenteils nur mehr Bahnhof, aber emotional gesehen bleibt es spannend ;-)
444 muss eine magische Größe sein.
Ist denn 4:4:4 ein ganz eigenes und unheimlich anzustrebendes Ziel?
Soweit ich das bisher verstanden habe, wird ein abgeleitetes 2K 444 Keying nicht besser, als wenn ich es gleich in 4K mit 4:2:2 gemacht hätte und erst danach auf 2K skaliere.
Gibt es denn außer diesem Spezialfall noch andere Fälle, wo 444 einen eklatanten und vor allem sichtbaren Vorteil bringen kann?
Ich meine, der Physiologie des Auges entsprechend, ist u.a. die Farbreduktion doch eine sehr sinnvolle Sache zur Datenreduktion, genauso wie die Verdichtung in mp3-Files, die ja auch erst nach langwierigen psychoakkustischen Experimenten und Hörproben entstanden ist, mit dem Ziel, nur für den Menschen wahnehmbare Signalanteile zu speichern.
Antwort von Roland Schulz:
@Jott: Richtig ;-)!!! ...hatte ich bereits erwähnt aber nicht referenziert.
Das "White Paper" welches Panasonic dazu veröffentlicht hat ist ebenfalls "klasse" - na ja, Barry Green hatte ich danach irgendwo bei DVINFO.net o.ä. noch "aufgeklärt", danach war dann auch dort Ruhe ;-).
Hier ging's aber nur um die 10bit Nummer die Quatsch ist...
Antwort von HJS:
Hier ging's aber nur um die 10bit Nummer die Quatsch ist...
bezüglich des Chromathemas sind sich offensichtlich einige einig (ich gehöre dazu) dass aus UHD 4:2:0 dann HD 4:4:4 entsteht, wenn der Algorithmus es richtig macht.
Was meinst du in obigem Zitat? Bist du der Meinung, dass man 10 Bit bekommt oder nicht ?
Ich sehe das so:
Ein 8-Bit Lumawert hat bekanntlich den Wertebereich von 0...255. Addiert man nun 4 solcher Werte zusammen (zur Mittelwertbildung), ergibt sich für die Summe ein Wertebereich von 0...1020. Das entspricht einem Wert mit einer "10 Bit" Auflösung. Zumindest dann, wenn aus de Algorithmus keine Wortlängenbegrenzung resultiert.
In den verlinkten Zitaten wird das auch so gesehen.
Gruß Jürgen
Antwort von mash_gh4:
444 muss eine magische Größe sein.
Ist denn 4:4:4 ein ganz eigenes und unheimlich anzustrebendes Ziel?
das ist für mich der eigentlich springende punkt an der ganzen geschichte. ich galub, dass es wirklich wichtig ist, dass man versteht, was die entsprechenden angaben wirklich bedeuten und welche praktische auswirkung das wirklich für das arbeiten und die resultierenden bilder hat.
wenn ich hier leute regelmäßig behaupten, dass 4:2:0 einfach als k.o. kriterum für irgendwelche kameras zu verstehen ist, und 4:2:2 um welten besser sei, kann ich darüber wirklich nur den kopf schütteln...
ich persönlich sehe es für mich einfach so, dass die meisten heutigen 4k kameras mit ihren entsprechenden komprimierungs- und farbsubsample-vorgaben, eben nur für die 1080p produktion wirklich gute ausgangsvoraussetzungen bieten. dort aber sind sie dann wirklich gut.
und 4:4:4 würde ich auch nicht so sehr als irgendein höheres mystisches ziel verstehen, sondern vielmehr einfach nur als jene weise, wie pixel in heutigen programmen normalerweise gehandhabt wird bzw. allen entsprechenden berechnungen zu grunde liegt. all die videospezifischen eigenheiten und übertragungsoptimierten auflösungsreduktionen, bleiben da gewöhnlich außen vor. deshalb ist es schon wichtig, diesen maß als tatsächlich relevante größe und anhaltspunk zu verstehen.
Hier ging's aber nur um die 10bit Nummer die Quatsch ist...
Was meinst du in obigem Zitat? Bist du der Meinung, dass man 10 Bit bekommt oder nicht ?
ich bin eigentlich auch in der 10bit frage geneigt, dem ganzen eine gewisse berechtigung zu zusprechen.
schau dir einmal folgendes bsp.an:
gegeben sind vier benachbarte pixel die einen ausschnitt aus einem schräg von links unten nach rechts oben heller werdenden farbverlauf wiedergeben und auf ein viertel der größe skaliert werden.
10bit werte: 8bit werte:
+-----+-----+ +-----+-----+
| 509 | 512 | | 127 | 128 |
+-----+-----+ +-----+-----+
| 507 | 509 | | 127 | 127 |
+-----+-----+ +-----+-----+
artithmetisches mittel:
509.25 127.25
mittel gerundet auf die ursprüngliche auflösung:
+-----+ +-----+
| 509 | | 127 |
+-----+ +-----+
mittel gerundet auf 10bit darstellung:
+-----+ +-----+
| 509 | | 509 |
+-----+ +-----+
nicht 508(!)
ich hab zwar zum glück gleich im ersten schuljahr in einer technischen ausbildung von unserem damaligen physiklehrer eingebläut bekommen, dass man nicht einfach die wundersam langen zahlenketten hinter dem komma blindlings vom taschenrechner abschreiben sollte, sondern vielmehr immer auch die tatsächliche genauigkeit der ursprünglichen angaben im auge behalten muss, trotzdem scheint es mir in diesem fall zulässig zu sein, die entsprechende höhere statistische auflösung einzubeziehen.
wenn man davon ausgeht, dass die daten ursprünglich vom sensor bzw. dem dahinter angesiedelten AD-wandler zumindest in 12 od. 14bit auflösung hereinkommen, irgendwo aber an klaren grenze auf 8bit gerundet werden müssen und zusätzlich auch noch durch das im bild enthaltene rauschen gedithert sind, macht es in meinen augen schon sinn, diesem rechnerischen auflösungsgewinn beim skalieren tatsächliche eine gewisse signifikanz zuzuschreiben.
Antwort von WoWu:
Filter und Korellationen spielen bei Euch gar keine Rolle ?
Schade, dass die Kameras vollgepackt sind mit Filteralgorithmen, um allen möglichen Artefacten entgegen zu wirken.
Antwort von mash_gh4:
Filter und Korellationen spielen bei Euch gar keine Rolle ?
doch, genau solche umstände würde ich in der praxis auch einbeziehen.
im konkreten fall sind es allerdings in der praxis viel weniger irgendwelche filter, kameraeigenheiten oder deutlich auzsgefeilteren skalierungstechniken, sondern vielmehr die tatsache, dass uns die entsprechenden daten nach der kompression gar nicht mehr in solch isoliert voneinander zu bertrachtenden pixeln zur verfügung stehen. womit wir also in der praxis viel eher konfrontiert sind, sind irgendwelche ganz einfachen werteverläufe innerhalb eines makroblocks. trotzdem ändert das nichts daran, dass es nicht sehr zielführend ist, sich bei der berechnungsgenauigkeit oder der interpretation des resultats starr an der ursprünglichen auflösung zu orientieren! wie fatal sich das auswirkt, kennen wir ohnehin alle von
schlechten videobearbeitungsprogrammen, die intern tatsächlich nur mit 8bit auflösung hantieren. mittlerweile sollte das zum glück nicht mehr so oft anzutreffen sein, trotzdem schadet es natürlich nicht, hin und wieder einmal hervorzuheben, warum das so bedeutsam ist.
Antwort von Roland Schulz:
8bit wird 10bit durch Downscaling ist Quatsch - warum?!
Nehmen wir mal an wir wollten eine "Fläche" mit genau 1/3 der maximalen Intensität, also 33,3 Periode einmal mit 8bit und einmal mit 10bit abbilden.
Das funktioniert tatsächlich EXAKT!
In oder neben dieser Fläche kann in 10bit der nächsthöhere Wert 33,4311%, daneben der nächsthöhere Wert 33,5288% und daneben der Wert 33,6266% abgebildet werden. Das Inkrement bzw. der Wert der einem LSB entspricht lautet nämlich 100/1023 = 0,0977~.
Die 33,3 Periode Fläche kann auch durch Abbildung in 8bit exakt erzielt werden. Die nächst intensivere Fläche würde allerdings schon den Wert 33,7255% besitzen, die danach 34,1176%, da das Inkrement bzw. der Wert für ein LSB 100/255 = 0,3922~ beträgt.
Die 8bit Abbildung kann also niemals die "feine" (Zwischen-)Informationen einer 10bit Abbildung gespeichert haben. Der "Quantisierungsfehler", also die Differenz des diskret abzubildenden Wertes vom tatsächlichen Wert kann bei einer 8bit Abbildung bis zu <4 mal größer sein als bei einer 10bit Abbildung. Die 8bit Abbildung enthält keine Informationen darüber, wie genau oder groß der tatsächliche oder der 10bit Wert gewesen wäre.
Bei homogenen Flächen (oder auch bei "langsamen" Veränderungen) macht die Interpolation durch Downscaling (Barry Green) auch keinen Sinn, da alle umgebenden Pixel innerhalb der Fläche den gleichen Wert besitzen. Die beschriebene Interpolation bzw. Mittelwertsbildung nach Barry Green kann zwar Werte mit einer feineren Abstufung als 8bit mitteln, das hat aber nichts mit dem Wert zu tun der urspünglich mal in 10bit hätte abgebildet/erfasst werden können.
Ein idealer 8bit Intensitätsverlauf (z.B. Grauverlauf) mit flachem Anstieg (Veränderung der Intensität << 2x2 Pixel) wird durch das Downscaling nicht die feinere Abstufung eines 10bit Verlaufs erleben. Der Quantisierungsfehler bezogen auf die ursprüngliche Quelle kann größer als Faktor 4 im Vergleich zu einer Erfassung mit 10bit werden, da der 10bit Wert bis auf vier Ausnahmen (n * 33,3 Periode % ) noch nicht einmal exakt getroffen werden kann.
Da wo uns 10bit in der Praxis was bringt, bei der Erfassung von "langsamen" oder "weichen" Verläufen und anschließendem "Grading", bringt das Downscaling mit 8bit auf 10bit Transformation der Quelle folglich nichts.
Auch der theoretisch mögliche, größere Signal/Rauschabstand von 10bit wird nicht erreicht, da die Amplitude bereits durch das 8bit Signal definiert wird. Das 10bit Signal kann einen bis zu Faktor <4 besseren Signalrauschabstand darstellen, was insbesondere beim "Bitkippen" (Schwelle zwischen 2 Inkrementen) wahrnehmbar wird. Durch den Verlauf der Übertragungsfunktion der meisten gängigen Gammakurven (flacher in den Tiefen) wird das Rauschen und Posterizing/Abreissen bei 8bit somit besonders in den dunklen Bereichen größer.
Statistisch gesehen wird das Rauschen durch die 2x2 Pixel Mittelung "gemittelt" und damit ggf. tatsächlich kleiner, ist aber nicht beweisbar auf dem Niveau, welches eine 10bit Darstellung erreichen kann.
Antwort von Roland Schulz:
Filter und Korellationen spielen bei Euch gar keine Rolle ?
Schade, dass die Kameras vollgepackt sind mit Filteralgorithmen, um allen möglichen Artefacten entgegen zu wirken.
Wolfgang, es ist vorbei! Gib"s doch endlich einfach zu, das tut nicht weh ;-)!! 4:2:0 wird im Downscale zu 4:4:4, es wird in diesem Leben nicht mehr unwahr!!
Darfst auch mal dämlicher Trottel zu mir sagen ;-)!!
Lass" uns mal nen virtuelles Bier trinken, real ist mir ein bisschen zu weit...!
Antwort von WoWu:
So ein Blödsinn, was soll ich zugeben ?
Es gelingt weder Euch, noch den beschrienen Universitäten, aus einem 4:2:0 Signal wieder ein 4:4:4 zu machen.
Bisher hat es von Euch da auch, bis auf irgendwelche Behauptungen keine Belege gegeben, die sich an der Wirklichkeit orientieren.
Ihr legt einfach zwei Matritzen aufeinander, mitteilt irgendwas und behauptet, jetzt sei es 4:4:4.
Dabei stehen schon die Pixelwerte in einem Zusammenhang zueinander, der mit berücksichtigt werden muss, aber die Realität scheint Euch nicht zu interessieren.
Das widerspricht übrigens auch nicht nur meiner Meinung, sondern offenbar auch derer von Leuten die sich da ausgiebig mit beschäftigt haben und auf deren Grundlage Dissertationen oder zumindest fundierte wissenschaftliche Aufsätze entstanden sind.
Da hilft auch kein provokantes ... "gib es doch zu".
Damit werden Deine falschen Behauptungen auch nicht richtig, Du versuchst damit nur diesen Eindruck zu erwecken.
Dabei ist es einfach Quatsch, den ihr da aus den unterschiedlichen Blogs entnommen habt.
Aber ... gut gebrüllt Löwe...
wahrscheinlich gibt es hier auch einige, die den Quatsch glauben.
Antwort von HJS:
hallo mash_gh4
ich habe jetzt deine Argumentation verstanden und finde, dein beispiel erläutert den sachverhalt richtig
Filter und Korellationen spielen bei Euch gar keine Rolle ?
Schade, dass die Kameras vollgepackt sind mit Filteralgorithmen, um allen möglichen Artefacten entgegen zu wirken.
doch, natürlich. Ich würde auch nicht sagen, dass man prinzipiell immer aus den vier 8-Bit Werten einen neuen 10-Bit Wert bekommt. Man kann ein Beispiel überlegen, wo das definitiv nicht geht.
Die Downsampling-Filteralgorithmen werden vermutlich meistens auch bessere Filter sein, als nur ein profanes Mittelwertfilter. Wie sich das dann auf das Thema hier auswirkt, lässt sich nicht pauschal sagen.
Auch dein Stichwort "wie sind die benachbarten Werte korreliert" ist interessant, weil der Mittelwert benachbarter Rauschwerte sich natürlich anders verhält als Bildszenen. Die sind allerdings im Allgemeinen stark korreliert, was der Argumentation hier hilft.
Ich glaube, dass es einen Auflösungsgewinn gibt, der aber abhängig ist von der Szene bzw. der Detailszene. Der Gewinn kann maximal 2 Bit sein im Allgemeinen eher etwas weniger.
Gruß Jürgen
Antwort von WoWu:
ich habe jetzt deine Argumentation verstanden und finde, dein beispiel erläutert den sachverhalt richtig
Ich nicht ...
Wenn Du im Videobild z.B. einen Übergang von Schwarz auf Weiss hast, also 0 und 255, dann bekommst Du im 10 Bit Signal da plötzlich einen interpolierten grauen Wert, der im Originalbild überhaupt nicht vorhanden war.
Du hast zwar in 10 Bit dann den Platz, so einen falschen Wert einzubetten, aber Du baust Dir da einen Fehler ins Bild ein.
Solche Sachen kann man mit Computergrafik machen, die ständig neu gerendert und dargestellt wird, aber nicht mit effektiven Werten,
Das ist nämlich genau die Methode, wie die ganzen "smoother" funktionieren.
Es sieht alles weicher aus, reproduziert aber keinen einzigen echten Wert, der in der Szene vorhanden war.
Antwort von mash_gh4:
Wenn Du im Videobild z.B. einen Übergang von Schwarz auf Weiss hast, also 0 und 255, dann bekommst Du im 10 Bit Signal da plötzlich einen interpolierten grauen Wert, der im Originalbild überhaupt nicht vorhanden war.
Du hast zwar in 10 Bit dann den Platz, so einen falschen Wert einzubetten, aber Du baust Dir da einen Fehler ins Bild ein.
Solche Sachen kann man mit Computergrafik machen, die ständig neu gerendert und dargestellt wird, aber nicht mit effektiven Werten.
ich würde behaupten, dass der großteil der zeitgemäßen videoverarbeitungsprogramme mit shadern arbeitet, damit man die einzelnen pixeln nicht in einer großen schleife abarbeiten muss, sondern die berechnungen für die jeweils gewünschten koordinaten auf ganz vielen recheneinheiten der GPU parallel abarbeiten kann. abweichungen auf grund der berechnungsgenauigkeit gibt es dabei mehr als genug, aber zumindest nicht jene groben fehler, wie sich sich aus deiner viel zu simplifizierenden betrachtung heraus ergeben müssten.
und eines sei nach hinzugefügt: auch nach mehr als hundert jahren filmgeschichte, besteht ein film od. video noch immer aus aufeinander folgenden einzelbildern, die prinzipiell natürlich in völlig gleicher weise bearbeitet werden, wie man das auch in der bildbearbeitung mit einzelnen standbildern macht -- ich spreche allerdings bewusst nicht von "grafik", weil ich letzteres eher mit auflösungsunabhänger bearbeitung von konturen, im sinne von "vektorgrafik", in verbindung bringen würde.
Antwort von HJS:
ich habe jetzt deine Argumentation verstanden und finde, dein beispiel erläutert den sachverhalt richtig
Wenn Du im Videobild z.B. einen Übergang von Schwarz auf Weiss hast, also 0 und 255, dann bekommst Du im 10 Bit Signal da plötzlich einen interpolierten grauen Wert, der im Originalbild überhaupt nicht vorhanden war.
Jetzt steigen wir aber in die Tiefen...
Was du sagst sehe ich auch so. Allerdings ist meine Interpretation anders.
Dieser neue Streifen mit einem Helligkeitswert von 128,5 hat ja nichts mit der Bittiefe zu tun, sondern es ist ein "Fehler" im herunterskalierten Bild. Dieser Fehler ist ein Aliasingfehler. Wenn du zwei benachbarte Helligkeitsflächen wie von dir beschrieben abtastest, machst du eine Unterabtastung (nach Shannon). Dadurch entstehen neue Komponenten im Bild, die man bekanntlich Aliase nennt. Und genau deshalb müssen die Herunterskalierungsfilter auch mehr sein als ein einfacher Mittelwertbildner. Zumindest bei Profiansprüchen.
Ich bin nicht sicher, ob es hier noch viele gibt, die sich für unsere Postings über die Theorie interessieren?
Gruß Jürgen
Antwort von WoWu:
@ Jürgen, das ist wohl richtig, aber zeigt ganz deutlich, dass für die restlichen 2 Bit keine Werte in der Bildinformation vorhanden sind und ich habe ein solches einfaches Beispiel bewusst gewählt, damit Domain nicht wieder kommt und sagt . . die Farbe stimmt nicht, und um es außerdem nachvollziehbar zu halten.
Das bedeutet aber, dass es bei keinem Wert stimmt, weil kein Wert bekannt ist, der aus dem 8Bit Signal kommt und der reproduziert werden könnte.
Bestenfalls gibt es mal den einen oder andern Zufallstreffer.
Das ist eben der Unterschied zwischen Enhancement und Reproduktion,was für das 444 Beispiel ebenso zutrifft.
Man kann zwar in einem Verrfahren Korellationen verbessern, die dann in Richtung 444 von der 420 abweichen .... nur ist das Enhancement und stimmt nur mit 20-70%iger Genauigkeit.
Aber hier wird ja eine definitive Behauptung aufgestellt ... aus 8Bit werden 10 Bit und aus 420 wird 444.
Das sind Reproduktionen und keine Enhancements, denn jeder geht davon aus dass das Egebnis identisch mit dem wäre, was eine 444 bzw. 10Bit Kamera abgegeben hätte.
Daher sind die Aussagen einfach nur falsch.
Das die Bilder durch den einen oder andern Algorithmus vermeintlich besser aussehen können, ist unbestritten.
Das ist aber eben Enhancemnet, also Bildmanipulation, die auf Schätzungen beruht und nicht auf Original Bildanteilen der Szene.
Ich stimme Dir zu, das es vermutlich keinen mehr interessiert, aber genau das ist der Grund, warum sich so ein Quatsch so beharrlich in den Blogs hält, weil niemand widerspricht, weil es keinen interessiert und jeder denken möchte, das könne seine Kamera nun auch und sich in dem Gedanken wohl fühlt.
Antwort von mash_gh4:
Das ist eben der Unterschied zwischen Enhancement und Reproduktion,...
kannst du mir bitte noch erklären, wie eine skalierung unter der vorgabe eines derart unantastbaren reinheitsgebots überhaupt noch durchgeführt werden könnte?
(sorry: aber alle anderen hier reden die ganzen zeit von nichts anderem als dem verkleinern!)
von 'enhancement' zu sprechen scheint mir ja nicht unbedingt angebracht, weil dabei ja in jedem fall 3/4 der pixel irgendwie verloren gehen. es bleibt uns aber natürlich noch immer die wahl, ob wir z.b. jeweils nur das linke obere pixel in jeder vierergruppe an pixeln im ausgangsbild herausgreifen und weitestgehend unverfälscht ins resultat übernehmen, das arithmetische mittel aller vier benachbarten pixel heranziehen, oder aber zu noch komplizierteren methoden greifen. ich denke, die meisten hier wissen, wie sich das auf die bildqualität der resultierenden verkleinerung jeweils niederschlägt.
Antwort von Roland Schulz:
So ein Blödsinn, was soll ich zugeben ?
Es gelingt weder Euch, noch den beschrienen Universitäten, aus einem 4:2:0 Signal wieder ein 4:4:4 zu machen.
Bisher hat es von Euch da auch, bis auf irgendwelche Behauptungen keine Belege gegeben, die sich an der Wirklichkeit orientieren.
Ihr legt einfach zwei Matritzen aufeinander, mitteilt irgendwas und behauptet, jetzt sei es 4:4:4.
Dabei stehen schon die Pixelwerte in einem Zusammenhang zueinander, der mit berücksichtigt werden muss, aber die Realität scheint Euch nicht zu interessieren.
Das widerspricht übrigens auch nicht nur meiner Meinung, sondern offenbar auch derer von Leuten die sich da ausgiebig mit beschäftigt haben und auf deren Grundlage Dissertationen oder zumindest fundierte wissenschaftliche Aufsätze entstanden sind.
Da hilft auch kein provokantes ... "gib es doch zu".
Damit werden Deine falschen Behauptungen auch nicht richtig, Du versuchst damit nur diesen Eindruck zu erwecken.
Dabei ist es einfach Quatsch, den ihr da aus den unterschiedlichen Blogs entnommen habt.
Aber ... gut gebrüllt Löwe...
wahrscheinlich gibt es hier auch einige, die den Quatsch glauben.
Nochmal, aus einem 4:2:0 wird nicht "wieder" ein 4:4:4, das hat niemand behauptet, aus 4:2:0 wird durch Downscale 4:4:4, glaube das hatten wir jetzt 20 mal...
Na ja, ich hab"s nochmal freundlich versucht, aber entweder willst Du nur provozieren und lachst Dich über uns kaputt oder überschaust wirklich keine Summe aus 1 und 1.
Ich denke einige hier hätten mehr Respekt verdient...
https://de.wikipedia.org/wiki/Farbunterabtastung
(ist zwar nicht von mir, aber mit Sicherheit auch falsch...)
Dann mach" mal so weiter...
Antwort von mash_gh4:
8bit wird 10bit durch Downscaling ist Quatsch - warum?!
...
Bei homogenen Flächen (oder auch bei "langsamen" Veränderungen) macht die Interpolation durch Downscaling (Barry Green) auch keinen Sinn, da alle umgebenden Pixel innerhalb der Fläche den gleichen Wert besitzen.
...
Da wo uns 10bit in der Praxis was bringt, bei der Erfassung von "langsamen" oder "weichen" Verläufen und anschließendem "Grading", bringt das Downscaling mit 8bit auf 10bit Transformation der Quelle folglich nichts.
das ist ein wirklich guter einwand, der deutlich mehr substanz besitzt als manch andere hier vorgebrachte hirngespinste -- den ganzen müll, der einem den blick auf das wesentliche verstellt.
das läuft wohl nachvollziehbar darauf hinaus, dass man in dem fall nicht in gleicher weise wie beim farbunterabttastung tatsächlich jene werte erhält, die der auflösung angemessen sind. trotzdem macht es vermutlich sinn, die 10bit zu nutzen bzw. zu erhalten, die sich bei der umrechnung ergeben, auch wenn sie in dem fall nicht unmittelbar auf die quellwerte zurückweisen.
danke nocheinmal für diese erhellende erklärung!
das macht hat den unterschied zwischen wirklich informativen diskussionsbeiträgen und dem fast schon gewohnten schwachsinn aus!
edit:
ich würde dir übrigens widersprechen, was diesen punkt betrifft:
Die 8bit Abbildung kann also niemals die "feine" (Zwischen-)Informationen einer 10bit Abbildung gespeichert haben. Der "Quantisierungsfehler", also die Differenz des diskret abzubildenden Wertes vom tatsächlichen Wert kann bei einer 8bit Abbildung bis zu <4 mal größer sein als bei einer 10bit Abbildung. Die 8bit Abbildung enthält keine Informationen darüber, wie genau oder groß der tatsächliche oder der 10bit Wert gewesen wäre.
unter der vorgabe der hier diskutierten verkleinerung ist es prinzipiel schon möglich, mit vier benachbarten 8bit aufgelösten pixeln einen einzigen resultierenden 10bit wert akkurat darzustellen!
aber erwarten sollte man dahingehend optimiertertes dithering unter realistischen bedingungen besser nicht ;) es würde sich ja auch mit allen gebräuchlichen formen der bildkomprimierung nicht gut vertragen.
Antwort von WoWu:
nicht auf die Quellwerte zurück zu weisen, heiß fehlerhafte Werte einzusetzen.
Und nochmal ... 4:4:4 heißt, dass ein Signal ohne Unterabtastung vorliegt.
Bei einem Downscaling von UHD nach HD geschieht aber die erste Unterabtastung bereits in der Kamera, nach 4:2:0 , das heißt, du hast bereits ein beschädigtes Bild, das ohnehin nie wieder 444 werden kann, weil Du die Beschädigung nicht wieder rückgängig machen kannst .... und die zweite Unterabtastung (nach einer Methode, die es in keinem derzeitigen NLE vermutlich gibt, nämlich einer Unterabtastung ausschließlich im Y - Signal, bei der zusätzlich noch ein großer Teil dessen nachträglich getätigt werden muss, das eigentlich in einem De-Bayering geschieht, die Kantenortbestimmung oder Korellationen der Farbsigmale.
Du kannst nicht einfach zwei Matrixen übereinanderlegen und dann ist es 4:4:4 bestenfalls kommt ein Signal 2:2:0 dabei heraus, weil die y Frequenz ebenfalls nochmal halbiert wird.
Die Berechnungen dafür findest Du in den genannten Papieren.
Und vom ständigen Wiederholen einer Blogweisheit wird sie auch nicht richtiger, zumal sich das Biöd für Mitleser so darstellt, als müsse man nur das UHD Signal in eine HD Timeline legen und hätte dann ein 2k 444 Signal.
Das ist grottenfalsch weil man dann nämlich nicht weiter hat als eine weitere Unterabtastung und streng genommen ein 2:1:0 Signal daraus macht.
Um eine Korrektur nach 444 hinzubiegen bedarf es der erwähnten Enhancement Algorithmen, die die erforderliche Korellationen vornimmt aber lediglich einen Wirkungsgrad von 20-70% aufweist, je nach Bildinhalt, mit andern Worten, 444 nie vollständig erreicht.
Wie gesagt, das Bloggeschwafel wird durch ständiges Wiederholen nicht richtiger, auch wenn Du daran glaubst, es aber nirgend anständig belegen kannst sondern immer nur behauptest und sagst, Du könntest es belegen.
Tue es einfach .... und ich wette, es kommen wieder irgendwelche Blog Bezüge dabei heraus.
Und nun stell Dich nicht so an und rede nicht so einen Schmarn von Respekt, nur weil ich dem Schwachsinn widerspreche und das auch noch Belege.
Wenn Du Kittelgläubigkeit erwartest, musst Du Dich an JOTT wenden.
Antwort von mash_gh4:
ich glaube, da erzählst du einen ziemlichen quatsch. die RGB-YUV umwandlung in ihrer normgerechten YCbCr variante und das zugehörige farbsubsampling wird üblicherweise ziemlich einfach bewerkstelligt.
die formeln dafür kannst du übrigens auch einem lexikonartikel entnehmen, den ich ohnehin schon viel früher hier verlinkt habe.
Antwort von WoWu:
Völlig andere Baustelle, hier geht es um Unterabtastung und was die Korellationen angeht, empfehle ich nochmal die Papiere, die die Grundprobleme recht exakt beschreiben.
Du kannst aus einem durch Unterabtastung beschädigten Bild den Fehler auch nicht durch Korellationen wieder beseitigen.
Und 444 ist nunmal per Definition ein durch Unterabtastung unbeschädigtes Bild.
Pech ... dafür hat die Kamera schon gesorgt, egal, was Du hinterher mit dem Signal noch anstellst.
Antwort von mash_gh4:
Und 444 ist nunmal per Definition ein durch Unterabtastung unbeschädigtes Bild.
zum glück brauchen wir uns über die historischen ursprünge dieses bzeichnungsschemas heute keine goßen gedanken mehr zu machen. in der digitalen praxis ist manches doch ein bisserl einfacher und überschaubarer geworden. aber natürlich gab es stimmen, die gefordert haben, dass man im fall von HDTV eigentlich auch von 22:11:11 sprechen müsste. ;)
Antwort von Roland Schulz:
...vielleicht kann hier ein hochkompetentes Mitglied uns "Unterbelichtete" mal erleuchten und folgende Punkte kurz, klar, sachlich und richtig in Bezug auf Pixel in Zeilen und Spalten, oder sagen wir anhand eines 2x2 Pixel großen Pixelblocks erklären:
1. was bedeutet "4:2:0" eigentlich, was wird hier wie abgetastet und wie gespeichert?!
2. was bedeutet dagegen "4:4:4", was ist hier anders als bei "4:2:0"?!
3. welchen Farbwert würde eine echte (!!!) "4:4:4" Kamera A in einem bestimmten Pixel darstellen, wenn diese horizontal wie vertikal nur die Hälfte an Pixeln einer echten (!!!) "4:4:4" Kamera B im gleichen Ort darstellen kann?!
4. welche/n Farbwert/e würde eine echte (!!!) "4:2:0" Kamera C in einem bestimmten 2x2 Pixelblock speichern?!
Das würde diesen "Blog" doch mal richtig bereichern, wenn das mal richtig dargestellt werden könnte...
Bitte, Freiwillige vor, aber nachher nicht weinen wenn ihr euch im hier diskutierten Kontext selbst widersprech(t/en müsst).
Antwort von Roland Schulz:
...vielleicht kann hier ein hochkompetentes Mitglied uns "Unterbelichtete" mal erleuchten und folgende Punkte kurz, klar, sachlich und richtig in Bezug auf Pixel in Zeilen und Spalten, oder sagen wir anhand eines 2x2 Pixel großen Pixelblocks erklären:
1. was bedeutet "4:2:0" eigentlich, was wird hier wie abgetastet und wie gespeichert?!
2. was bedeutet dagegen "4:4:4", was ist hier anders als bei "4:2:0"?!
3. welchen Farbwert würde eine echte (!!!) "4:4:4" Kamera A in einem bestimmten Pixel darstellen, wenn diese horizontal wie vertikal nur die Hälfte an Pixeln einer echten (!!!) "4:4:4" Kamera B im gleichen Ort darstellen kann?!
4. welche/n Farbwert/e würde eine echte (!!!) "4:2:0" Kamera C in einem bestimmten 2x2 Pixelblock speichern?!
Das würde diesen "Blog" doch mal richtig bereichern, wenn das mal richtig dargestellt werden könnte...
Bitte, Freiwillige vor, aber nachher nicht weinen wenn ihr euch im hier diskutierten Kontext selbst widersprech(t/en müsst).
Antwort von cantsin:
Lasst uns die Debatte doch mal abkürzen und einen Praxistest machen.
Ich habe hier 7 Beispielbilder, die ich mit einer Sigma DP2s bei optimaler ISO 50 raw geschossen und als 16bit-TIFFs (mit Standardeinstellungen, ohne Nachbearbeitungen) aus Sigma Photo Pro 6 exportiert habe. Dank des Foveon-Sensors der Sigma sollte es sich um echtes 12bit 4:4:4-Bildmaterial handeln.
Jetzt könnte man testen, was passiert, wenn man
(a) die Original-TIFFS von 2640x1760 auf 1320x880 herunterskaliert (bei einer Farbtiefe von mindestens 12bit);
(b) die Original-TIFFS erst auf 8bit 4:4:4 Farbtiefe-/sampling reduziert und dann auf 1320x880/12bit herunterskaliert.
(c) die Original-TIFFs erst auf 8bit 4:2:0 Farbtiefe-/sampling reduziert und dann auf 1320x880/12bit herunterskaliert.
Die Frage ist, wie signifikant die Unterschied der Resultate von (a), (b) und (c) sind - vor allem dann, wenn man die Farben der Bilder durch Color Grading verbiegt.
Hier die Original-TIFFs (Dateigröße jeweils 27MB):
http://data.pleintekst.nl/foveon-tiff/SDIM0075.tif
http://data.pleintekst.nl/foveon-tiff/SDIM0077.tif
http://data.pleintekst.nl/foveon-tiff/SDIM0096.tif
http://data.pleintekst.nl/foveon-tiff/SDIM0107.tif
http://data.pleintekst.nl/foveon-tiff/SDIM0346.tif
http://data.pleintekst.nl/foveon-tiff/SDIM0419.tif
http://data.pleintekst.nl/foveon-tiff/SDIM0431.tif
(JPEG-Voransichten anbei.)
Antwort von cantsin:
...vielleicht kann hier ein hochkompetentes Mitglied uns "Unterbelichtete" mal erleuchten und folgende Punkte kurz, klar, sachlich und richtig in Bezug auf Pixel in Zeilen und Spalten, oder sagen wir anhand eines 2x2 Pixel großen Pixelblocks erklären:
Wikipedia hat dazu bereits einen gut verständlichen Artikel:
https://de.wikipedia.org/wiki/Farbunterabtastung
Kurz gesagt, geht es darum, wieviel Farbauflösung (Chroma) im Verhältnis zur Graustufenauflösung (Luma) in einem Bild gespeichert werden. Von Unterabtastung spricht man, wenn die Chromaauflösung kleiner ist als die Lumaauflösung - was bedeutet, dass im dargestellten Bild Farbwerte interpoliert werden. Nur bei 4:4:4 gibt's keine Unterabtastung, also wirklich für jeden Pixel das vollständige Farbspektrum.
Bei Bayer-Sensoren (wie sie in ca. 99% aller digitalen Foto- und Videokameras verbaut sind) kriegt man nie echtes 4:4:4 hin, da der Sensor eigentlich nur schwarzweiss "sieht", vor jedem Pixel ein Rot- Grün oder Blaufilter sitzt und das volle Farbspektrum per Pixel aus den Werten der Nachbarpixel interpoliert wird.
Antwort von mash_gh4:
Lasst uns die Debatte doch mal abkürzen und einen Praxistest machen.
das ist leichter gesagt als getan. die meisten guten programme rechnen durchgängig im RGB raum und benutzten YUV und unterabstastungstechniken ausschließlich im zusammenhang mit dem transport bzw. ein- und ausgabe. damit schleichen sich beim sauberen nachvollzug aber derart viele fehlerquelen ein, dass das ganze nicht mehr sehr viel sinn macht. ich hab's jedenfalls trotzdem versucht und in eine möglichst nachvollziehbare form zu bringen versucht.
hier meine umsetzung deiner drei versuchsaufgaben:
a)
ffmpeg -i SDIM0431.tif -vf format=pix_fmts=rgb48le,scale=880x1320:flags=print_info+neighbor+bitexact SDIM0431-fall_a.tif
b)
ffmpeg -i SDIM0075.tif -vf 'format=pix_fmts=yuv444p,scale=880x1320:flags=print_info+neighbor+bitexact,format=pix_fmts=rgb48le' SDIM0075-fall_b.tif
c)
ffmpeg -i SDIM0075.tif -vf 'format=pix_fmts=yuv420p,scale=880x1320:flags=print_info+neighbor+bitexact,format=pix_fmts=rgb48le' SDIM0075-fall_c.tif
ich habe es allerdings noch um einen vierten, nicht ganz unkomplizierten fall erweitert, der möglichst präzise das zu leisten versucht, was wir hier diskutieren.
(vgl. dazu: http://www.personal-view.com/talks/disc ... ress-topic )
d)
ffmpeg -i SDIM0075.tif -filter_complex 'format=pix_fmts=yuv420p,extractplanes=y+u+v[y][u][v]; [u] scale=w=1760:h=2640:in_range=full:flags=print_info+neighbor+bitexact [us]; [v] scale=w=1760:h=2640:in_range=full:flags=print_info+neighbor+bitexact [vs]; [y][us][vs]mergeplanes=0x001020:yuv444p,format=pix_fmts=yuv444p10le,scale=w=880:h=1320:flags=print_info+bicubic+full_chroma_inp+full_chroma_int,format=pix_fmts=rgb48le' SDIM0075-fall_d.tif
der auschnitt, den ich gewählt habe in 100% (im weiteren verlauf 200%) größe:
zum Bild
die stark hervorgehobene differenz zw. original und aufgabenstellung (a):
zum Bild
original versus (b):
zum Bild
original versus (c):
zum Bild
und -- besonders spannend -- auch noch der fall (d):
zum Bild
letzteres bsp. demonstriert meiner ansicht nach recht anschaulich, dass es nicht nur bloße theorie ist, sondern die aufhebung des farbsubsamplings beim skalieren tatsächlich gelingen kann, wenn man es sauber umsetzt.
in der praxis dürfte keiner dieser fälle wirklich ins gewicht fallen!
die unschärfen in den ausgangsbildern wirken vermutlich störender.
ich hoffe, mir ist bei der praktischen umsetzung nicht wieder ein ganz grober schnitzer unterlaufen. bitte einfach zu protestieren, sollte es doch der fall sein!
Antwort von Jott:
Und nun stell Dich nicht so an und rede nicht so einen Schmarn von Respekt, nur weil ich dem Schwachsinn widerspreche und das auch noch Belege.
Wenn Du Kittelgläubigkeit erwartest, musst Du Dich an JOTT wenden.
Wieso schon wieder so wütend? Ich lese doch nur mit und amüsiere mich! :-)
Antwort von Roland Schulz:
...vielleicht kann hier ein hochkompetentes Mitglied uns "Unterbelichtete" mal erleuchten und folgende Punkte kurz, klar, sachlich und richtig in Bezug auf Pixel in Zeilen und Spalten, oder sagen wir anhand eines 2x2 Pixel großen Pixelblocks erklären:
Wikipedia hat dazu bereits einen gut verständlichen Artikel:
https://de.wikipedia.org/wiki/Farbunterabtastung
...hatte ich ja bereits referenziert und ja, die 4:4:4 Kamera gibt es in Form von 3-Chip Kameras, von Sony sogar bereits als 4K in der Queue...
Antwort von Roland Schulz:
...vielleicht kann hier ein hochkompetentes Mitglied uns "Unterbelichtete" mal erleuchten und folgende Punkte kurz, klar, sachlich und richtig in Bezug auf Pixel in Zeilen und Spalten, oder sagen wir anhand eines 2x2 Pixel großen Pixelblocks erklären:
1. was bedeutet "4:2:0" eigentlich, was wird hier wie abgetastet und wie gespeichert?!
2. was bedeutet dagegen "4:4:4", was ist hier anders als bei "4:2:0"?!
3. welchen Farbwert würde eine echte (!!!) "4:4:4" Kamera A in einem bestimmten Pixel darstellen, wenn diese horizontal wie vertikal nur die Hälfte an Pixeln einer echten (!!!) "4:4:4" Kamera B im gleichen Ort darstellen kann?!
4. welche/n Farbwert/e würde eine echte (!!!) "4:2:0" Kamera C in einem bestimmten 2x2 Pixelblock speichern?!
Das würde diesen "Blog" doch mal richtig bereichern, wenn das mal richtig dargestellt werden könnte...
Bitte, Freiwillige vor, aber nachher nicht weinen wenn ihr euch im hier diskutierten Kontext selbst widersprech(t/en müsst).
Die Sonne ist wieder aufgegangen und beleuchtet uns, "erleuchet" sind wir aber noch nicht.
So, wäre doch schön wenn uns "die eine Person" das heute hier mal kurz und knapp und ohne 5 seitige Ableitungen und Abschweifungen richtig erklären könnte.
Ne aktuelle, relativ durchschnittliche Kamera schafft sowas schließlich ca. 51.840.000 Mal in der Sekunde, das kann doch dann nicht soooo geheim und kompliziert sein!
Los los, ein neuer, frischer Tag steht an und promovierte Rentner könnten den roten Faden doch mal richtig zum Leuchten bringen!!
Nachdem wir doch jetzt schon am 5. Tag bunt rumphantasieren als hätten wir kolumbianische Drogen genommen wollen wir es endlich wissen, das halbe Forum liest mittlerweile mit und ist ganz gespannt, Jott ist auch da und wartet auf den nächsten Schlag in den Torf.
Verwandele Asche wieder in Leben, mach" verbranntes Land wieder urbar, lass" "Belege und Papiere" sprechen, zeig" dass die die glauben es verstanden zu haben hier alle falsch liegen, zeig" uns das sich neben der "falschen" deutschen als auch der englischen Wikipedia Erklärung zum Chroma Subsampling die ganze Welt irrt, zeig" uns wie"s geht!!!
Wer den Hammer schwingt muss auch irgendwann mal den Nagel treffen - beantworte die 4 Fragen, anders kommst Du hier nicht mehr raus!!
Antwort von Jott:
Am Rande: bayerfreies 4K mit 3 Sensoren.
http://www.ikegami.de/uhk-430.html
Aber zum Thema: ein Viererblock wird zu einem einzelnen Pixel gemittelt, wenn im NLE von UHD zu HD skaliert wird (wegen des netterweise exakten Teilers 2 horizontal wie vertikal). Durch die Mittelung kann dieses frische Pixel natürlich mehr Werte annehmen, als es im ursprünglichen Sampling-Korsett möglich war. Es wäre doch geradezu doof, dieses neue Pixel dann nicht in 10Bit oder höher zu erfassen. Und deshalb macht man's auch genau so, dort draußen in der wilden Praxis: UHD 4:2:0-Material in einer 1080p-10Bit-Timeline verarbeiten. Schaden tut's bestimmt nicht.
Antwort von Roland Schulz:
...ein Viererblock wird zu einem einzelnen Pixel gemittelt, wenn im NLE von UHD zu HD skaliert wird. Durch die Mittelung kann dieses frische Pixel natürlich mehr Werte annehmen, als es im ursprünglichen Sampling-Korsett möglich war. Und deshalb macht man's auch genau so, dort draußen in der wilden Praxis: UHD 4:2:0-Material in einer 1080p-10Bit-Timeline verarbeiten. Schaden tut's bestimmt nicht.
Alles richtig, gewisse Vorteile bringt"s, aber nur in Form von Interpolation bzw. Mittelwertsbildung in 2x2 Pixel großen Bereichen, darüber hinaus nicht!
Es wird kein "echtes" 10bit!
Flächen werden weiterhin nur 256 Abstufungen pro Kanal annehmen können, da ist auch nichts zurückgewinnbar.
Der eigentliche Vorteil, feine Abstufungen wie bei 10bit möglich abzubilden bleibt verwehrt.
Deshalb erlaube mir bitte das nicht mit einer echten 10bit Kamera/Verarbeitung gleichzusetzen und es als Quatsch zu bezeichnen.
Antwort von mash_gh4:
Flächen werden weiterhin nur 256 Abstufungen pro Kanal annehmen können, da ist auch nichts zurückgewinnbar.
Der eigentliche Vorteil, feine Abstufungen wie bei 10bit möglich abzubilden bleibt verwehrt.
naja -- nur unter der voraussetzung, dass sie nicht gedithert sind.
im grunde sind aber weder kamerahersteller, noch filmschaffende, auch wenn sie im produktionsumfeld mit höheren auflösungen arbeiten, daran interessiert, dass sich auf endgeräten auch nur eine spur von banding zeigt. so lange man aber über genauere daten verfügt, ist es ein leichtes, diese auch sehr gezielt über größere flächen als leicht abweichende bildpunkte zu streuen, um diesem problem entgegenzuwirken und deutlich weichere verläufe zu schaffen. allerdings verträgt sich das denkbar schlecht mit kompressionswünschen. ich würde also eher sagen, dass wir hauptsächlich letzteren diese wunderbar glattgebügelten unnatürlich homogenen flächen zu verdanken haben, die dann die genannten probleme nach sich ziehen.
Antwort von Roland Schulz:
Flächen werden weiterhin nur 256 Abstufungen pro Kanal annehmen können, da ist auch nichts zurückgewinnbar.
Der eigentliche Vorteil, feine Abstufungen wie bei 10bit möglich abzubilden bleibt verwehrt.
naja -- nur unter der voraussetzung, dass sie nicht gedithert sind.
Genau! Den eigentlichen 10bit Vorteil gibt's nicht!
Antwort von HJS:
Es wäre doch geradezu doof, dieses neue Pixel dann nicht in 10Bit oder höher zu erfassen. Und deshalb macht man's auch genau so, dort draußen in der wilden Praxis: UHD 4:2:0-Material in einer 1080p-10Bit-Timeline verarbeiten. Schaden tut's bestimmt nicht.
genau!
Gruß Jürgen
Antwort von HJS:
...ein Viererblock wird zu einem einzelnen Pixel gemittelt, wenn im NLE von UHD zu HD skaliert wird. Durch die Mittelung kann dieses frische Pixel natürlich mehr Werte annehmen, als es im ursprünglichen Sampling-Korsett möglich war. Und deshalb macht man's auch genau so, dort draußen in der wilden Praxis: UHD 4:2:0-Material in einer 1080p-10Bit-Timeline verarbeiten. Schaden tut's bestimmt nicht.
Alles richtig, gewisse Vorteile bringt"s, aber nur in Form von Interpolation bzw. Mittelwertsbildung in 2x2 Pixel großen Bereichen, darüber hinaus nicht!
...
Deshalb erlaube mir bitte das nicht mit einer echten 10bit Kamera/Verarbeitung gleichzusetzen und es als Quatsch zu bezeichnen.
Hallo Roland,
also beim Thema 4:2:0 nach 4:4:4 sind wir uns hier ja einig. Na ja, alle haben es noch nicht verstanden...
Aber beim Thema 8 Bit vs 10 Bilt empfinde ich dich genauso unbeweglich, wie du es anderen hier vorwirfst ;=)
Ich mache noch einen Versuch:
Stell dir vor, du hast ein Bild das sich von schwarz ganz links nach hell ganz rechts ändert. So ein typisches Bild, wo es Banding geben kann.
Ich schreibe mal die Luminanzwerte einer Zeile hin:
0 0 0 0 0 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 ...
das sind 0, 1, 2 und 3 also vier unterschiedliche Luminanzwerte
Wenn du nun jeweils 2 Werte mittelst, dann erhältst du die Folge
0 0 0,5 1 1 2 2 2,5 3 ...
das sind 0, 0,5 1, 2, 2,5 3 also plötzlich 6 unterschiedliche Werte. damit wird das Banding kleiner sein. Und wir haben plötzlich eine höhere Luminanzauflösung bzw. Bittiefe.
Da ist auch keine Mystik dahinter, denn wir haben Bittiefe gewonnen und Ortsauflösung verloren. Für die Theoretiker: die Entropie bleibt gleich.
Wir diskutieren hier theoretische Effekte, die man oft in Praxis nicht erkennen wird. Hier interessieren wir uns allerdings für diese technischen Details. Diese Bemerkung nur für diejenigen die sich vielleicht fragen, ob die hier schon jemals ein Video produziert haben.
Gruß Jürgen
Antwort von domain:
Nachdem wir doch jetzt schon am 5. Tag bunt rumphantasieren als hätten wir kolumbianische Drogen genommen wollen wir es endlich wissen, das halbe Forum liest mittlerweile mit und ist ganz gespannt...
Ja weil real ausgetragene Glaubenskriege immer spannend sind.
Könnte jetzt gar nicht sagen, welche Richtung bisher die glaubhafteren Argumente geliefert hat.
Aber schon immer basierte jeder Glaube auf einer inneren Überzeugung, die keines Beweises bedarf.
Antwort von cantsin:
Wenn du nun jeweils 2 Werte mittelst, dann erhältst du die Folge
0 0 0,5 1 1 2 2 2,5 3 ...
Schönes Beispiel, weil sich daran zeigt, dass aus der Mittlung bzw. Interpolation des unterabgetasteten Material eben doch kein sauberer Farbverlauf resultiert. In Deiner Folge gibt es nur an zwei von neun Stellen (einmal 0,5, einmal 2,5) Zwischenwerte, während die gröber aufgelösten Werte mit 7:2 dominieren.
Alles, was wir kriegen, sind also feinere Farbabstufungen an einigen Kanten der gröberen Farbabstufungen (in anderen Worten: Aliasing), aber nicht einen insgesamt feiner abgestuften und sauberen/konstanten Verlauf.
Man adelt also Aliasing-Artefakte zu höherer Farbauflösung... EDIT: Manchmal mag das ja hinkommen, wenn der Aliasing-Pixel zufällig gerade den Farbwert liefert, der bei der Unterabtastung wegfiel. Ob das aber so ist, und ob der Pixel nicht vielmehr ein Falschfarb-Artefakt-Pixel ist, weiss man nicht, weil die Information ja im unterabgetasteten Ausgangsmaterial nicht vorhanden war.
Antwort von CameraRick:
d)
ffmpeg -i SDIM0075.tif -filter_complex 'format=pix_fmts=yuv420p,extractplanes=y+u+v[y][u][v]; [u] scale=w=1760:h=2640:in_range=full:flags=print_info+neighbor+bitexact [us]; [v] scale=w=1760:h=2640:in_range=full:flags=print_info+neighbor+bitexact [vs]; [y][us][vs]mergeplanes=0x001020:yuv444p,format=pix_fmts=yuv444p10le,scale=w=880:h=1320:flags=print_info+bicubic+full_chroma_inp+full_chroma_int,format=pix_fmts=rgb48le' SDIM0075-fall_d.tif
Verstehe ich den Code richtig, dass Du da Nearest Neighbour als Filter nutzt? Da werden ja keine Werte interpoliert, da kann ja gar nichts neues bei rum kommen?
Antwort von HJS:
...In Deiner Folge gibt es nur an zwei von neun Stellen (einmal 0,5, einmal 2,5) Zwischenwerte, während die gröber aufgelösten Werte mit 7:2 dominieren.
Alles, was wir kriegen, sind also feinere Farbabstufungen an einigen Kanten der gröberen Farbabstufungen (in anderen Worten: Aliasing)
Hallo cantsin,
- du kannst natürlich beliebige andere Folgen ausprobieren und kannst unendlich viele Beispiele erzeugen. Auch solche mit mehr Zwischenwerten.
- Aliasing sind Artefakte die entstehen, wenn die Abtastfrequenz niedriger als die doppelte Bandbreite des Signals ist. Dies ist hier mitnichten der Fall: sehe dir doch einmal meine Originalbeispielfolge an. Da wiederholt sich jedes Pixel 5 mal!
Und natürlich ist der Verlauf mit den beiden zusätzlichen Zwischenwerten glatter, nicht linealglatt aber glatter, als der Verlauf vor der Herunterskalierung !! Das ist doch offensichtlich.
Ich möchte nicht oberlehrerhaft rüberkommen. Vielleicht darf ich trotzdem hier noch mal daran erinnern, dass die diskrete Signaltheorie nicht einfach ist. Ich habe hier mehrmals gelesen, dass im herunterskalierten Signal nichts drin sein kann, was vorher nicht da war.
Das klingt zunächst plausibel und ist auch richtig. Aber wenn ein Signal bandbegrenzt ist, so wie beinahe alle Videokamerasignale (z.B. durch den OLPF), dann hat das Signal Eigenschaften die es z.B. ermöglichen. nahezu fehlerfreie Interpolationen zu machen.
Eine simple Eins-Null-Folge kann bekanntlich durch einen analogen Tiefpass wieder in ein mathematisch korrektes Sinussignal mit allen (!) Zwischenwerten rückgewandelt werden. Also in der Eins-Null-Folge sind alle Zwischenwerte schon enthalten!!
Ich erwähne das nur deshalb, damit sich der eine oder andere daran erinnert, dass die Anschauung alleine nicht genügt, um die Effekte im Digitalen alle zu durchschauen.
Gruß Jürgen
Antwort von Roland Schulz:
...ein Viererblock wird zu einem einzelnen Pixel gemittelt, wenn im NLE von UHD zu HD skaliert wird. Durch die Mittelung kann dieses frische Pixel natürlich mehr Werte annehmen, als es im ursprünglichen Sampling-Korsett möglich war. Und deshalb macht man's auch genau so, dort draußen in der wilden Praxis: UHD 4:2:0-Material in einer 1080p-10Bit-Timeline verarbeiten. Schaden tut's bestimmt nicht.
Alles richtig, gewisse Vorteile bringt"s, aber nur in Form von Interpolation bzw. Mittelwertsbildung in 2x2 Pixel großen Bereichen, darüber hinaus nicht!
...
Deshalb erlaube mir bitte das nicht mit einer echten 10bit Kamera/Verarbeitung gleichzusetzen und es als Quatsch zu bezeichnen.
Hallo Roland,
also beim Thema 4:2:0 nach 4:4:4 sind wir uns hier ja einig. Na ja, alle haben es noch nicht verstanden...
Aber beim Thema 8 Bit vs 10 Bilt empfinde ich dich genauso unbeweglich, wie du es anderen hier vorwirfst ;=)
Ich mache noch einen Versuch:
Stell dir vor, du hast ein Bild das sich von schwarz ganz links nach hell ganz rechts ändert. So ein typisches Bild, wo es Banding geben kann.
Ich schreibe mal die Luminanzwerte einer Zeile hin:
0 0 0 0 0 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 ...
das sind 0, 1, 2 und 3 also vier unterschiedliche Luminanzwerte
Wenn du nun jeweils 2 Werte mittelst, dann erhältst du die Folge
0 0 0,5 1 1 2 2 2,5 3 ...
das sind 0, 0,5 1, 2, 2,5 3 also plötzlich 6 unterschiedliche Werte. damit wird das Banding kleiner sein. Und wir haben plötzlich eine höhere Luminanzauflösung bzw. Bittiefe.
Da ist auch keine Mystik dahinter, denn wir haben Bittiefe gewonnen und Ortsauflösung verloren. Für die Theoretiker: die Entropie bleibt gleich.
Wir diskutieren hier theoretische Effekte, die man oft in Praxis nicht erkennen wird. Hier interessieren wir uns allerdings für diese technischen Details. Diese Bemerkung nur für diejenigen die sich vielleicht fragen, ob die hier schon jemals ein Video produziert haben.
Gruß Jürgen
Hallo Jürgen,
bin immer für alles offen solange es mich überzeugt, hier allerdings nicht ;-):
Deine Interpolation unterstütze ich voll, das habe ich auch bereits geschrieben. Sie funktioniert aber NUR in einem Bereich von 2x2 Pixeln. Flächen mit Größen >> 2x2 Pixel werden dadurch keine Verbesserung bzw. einen fliessenderen Verlauf erfahren, richtig?!
Innerhalb der homogenen Fläche oder von mir aus auch dem langsam ansteigenden Grauverlauf (alles schon geschrieben) gibt es keine weiteren Informationen im 8bit File, welche irgendwohin in eine Veränderung verrechnet werden könnten.
Eine echte 10bit Abtastung hätte in diesem langsamen Verlauf ~4 mal mehr Informationen in der Intensitätsabstufung erfassen können.
Antwort von Roland Schulz:
...In Deiner Folge gibt es nur an zwei von neun Stellen (einmal 0,5, einmal 2,5) Zwischenwerte, während die gröber aufgelösten Werte mit 7:2 dominieren.
Alles, was wir kriegen, sind also feinere Farbabstufungen an einigen Kanten der gröberen Farbabstufungen (in anderen Worten: Aliasing)
Hallo cantsin,
- du kannst natürlich beliebige andere Folgen ausprobieren und kannst unendlich viele Beispiele erzeugen. Auch solche mit mehr Zwischenwerten.
- Aliasing sind Artefakte die entstehen, wenn die Abtastfrequenz niedriger als die doppelte Bandbreite des Signals ist. Dies ist hier mitnichten der Fall: sehe dir doch einmal meine Originalbeispielfolge an. Da wiederholt sich jedes Pixel 5 mal!
Und natürlich ist der Verlauf mit den beiden zusätzlichen Zwischenwerten glatter, nicht linealglatt aber glatter, als der Verlauf vor der Herunterskalierung !! Das ist doch offensichtlich.
Ich möchte nicht oberlehrerhaft rüberkommen. Vielleicht darf ich trotzdem hier noch mal daran erinnern, dass die diskrete Signaltheorie nicht einfach ist. Ich habe hier mehrmals gelesen, dass im herunterskalierten Signal nichts drin sein kann, was vorher nicht da war.
Das klingt zunächst plausibel und ist auch richtig. Aber wenn ein Signal bandbegrenzt ist, so wie beinahe alle Videokamerasignale (z.B. durch den OLPF), dann hat das Signal Eigenschaften die es z.B. ermöglichen. nahezu fehlerfreie Interpolationen zu machen.
Eine simple Eins-Null-Folge kann bekanntlich durch einen analogen Tiefpass wieder in ein mathematisch korrektes Sinussignal mit allen (!) Zwischenwerten rückgewandelt werden. Also in der Eins-Null-Folge sind alle Zwischenwerte schon enthalten!!
Ich erwähne das nur deshalb, damit sich der eine oder andere daran erinnert, dass die Anschauung alleine nicht genügt, um die Effekte im Digitalen alle zu durchschauen.
Gruß Jürgen
Die Information die wir durch 8->10bit "reintricksen" ist nur eine "Glättung", die so vorher nicht dagewesen sein muss! Die Kante kann hart gewesen sein, jetzt kriegt sie einen gemittelten Übergang, der nicht der Wirklichkeit entsprechen muss.
Ich hatte vorher schon mal über die langsamen Intensitätanstiege etc. geschrieben, wie gesagt, bei homogenen Bereichen/Flächen, die in 8bit nur eine Intensität annehmen können wird es auch durch das Downsampling keine Veränderung geben, weil die benachbarten Pixel identisch sind.
Tatsächlich hätte die "homogene Fläche" aber ursprünglich Abstufungen enthalten können, welche kleiner sind als das Inkrement/der kleinste Wert, den eine 8bit Auflösung abbilden kann. Mit 10bit hätten wir in der Fläche
dagegen ~4 mal so feine Abstufungen erfassen können.
Antwort von Valentino:
Immer wieder lustig wie so ein altes Thema wieder neu aufgewärmt werden kann.
Haben das vor Jahren schon im Studium durchgekaut und wir sollten beweisen das aus einem 4:2:0 HD Bild ein 4:4:4 SD Bild zu generieren ist.
War natürlich einen "Fangfrage" vom Professor, den es geht einfach nicht.
Man hat am Ende ein "pseudo-SD-4:4:4" Bild bei dem die Werte geschätzt werden, an die realen Werte einer 3-CCD SD Kamera ist man aber nie gekommen!
Haben damals auch die von Wolfgang erwähnten wissenschaftlichen Veröffentlichungen als Quellen benutzt und die wurden so auch vom Professor akzeptiert.
Ihr könnte alle gerne weiter an das 4:4:4 Wunder glauben, aber mit etwas wissenschaftlicher Recherche werdet ihr feststellen das Wolfgang und alle anderen Wissenschaftler leider im Recht sind.
Da die Grundlagen für diese Annahme nur mit Hilfe der Physik und Mathematik zu beantworten sind, kann es nur "richtig" oder "falsch" geben.
Ein "die Wahrheit liegt irgendwo in der Mitte" gibt es einfach nicht und schon alleine das Wort "Faustformel" ist unpassend.
Antwort von Roland Schulz:
Immer wieder lustig wie so ein altes Thema wieder neu aufgewärmt werden kann.
Haben das vor Jahren schon im Studium durchgekaut und wir sollten beweisen das aus einem 4:2:0 HD Bild ein 4:4:4 SD Bild zu generieren ist.
War natürlich einen "Fangfrage" vom Professor, den es geht einfach nicht.
Man hat am Ende ein "pseudo-SD-4:4:4" Bild bei dem die Werte geschätzt werden, an die realen Werte einer 3-CCD SD Kamera ist man aber nie gekommen!
Haben damals auch die von Wolfgang erwähnten wissenschaftlichen Veröffentlichungen als Quellen benutzt und die wurden so auch vom Professor akzeptiert.
Ihr könnte alle gerne weiter an das 4:4:4 Wunder glauben, aber mit etwas wissenschaftlicher Recherche werdet ihr feststellen das Wolfgang und alle anderen Wissenschaftler leider im Recht sind.
Da die Grundlagen für diese Annahme nur mit Hilfe der Physik und Mathematik zu beantworten sind, kann es nur "richtig" oder "falsch" geben.
Ein "die Wahrheit liegt irgendwo in der Mitte" gibt es einfach nicht und schon alleine das Wort "Faustformel" ist unpassend.
Stelle ich erneut in Frage, weil es falsch ist.
Welcher Professor oder sonstwer was geschrieben hat lasse ich auch mal außen vor, Wolfgang hat bisher auch nichts produktives beigetragen außer, sagen wir mal mich als Dummschwätzer hinzustellen und seitenlang um den heißen Brei zu reden. Weiterhin wurde "endlos" 4:2:0 zu 4:4:4 in gleicher Auflösung als falsch hingestellt, was ja auch richtig ist und von der ersten Zeile an nie Bestand hatte.
Wir brauchen hier keine Wissenschaft recherchieren, wir brauchen uns nur an die technischen Definitionen halten und 1 und 1 zusammenzählen.
Ich könnte jetzt genau so gut hingehen und behaupten, dass das was Barry Green und Panasonic beschrieben und veröffentlicht haben richtig ist, damit hätte ich ja auch einen Nachweis erbracht. Da dieser aber in der 8/10bit Transformation hinkt bzw. falsch ist spare ich mir das.
Und nochmal, wir brauchen auch keine Kamera für die Sache, das funktioniert ebenso mit generischem Inhalt.
Als ehem. Student der Medientechnik, Nachrichtentechnik oder vergleichbar sollte es Dir doch ein leichtes sein zu erklären, was zum einen 4:2:0 und zum anderen 4:4:4 bedeutet.
...ich kann das hier alles nicht glauben, gleich mach ich doch noch ne Zeichnung...
Antwort von Roland Schulz:
Immer wieder lustig wie so ein altes Thema wieder neu aufgewärmt werden kann.
Haben das vor Jahren schon im Studium durchgekaut und wir sollten beweisen das aus einem 4:2:0 HD Bild ein 4:4:4 SD Bild zu generieren ist.
War natürlich einen "Fangfrage" vom Professor, den es geht einfach nicht.
Man hat am Ende ein "pseudo-SD-4:4:4" Bild bei dem die Werte geschätzt werden, an die realen Werte einer 3-CCD SD Kamera ist man aber nie gekommen!
Haben damals auch die von Wolfgang erwähnten wissenschaftlichen Veröffentlichungen als Quellen benutzt und die wurden so auch vom Professor akzeptiert.
Ihr könnte alle gerne weiter an das 4:4:4 Wunder glauben, aber mit etwas wissenschaftlicher Recherche werdet ihr feststellen das Wolfgang und alle anderen Wissenschaftler leider im Recht sind.
Da die Grundlagen für diese Annahme nur mit Hilfe der Physik und Mathematik zu beantworten sind, kann es nur "richtig" oder "falsch" geben.
Ein "die Wahrheit liegt irgendwo in der Mitte" gibt es einfach nicht und schon alleine das Wort "Faustformel" ist unpassend.
Hier noch ein paar People mehr die an "das Wunder" glauben (allerdings die 10bit Nummer nicht "breit" genug ausgewalzt haben um festzustellen, dass es nur innerhalb von 2x2 Blöcken wahr ist, somit nicht allgemein gilt und die Vorteile einer echten 10bit Erfassung nicht liefert):
http://www.eoshd.com/2014/02/discovery- ... 10bit-444/
http://www.provideocoalition.com/can-4k ... it-matter/
http://www.hdwarrior.co.uk/2015/10/08/w ... rry-green/
http://pro-av.panasonic.net/en/dvx4k/pd ... ol1_en.pdf
Dahinter steht jetzt Panasonic mit Barry Green und u.A. auch David Newman, Senior Director für Software bei GoPro, u.A. für den CineForm Codec etc..
Beweist das jetzt was, nein, die technischen Definitionen dahinter aber!
Antwort von HJS:
Hier noch ein paar People mehr die an "das Wunder" glauben
Roland, wir haben einfach recht. Alle deine Links zeigen das auch.
Aber du könntst dich auch mal langsam mit der Erhöhung der Bittiefe anfreunden, finde ich. Das sehen alle (!) in deinen Links genauso wie ich.
Noch kurz zu deinem Einwand, dass das ganze nur mit Blöcken der Größe zwei mal zwei geht. Dazu folgendes Gedankenexperiment (hatte ich als Assistent mal meinen Studis gegeben):
wir skalieren das Bild so, dass nur noch ein Pixel übrig bleibt und auch wieder durch Mittelwertbildung. Welche Bittiefe hat dann dieses Bild, bestehend aus einem Pixel?
Antwort: ein 4k Bild hat 4k mal 2k Pixel. Jedes Pixel kann zwiswchen 0 und 255 sein. Also kann das auf ein Pixel reduzierte Bild Werte zwischen 0 und 4o96 mal 2048 mal 255, also 2.139.095.040 annehmen. So viele mögliche Helligkeitsabstufungen hat jetzt das 1-pixelige Bild (ich glaube das sind 31 Bit). Vorher hatte es nur 256.
Dieses theoretische Beispiel zeigt, dass das Prinzip an keine Blockgröße gebunden ist.
Gruß Jürgen
ps ich glaube hier gibt es Hardliner, die lassen sich durch nichts überzeugen
Antwort von mash_gh4:
was die 4:2:0/2 rückübersetztung betrifft, teile ich wirklich rolands auffassung voll und ganz. ich bin mir nicht sicher, ob es wirklich für alle absonderlichkeiten der farbunterabtastung gilt -- immerhin gab's da auch so seltsame geschichten, wie um halbe pixel verschobene farbpositionierungen etc. --, aber in jenen einfachen fällen, mit denen wir heute in digitaler form konfrontiert sind, liegt das ausgangsmateral immer als 1:1 RGB pixelmatrix vor und wird am anderen ende der übertragung auch wieder in dieses form gebracht. die entsprechende umrechnung ist wirklich trivial und einfach nachvollziehbar. wenn man das prinzip dahinter versteht, gibt es keinen grund, warum sich hier nach dem herunterskalieren der Y plane noch ein fehler zeigen sollte bzw. keine vollwertige verkleinerte 4:4:4 entsprechung vorliegen sollte.
da könnte man ja gleich behaupten, dass es prinzipiell nicht möglich ist, bilder in einer weise zu verkleinern, die mit dem ursprünglichen ausgangsmaterial noch etwas gemeinsam hat bzw. bezogen auf resultierende größe eine befriedigende qualität liefert.
das einzige, was die skalierung hier ein klein wenig ungewöhnlich erschien lässt, ist die tatsache, dass man die einzelnen kanäle in diesem fall nicht zum selben zeitpunkt skaliert, wie das sonst beim verkleinern eines bilds im hintergrund geschieht, sondern zu verschiedenen zeitpunkten.
die 8bit -> 10bit geschichte ist aber tatsächlich ein bisserl anders gelagert.
ich finde zwar, dass rolands einwand bzgl. der homogenen flächen ziemlich überzeugend wirkt, aber das stellt mich noch immer nicht wirklich zufrieden. ich bin nämlich davon überzeugt, dass eigentlich bereits ein fehler vorliegt, wenn material, das ursprünglich in einer höhereren auflösung verfügbar ist, beim requantisieren in eine niedrigere auflösung nicht ordendlich dithert.
siehe dazu: Requantizing and digital dither -- in: the art of digital video
das kann sogar tatsächlich in einer weise erfolgen, die jeweils viererblöcke entsprechend modifiziert -- siehe z.b. diese konkrete umsetzung in einer bildschirmansteuerung (11ff) . eine umsetzung, die zwar bei näherer betrachtung nicht ganz so ideal ausfällt wie man es sich wünschen würde, aber zumindest doch ein wichtiger anhaltspunkt bildet, um die entsprechenden überlegungen nicht einfach mit hinweis auf ausgeprägtes banding in manchem ursprungsmaterial gleich beiseite schieben zu können.
man müsste wirklich ganz praktisch untersuchen, wie weit sich entsprechendes dithering in realen signalen unsere kameras, aber vor allen dingen aber auch in den komprimierten dateien, die sie uns liefern, finden lässt? erst dann kann man vernünftig entscheiden, ob das wirklich ein völliger quatisch ist und wir uns tatsächlich mit ehrlichen 8bit abfinden müssen.
Antwort von TomStg:
ps ich glaube hier gibt es Hardliner, die lassen sich durch nichts überzeugen
In der Tat: Hier gibt es hardliner, die nicht auf diesen Video-Vodoo-Quatsch von Leuten hereinfallen, die wie im Mittelalter als Blei Gold machen wollten. Das gilt zB auch für alle Hersteller externer Recorder, die diese wundersame Wandlung ganz gewiss zu gerne für ihr Marketing benutzen würden. Denn sie könnten noch so aufwendige Algorithmen locker hard- und/oder softwareseitig realisieren. Warum tun sie es nicht? Weil sie zu blöd sind und sich mit ihrem Kram weniger auskennen, als ein paar selbsternannte "Experten" und Schreihälse mit Basta-Argumentationen in diesem und anderen Foren?
Antwort von Roland Schulz:
was die 4:2:0/2 rückübersetztung betrifft, teile ich wirklich rolands auffassung voll und ganz. ich bin mir nicht sicher, ob es wirklich für alle absonderlichkeiten der farbunterabtastung gilt -- immerhin gab's da auch so seltsame geschichten, wie um halbe pixel verschobene farbpositionierungen etc. --, aber in jenen einfachen fällen, mit denen wir heute in digitaler form konfrontiert sind, liegt das ausgangsmateral immer als 1:1 RGB pixelmatrix vor und wird am anderen ende der übertragung auch wieder in dieses form gebracht. die entsprechende umrechnung ist wirklich trivial und einfach nachvollziehbar. wenn man das prinzip dahinter versteht, gibt es keinen grund, warum sich hier nach dem herunterskalieren der Y plane noch ein fehler zeigen sollte bzw. keine vollwertige verkleinerte 4:4:4 entsprechung vorliegen sollte.
da könnte man ja gleich behaupten, dass es prinzipiell nicht möglich ist, bilder in einer weise zu verkleinern, die mit dem ursprünglichen ausgangsmaterial noch etwas gemeinsam hat bzw. bezogen auf resultierende größe eine befriedigende qualität liefert.
das einzige, was die skalierung hier ein klein wenig ungewöhnlich erschien lässt, ist die tatsache, dass man die einzelnen kanäle in diesem fall nicht zum selben zeitpunkt skaliert, wie das sonst beim verkleinern eines bilds im hintergrund geschieht, sondern zu verschiedenen zeitpunkten.
die 8bit -> 10bit geschichte ist aber tatsächlich ein bisserl anders gelagert.
ich finde zwar, dass rolands einwand bzgl. der homogenen flächen ziemlich überzeugend wirkt, aber das stellt mich noch immer nicht wirklich zufrieden. ich bin nämlich davon überzeugt, dass eigentlich bereits ein fehler vorliegt, wenn material, das ursprünglich in einer höhereren auflösung verfügbar ist, beim requantisieren in eine niedrigere auflösung nicht ordendlich dithert.
siehe dazu: Requantizing and digital dither -- in: the art of digital video
das kann sogar tatsächlich in einer weise erfolgen, die jeweils viererblöcke entsprechend modifiziert -- siehe z.b. diese konkrete umsetzung in einer bildschirmansteuerung (11ff) . eine umsetzung, die zwar bei näherer betrachtung nicht ganz so ideal ausfällt wie man es sich wünschen würde, aber zumindest doch ein wichtiger anhaltspunkt bildet, um die entsprechenden überlegungen nicht einfach mit hinweis auf ausgeprägtes banding in manchem ursprungsmaterial gleich beiseite schieben zu können.
man müsste wirklich ganz praktisch untersuchen, wie weit sich entsprechendes dithering in realen signalen unsere kameras, aber vor allen dingen aber auch in den komprimierten dateien, die sie uns liefern, finden lässt? erst dann kann man vernünftig entscheiden, ob das wirklich ein völliger quatisch ist und wir uns tatsächlich mit ehrlichen 8bit abfinden müssen.
4:2:0 -> 4:4:4 im Faktor 2 Downscale haben jetzt einige verstanden und es gilt in der Theorie allgemein und ist technisch nachvollziehbar.
Die 8->10bit Nummer verweigere ich weiterhin energisch, da diese nicht richtig ist...
Du hast ja nicht ganz unrecht mit der Behauptung, dass Dither die Quantisierung des downgescalten Pixels auf 10bit erhöhen kann.
Das kann aber auch "nur dann" eintreten, wenn bestimmte Bedingungen bei der Generierung des 4:2:0 8bit Materials eingehalten wurden.
Um richtig zu dithern dass am Ende 10bit Informationen rekonstruierbar wären, müsste ja schon in 10bit erfasst worden sein und die Information müsste im Dithering korrekt auf min. 4 Pixel verteilt worden sein.
Hat denn meine Quelle vor dem Dither in 10bit erfasst oder doch nur in 8bit und fügt der Dither am Ende keine "Information" sondern "Rauschen" zu?!
Ist der Ditheralgorithmus "korrekt" angewendet worden? Mein 4:2:0 Signal kann "dummes" 8bit Signal sein, niemand kann das ausschließen.
Wir wissen das alles nicht, die Annahme muss nicht gelten, von daher lasse "ich" es nicht als allgemeingültig gelten.
Wer jetzt noch bei 8 wird 10bit ist, anschnallen und aufgepasst, jetzt kommt noch mal ein richtiger Hammer der die letzte Hoffnung zerlegt!!
Was passiert eigentlich mit der 2 dimensionalen 8bit Farbinformation (U&V), die im prescale 2x2 4:2:0 Pixelblock ja NUR EINMAL "in der Mitte" erfasst und als 8bit gespeichert wurde?!?!
Die wandert im Downscale 1:1 in DIE EINE Farbinformation meines neuen 4:4:4 "Pixels"!! Meine Farbinformation erreicht in keinem Fall eine höhere Quantisierung als die zweidimensionalen 8bit (U&V)!
Sorry ;-)!!!
Antwort von mash_gh4:
Du hast ja nicht ganz unrecht mit der Behauptung, dass Dither die Quantisierung des downgescalten Pixels auf 10bit erhöhen kann.
Das kann aber auch "nur dann" eintreten, wenn bestimmte Bedingungen bei der Generierung des 4:2:0 8bit Materials eingehalten wurden.
es wäre wirklich interessant, wenn wir rausfinden könnten, ob bzw. in welchem maß derartiges dithering im realen output der verschiedenen kameras anzutreffen ist.
eigentlich sollte das ja anhand des signalspektrums erkennbar sein.
über so etwas habe ich mich aber noch nie drüber getraut. bin ich mir nicht sicher, ob mir eine solche analyse tatsächlich gelingen könnte? schaffst du das? oder würdest du dir zumindest einen sinnvolle versuchsanordnung vorstellen können, mit der man ein diesbezügliches urteil über die betreffende blackbox fällen könnte?
Um richtig zu dithern dass am Ende 10bit Informationen rekonstruierbar wären, müsste ja schon in 10bit erfasst worden sein und die Information müsste im Dithering korrekt auf min. 4 Pixel verteilt worden sein.
erfasst und verwertet ist sie vermutlich intern in den meisten heutigen kameras, weil das ja einfach die verwendeten sensoren und ad-wandler nahe legen, wie weit davon aber auch tatsächlich für die optimierung des ausgangssignals genutzt wird, ist eine interessante offene frage. nicht umsonst gibt es auffällige unterschiede zwischen verschiedenen 8bit-kameras bzgl. ihrer tatsächlichen banding neigung.
Die wandert im Downscale 1:1 in DIE EINE Farbinformation meines neuen 4:4:4 "Pixels"!! Meine Farbinformation erreicht in keinem Fall eine höhere Quantisierung als die zweidimensionalen 8bit (U&V)!
da erzählst du mir leider nichts neues -- leider!
bedauerlicherweise wäre ja gerade hier ein entsprechender gewinn wirklich wünschenswert, weil die dortigen auflösungsbegrenzungen gerade bei LOG formaten in der praxis viel störender ins auge fallen als fehlende auflösung im Y kanal.
Antwort von Roland Schulz:
...guck, um die Farbkomponente haben sich Barry Green, Panasonic und auch David Newman einfach drumrumgedrückt und die halbe (Video-)Welt durch Publikationen für dumm verkauft, die Säcke die ;-) ;-) ;-)!!
Ne, ich geb' nicht viel auf das was irgendwelche Professoren oder andere "renommierte" zwölfeinhalbtausender Koryphäen von sich geben, solange ich nicht selbst davon überzeugt bin.
Also wo stehen wir: 4:2:0 wird im k=2 Downscale 4:4:4 und 8bit bleibt ~"8bit" - oder nicht?!?!
Antwort von HJS:
... jetzt kommt noch mal ein richtiger Hammer der die letzte Hoffnung zerlegt!!
Was passiert eigentlich mit der 2 dimensionalen 8bit Farbinformation (U&V), die im prescale 2x2 4:2:0 Pixelblock ja NUR EINMAL "in der Mitte" erfasst und als 8bit gespeichert wurde?!?!
...
Sorry ;-)!!!
wo ist der Hammer??
wir haben hier bei unserem Thema immer von der Luminanz gesprochen. Also vom Y Signal oder von den 3 RGB Signalen. Und alles Gesagte gilt dafür.
Wo ist das Problem?
Gruß Jürgen
Antwort von HJS:
Also wo stehen wir: 4:2:0 wird im k=2 Downscale 4:4:4 und 8bit bleibt ~"8bit" - oder nicht?!?!
Ich stehe bei
1. Durch Herunterskalieren von UHD nach HD können im Allgemeinen die Farbinformationen von 4:2:0 nach 4:4:4 verbessert werden, wenn die Skalierung entsprechend gemacht wird
2. Durch Herunterskalieren von UHD nach HD kann im Allgemeinen die Bittiefe von 8 Bit im Luminanzkanal verbessert werden, im Idealfall um 2 Bit, im Allgemeinen um weniger
Alle von dir zitierten öffentlichen Quellen sehen das auch so, nur du bist der Meinung, dass die alle nur zur Hälfte recht haben und die sich alle in der anderen Hälfte täuschen. Das klingt für mich so, als ob du dir genau das heraussuchst was dir gefällt und das andere durch Sentenzen wie "irgendwelche Professoren oder andere "renommierte" zwölfeinhalbtausender Koryphäen" abwerten möchtest.
Gruß Jürgen
Antwort von srone:
mir geht langsam das popcorn aus, diese diskussion von "cgi"-experten zu verfolgen, ist schon extrem unterhaltend. ;-)
lg
srone
Antwort von TheBubble:
Das Thema 4:2:0 -> 4:4:4 durch Downscaling ist schon mal aufgekommen.
Hier ein Link zu einem Beitrag von mir, der eine Skizze zur Veranschaulichung enthält:
https://www.slashcam.de/forum/viewtopic.php?p=814330#814330
In der Praxis liegen die Chroma-Samples jedoch nicht immer mittig zwischen den Luma-Samples. Wo sie liegen, hängt vom Codec ab.
Antwort von Roland Schulz:
... jetzt kommt noch mal ein richtiger Hammer der die letzte Hoffnung zerlegt!!
Was passiert eigentlich mit der 2 dimensionalen 8bit Farbinformation (U&V), die im prescale 2x2 4:2:0 Pixelblock ja NUR EINMAL "in der Mitte" erfasst und als 8bit gespeichert wurde?!?!
...
Sorry ;-)!!!
wo ist der Hammer??
wir haben hier bei unserem Thema immer von der Luminanz gesprochen. Also vom Y Signal oder von den 3 RGB Signalen. Und alles Gesagte gilt dafür.
Wo ist das Problem?
Gruß Jürgen
Nein, es ging darum dass 4:2:0 im Downscale 4:4:4 wird und einige haben behauptet dass dabei aus 8bit 10bit werden. Ich habe bereits am Luminanzsignal gezeigt dass es keine 10bit werden, maximal unter bestimmten Vorraussetzungen die aber nicht immer gelten, die 10bit Nummer damit keine Allgemeingültigkeit besitzt. Die U/V Komponente hebt die 10bit Annahme dagegen noch eindeutiger aus.
Antwort von Roland Schulz:
Also wo stehen wir: 4:2:0 wird im k=2 Downscale 4:4:4 und 8bit bleibt ~"8bit" - oder nicht?!?!
Ich stehe bei
1. Durch Herunterskalieren von UHD nach HD können im Allgemeinen die Farbinformationen von 4:2:0 nach 4:4:4 verbessert werden, wenn die Skalierung entsprechend gemacht wird
2. Durch Herunterskalieren von UHD nach HD kann im Allgemeinen die Bittiefe von 8 Bit im Luminanzkanal verbessert werden, im Idealfall um 2 Bit, im Allgemeinen um weniger
Alle von dir zitierten öffentlichen Quellen sehen das auch so, nur du bist der Meinung, dass die alle nur zur Hälfte recht haben und die sich alle in der anderen Hälfte täuschen. Das klingt für mich so, als ob du dir genau das heraussuchst was dir gefällt und das andere durch Sentenzen wie "irgendwelche Professoren oder andere "renommierte" zwölfeinhalbtausender Koryphäen" abwerten möchtest.
Gruß Jürgen
Stop, jetzt bleiben wir bitte mal bei der Wahrheit: die "Quellen" haben behauptet dass ... aus 8bit 10bit werden, niemand hat eine Abgrenzung bzgl. der Kanäle gemacht. Für die Farbkomponente ist das aber ganz eindeutig falsch, deshalb gilt es nicht allgemein! Davon ab, für die Luminanzkomponente auch nicht wie mehrfach beschrieben...
Antwort von Roland Schulz:
Das Thema 4:2:0 -> 4:4:4 durch Downscaling ist schon mal aufgekommen.
Hier ein Link zu einem Beitrag von mir, der eine Skizze zur Veranschaulichung enthält:
https://www.slashcam.de/forum/viewtopic.php?p=814330#814330
In der Praxis liegen die Chroma-Samples jedoch nicht immer mittig zwischen den Luma-Samples. Wo sie liegen, hängt vom Codec ab.
Für 4:2:2 ist das richtig, 4:2:0 ist immer in der Mitte - spielt aber auch keine Rolle....
...bin mal kurz in den Thread, Wowu strampelt da ja auch wie verrückt mit Fehlfarben rum ;-) - was bringt das, der Downscale hat pro Pixel am Ende trotzdem eine eigene Farbinformation, deshalb wird es 4:4:4, unabhängig von dem was drin steht!!! Es bleibt 4:4:4 weil keine Unterabtastung mehr im Endsignal ist!!
Antwort von TheBubble:
4:2:0 ist immer in der Mitte - spielt aber auch keine Rolle....
Bei JPEG: ja (Chroma-Samples liegen mittig in einem 2x2 Luma-Sample-Block). Beispielsweise bei MPEG-2: nein (Chroma-Samples sind hier horizontal an jeder 2. Luma-Spalte ausgerichtet, vertikal liegen sie zwischen zwei Luma-Zeilen).
Antwort von Roland Schulz:
4:2:0 ist immer in der Mitte - spielt aber auch keine Rolle....
Bei JPEG: ja (Chroma-Samples liegen mittig in einem 2x2 Luma-Sample-Block). Beispielsweise bei MPEG-2: nein (Chroma-Samples sind hier horizontal an jeder 2. Luma-Spalte ausgerichtet, vertikal liegen sie zwischen zwei Luma-Zeilen).
Richtig, mein Fehler!!! Spielt in dieser Diskussion aber keine Rolle, es macht für das Endergebnis keinen Unterschied, pro 2x2 Block gibt es eine Farbinformation.
Antwort von Roland Schulz:
Ich denke wir machen den Sack mal zu und ich zeige das noch einmal zusammenhängend auf, auch wenn"s schon mehrfach beschrieben wurde:
Zwei Behauptungen stehen im Raum:
1. Aus einem mit 4:2:2 oder 4:2:0 unterabgetasteten Bildsignal soll durch Faktor 2x2 Downscale (horizontale und vertikale Halbierung der Bildauflösung) ein 4:4:4 Bildsignal ohne Unterabtastung entstehen, d.h. im ungünstigeren Fall soll z.B. aus einem 2160 4:2:0 Signal ein 1080 4:4:4 Signal entstehen.
2. Das nach 1. herunterskalierte Bildsignal soll aus einem 8bit Ursprungsbildsignal durch das beschriebene Downsampling eine 10bit Dynamik erhalten.
zu 1.:
Das Quellsignal, welches ein Bild in einer Pixelmatrix mit horizontaler und vertikaler Dimension darstellt, weist eine gängige Farbunterabtastung, hier 4:2:0 auf. Farbunterabtastung selbst ist u.A. in der ITU-R BT.601-5 (früher CCIR 601) beschrieben. Farbunterabtastung wird üblich zur Reduzierung des nativ verursachten Informationsvolumens eingesetzt und obliegt der Annahme, dass das menschliche Auge für Farbinformationen weniger sensibel ist als für Helligkeitsinformationen, der Verlust an Auflösung kaum auffällt.
Nach ITU-R BT.601-5 wird ein Bildsignal im YUV-Farbmodell horizontal wie vertikal um den Faktor zwei bzgl. der Auflösung seines zweidimensionalen UV-Farbanteils reduziert, wenn das Bildsignal zu einem sogenannten 4:2:0 Signal farbunterabgetastet wird. Die Auflösung des Y-Helligkeitsanteils bleibt hierbei unverändert.
Daraus folgt, das im 4:2:0 Signal auf einen horizontal und vertikal jeweils 2 Pixel großen, zusammenhängenden Bereich 2x2 Y-Helligkeitsinformationen und eine zweidimensionale UV-Farbinformation entfällt.
Diese eine UV-Information bestimmt nun gemeinsam die Farbe für die 2x2 zusammenhängend benachbarten Pixel, welche nach wie vor eine individuelle Helligkeit wiedergeben können.
Das Quellsignal setzt sich somit horizontal durch h/2 und vertikal durch v/2 solcher 2x2 Pixel großen Bereiche zusammen, wobei h der horizontalen und v der vertikalen Dimension/Auflösung des Quellsignals entspricht.
Die UV-Farbinformationen der 2x2 Pixel großen Bereiche können zu den benachbarten 2x2 Pixel großen Bereichen individuelle Werte annehmen. Sie stehen untereinander nicht im Zusammenhang.
Soll dieses Signal jetzt wie in der Behauptung beschrieben in der horizontalen und vertikalen Pixelanzahl um den Faktor 2 reduziert werden, entsteht pro 2x2 Pixel großem Bereich jeweils 1 neuer Pixel. Diesem neu entstandenen Pixel liegen 2x2 Y-Informationen aus dem ursprünglichen Quellsignal zugrunde, welche zu einer gemeinsamen, eindimensionalen Y-Helligkeitsinformation verrechnet werden.
Begründet durch die oben beschriebene 4:2:0 Farbunterabtastung liegt aus dem urspünglich 2x2 Pixel großen, zusammenhängenden Bereich eine zweidimensionale UV-Farbinformation vor. Diese Information wird ebenfalls in den neuen Pixel überführt. Der neue Pixel setzt sich also aus einer individuellen Y-Helligkeitsinformationen und einer individuellen UV-Farbinformation zusammen.
Der folgende neue Pixel in der gleichen Zeile besitzt demnach Informationen der folgenden 2x2 Pixel des urspünglichen Quellsignals, wieder zusammengesetzt aus einer individuellen Y-Helligkeitsinformation welche sich aus den ursprünglichen 2x2 Y-Helligkeitsinformationen errechnet und einer zu den bisherigen und folgenden Pixeln unabhängigen UV-Information, welche pro 2x2 Pixelbereich vorliegt.
Dieser Vorgang wird horizontal h/2 und vertikal v/2 mal wiederholt, wobei h für die horizontale und v für die vertikale Dimension/Auflösung des ursprünglichen Bildes steht.
Der jeweilige Quotient 2 ergibt sich aus dem beabsichtigten Faktor des Downscales, welcher hier zudem identisch zur Dimension des 2x2 großen Pixelbereiches ist.
Folglich besitzt jeder neue Pixel des Bildes eine jeweils individuelle Y-Helligkeits- und UV-Farbinformation. Die jeweiligen Helligkeits- und Farbinformationen eines Pixels sind zu den benachbarten Pixeln unabhängig. Das herunterskalierte Bild weist somit keine Unterabtastung mehr auf.
Gemäß der Beschreibung und Definition die u.A. in der ITU-R BT.601-5 festgeschrieben steht erhält man so ein 4:4:4 Bild.
Zusammengefasst entspricht die 4:2:0 UV-Farbinformation, welche horizontal wie vertikal jeweils der halben Dimension/Auflösung des 4:2:0 Quellsignals entspricht, bereits genau der Dimension/Auflösung, welche nach dem Faktor 2x2 Downscale der gesamten Bildauflösung entspricht.
!!!!! Die Anzahl der 4:2:0 Farbinformationen im Bild vor dem k=2 Downscale entspricht bereits der Anzahl der Pixel nach dem Downscale !!!!!
Somit erhält jeder Pixel im Ziel eine eigene, unabhängige Farbinformation. Folglich besteht keine Unterabtastung im Ziel, was per Definition 4:4:4 entspricht.
Behauptung 1. ist folglich gemäß der zugrundeliegenden Definitionen richtig.
zu 2.:
Forderung: Von einem Signal, welchem eine bestimmte Dynamik beigemessen wird ist zu erwarten, dass alle relevanten Komponenten oder Kanäle des Signals mindestens die beigemessene Dynamik aufweisen.
In gegenständlicher Betrachtung wird erwartet, dass ein 8bit Signal nach einem Faktor 2x2 Downscale nach 1. eine Dynamik von 10bit aufweist.
Das gegenständliche Signal ist ein unterabgetastetes 4:2:0 Signal, welches wie in 1. aufgezeigt auf einen Bereich von 2x2 Pixeln jeweils 4 individuelle Y-Helligkeitssignale mit 8bit Auflösung und 1 individuelles, 2 dimensionales UV-Farbsignal mit 8bit Auflösung besitzt.
Durch die Addition der 4 individuellen Y-Helligkeitssignale kann ein Wert erzeugt werden, welcher in einem neuen Pixel nach Downscale tatsächlich einen Wertebereich von vereinfacht betrachtet 10bit abbildet.
Die entstehenden Inkremente von Pixel zu Pixel können auch tatsächlich dem Inkrement einer 10bit äquivalenten Quantisierung entsprechen.
Sind allerdings homogene Bereiche (2x2 Block ausreichend) im Ausgangsbild abgebildet, können die Inkremente von Pixel zu Pixel nur noch den Wert des 4-fachen Inkrementes einer 10bit Quantisierung annehmen, was vereinfacht nur noch dem skalierten Inkrement einer 8bit Auflösung entspricht.
Eine echte 10bit Abtastung könnte auch hier das Inkrement einer 10bit Abtastung abbilden.
Weiterhin steht als Farbinformation vor dem Downscale pro 2x2 benachbarter Pixel eine zweidimensionale 8bit Farbinformation zur Verfügung. Diese geht ohne Veränderung in den nach Downscale neu entstehenden Pixel über.
!!!!! Die Anzahl der 4:2:0 Farbinformationen im Bild vor dem k=2 Downscale entspricht bereits der Anzahl der Pixel nach dem Downscale !!!!!
Eine Dynamikveränderung erfolgt nicht, die Quantisierung bleibt 8bit.
Somit können unter gewissen Umständen 10bit Inkremente bei der nach Downscale entstandenen Helligkeitsinformation vorliegen, als allgemeingültig nachweisbar ist das aber nicht.
Die Farbinformation wird nicht verändert, sie behält immer ihre 8bit Dynamik.
Behauptung 2. ist folglich falsch.
Wer "4:2:0 wird durch Faktor 2 Downscale zu 4:4:4" jetzt immer noch nicht "verstehen will" und das nach wie vor für ein Wunder hält, dem kann und will ich jetzt auch nicht mehr helfen.
Die Betrachtung ist zudem völlig unabhängig von der Art und Weise der Erfassung (durch eine Kamera o.ä.). Die Betrachtung setzt voraus, dass das Quellsignal ein 4:2:0 Signal ist, egal wo es herkommt.
So und nicht anders steht es in der Behauptung.
Den (Un-)Sinn dieses Verfahrens können wir gerne in einer anderen Diskussion ersticken. Hier schließe ich jetzt (zumindest für mich) ab und schmeiß den Schlüssel weg ;-)!
Vielen Dank an all diejenigen die hier kooperativ mitgemacht haben! Denke einige haben dabei vielleicht auch was gelernt, auch mir wurden im Laufe der Diskussion noch mal Sachverhalte deutlich, die ich vorher so gar nicht gesehen hatte.
Das Verhalten vom "allmächtigen Zwölfeinhalbtausender", der hier alles lautstark in Frage gestellt hat und am Ende sicherlich auch überzeugt ist aber heimlich, still und leise in Deckung gegangen ist finde ich dagegen recht schwach. Jeder darf sich irren, Einsicht schadet nicht.
Gruß auch noch mal an die ganzen Professoren und prominenten Menschen auf dieser Welt, die das alles in Frage oder falsch darstellen.
Gruß vom Roland.
Antwort von mash_gh4:
lieber roland!
ich glaube, ich hab da etwas für dich, dass dich evtl. in in deinen gewissheiten und ansichten nicht weniger erschüttern dürfte als wir es uns von anderen kollegen hier im forum hin und wieder wünschen würden. ;)
es hat mir nämlich keine ruhe gelassen, darüber nachzusinnen, wie weit deine annahme von homogenen flächen tatsächlich in praxis anzutreffen ist, oder ob das nicht viel mehr ein ähnliches trugbild darstellt, wie es andere hier regelmäßig ausbreiten.
ich hab also einfach zwei testaufnahmen mit meiner gh4 gemacht und aus dem ffmpeg daaus mit folgendem befehl ein 16bit graustufenbild exportiert, das nur die information im Y-kanal enthält:
ffmpeg -i P1250334.MOV -ss 5 -vframes 1 -vf extractplanes=y -pix_fmt gray16le bild1_4k.png
zum Bild http://users.mur.at/ms/attachments/dither/bild1_4k.klein.png
zum Bild http://users.mur.at/ms/attachments/dither/bild2_4k.klein.png
(einfach draufklicken, um es in originalgrößer downzuloaden)
zum vergleich habe ich dann die videos auf ein viertel verkleinert und in gleicher weise bilder generiert:
ffmpeg -i P1250334.MOV -ss 5 -vframes 1 -vf extractplanes=y -pix_fmt gray16le -vf scale=size=hd1080:sws_dither=none:flags=bitexact bild1_2k.png
zum Bild http://users.mur.at/ms/attachments/dither/bild1_2k.klein.png
zum Bild http://users.mur.at/ms/attachments/dither/bild2_2k.klein.png
die bilder enthalten natürlich keine besonders aufregende information, sondern wurden vielmehr völlig unscharf, d.h. mit gänzlich falscher fokusierung, von einem ausdruck mit horizontalen sinusmustern abgefilmt, um möglichst fließende übergänge im bild zu erhalten. ganz ideal ist das allerdings ohnehin nicht gelungen, weil vermutlich ein noch subtilerer übergang aussagekräftiger wäre. das erste bild wurde mit 800 ISO und standard profil aufgenommen, während im zweiten fall 200 ISO und Cine-D verwendet wurde.
aus diesen bildern habe ich jeweils in der mitte eine horizontale zeile herausgegriffen und deren werte genauer untersucht.
auf den ersten blick schaut das ja noch recht unspektakulär aus:
zum Bild
zum Bild
spannend wird es erst, wenn man in die graphen ein klein wenig rein zoomt:
zum Bild
als kenner entsprechender moderner kunst, brauche ich dir vermutlich nicht lange zu erklären, warum das dortige 8bit signal genau diese eigenartige, auf den ersten blick etwas unansehnliche form zeigt. das sind genau jene muster, die ich mit literaturverweisen unter dem stichwort: "dithering" hier ohnehin bereits ein paar mal anzusprechen versucht habe.
allerdings muss ich zugeben, dass ich mir selbst nicht ganz sicher war, ob ich derartiges im entpackten signal einer hoch komprimierten kameraufzeichnung finden werde? es wäre ziemlich spannend, es auch noch mit unverarbeitetem material direkt aus der kamera zu vergleichen. es könnte sich ja durchaus auch um dithering auf seiten der ffmpeg dekompression handeln könnte, um errechnete zwischenwerte bspw. im deblocking prozess im 8bit resultat adäquat wiederzugeben.
was es aber auf jeden fall unverkennbar belegt, ist die tatsache, dass du mit deiner etwas vereinfachenden vorstellung homogener flächen in den videodaten an der praxis ziemlich weit vorbeizielen dürftest. ich fürchte, in dem punkt unterliegst du genauso sehr einem viel zu einfach gedachtem gedankenmodell, wie wir das gerne anderen ankreiden. ich kann das aber natürlich bestens nachvollziehen. trotzdem: genau solche geschichten, die man auf den ersten blick nicht erwarten würde, machen die dinge doch erst spannend! ;)
ich glaube ganz generell, dass die dithering problematik von sehr vielen kollegen viel zu achtlos beiseite geschoben oder gar nicht erst verstanden wird, obwohl sie in der praxis kaum weniger bedeutsamkeit haben dürfte als 8 od. 10bit auflösungsbeschränkung und verarbeitungsmöglichkeiten.
ein kleines bild kann ich noch anfügen -- obwohl es eigentlich nicht sehr viel unerwartetes enthält:
zum Bild
das ganze ist übrigens wirklich ausgesprochen einfach mit ein paar zeilen python auch praktisch nachzuvollziehen:
#!/usr/bin/env python
import numpy as np
from scipy import misc
import matplotlib.pyplot as plt
bild_4k = misc.imread('bild2_4k.png')
line_4k = bild_4k[1080] >> 6
bild_2k = misc.imread('bild2_2k.png')
line_2k = np.repeat(bild_2k[540], 2) >> 6
plt.plot(line_4k, drawstyle='steps', color='cyan', label='uhd2160')
plt.plot(line_2k, drawstyle='steps', color='red', label='hd1080')
plt.xlabel("Horizontale Position des Pixels")
plt.ylabel("10bit Y-Signal")
#plt.magnitude_spectrum(line_4k, scale='dB', color='cyan', label='uhd2160')
#plt.magnitude_spectrum(line_2k, scale='dB', color='red', label='hd1080')
plt.legend()
plt.show()
obwohl ich nach diesem praktischen durchprobieren meine erste neugierde wieder ein wenig gestillt habe, getraue ich mich keineswegs zu behaupten, die sache damit bereits verstanden zu haben und klar beurteilen zu können. als kleine anregung zum weiterdenken, könnte es aber vielleicht auch für andere hier von interesse sein.
Antwort von Roland Schulz:
lieber roland!
ich glaube, ich hab da etwas für dich, dass dich evtl. in in deinen gewissheiten und ansichten nicht weniger erschüttern dürfte als wir es uns von anderen kollegen hier im forum hin und wieder wünschen würden. ;)
.
.
.
.
Lieber mash_gh4,
...was in aller Welt willst Du uns hiermit eigentlich sagen?!?!
Nicht böse gemeint, aber ich erkenne keine Aussage in Deinem letzten Posting.
Soll das bedeuten dass ein verrauschtes Signal EINER Kamera beweist, dass kein 4:2:0 Signal dieser Welt in einem 2x2 Block gleiche Helligkeitswerte annehmen kann?! Ist technisch per Definition ausgeschlossen, dass in einem 8bit 4:2:0 Bild benachbarte Pixel den gleichen Wert annehmen dürfen?!
(Davon ab, in Deinem Y-Graph sind JEDE MENGE Bereiche, in denen die Linie parallel zur x-Achse verläuft! Jetzt müssten wir noch den Graph der nächsten Zeile darüber legen und die Stellen markieren, an denen sich parallel zur x-Achse verlaufende Bereiche decken. Da haben wir dann in zwei Zeilen homogene Bereiche, aus denen nie eine höhere Dynamik als 8bit rekonstruierbar wird! Wenn Du nochmal ein Bild deiner GH4 nehmen willst, fahre die Belichtung mal weiter runter, dann findest Du ganz schnell SEHR VIELE solcher Bereiche...)
Soll das heißen dass aus einem in Photoshop generierten X:X:X UHD 8bit Grauverlauf OHNE Dither und Schickimicki durch Downscale eine 10bit Information gewinnbar ist?
Soll es heißen dass die 8bit UV Information eigentlich doch 10bit Dynamik aufweist?!
Sorry, aber ich weiß wirklich nicht was Du zeigen möchtest...
Fest steht, aus einem 8bit 4:2:0 Bild wird durch Halbierung der horizontalen wie vertikalen Auflösung ein 8bit 4:4:4 Bild mit halben Dimensionen!
Antwort von HJS:
lieber roland!
... wie weit deine annahme von homogenen flächen tatsächlich in praxis anzutreffen ist, oder ob das nicht viel mehr ein ähnliches trugbild darstellt, wie es andere hier regelmäßig ausbreiten.
Hallo mash,
vielleicht wird unsere Diskussion hier doch noch mal interessant!
Also deine Skepsis bezüglich der homogenen Flächen teile ich. Rolands Argument, dass für diese Flächen die Überlegung der Dynamikerhöhung (8 auf 10 Bit) der Luminanz nicht gilt, ist sicher richtig. Und ich habe auch bisher keine theoretische Erklärung. Es ist wohl so, dass eine graue Fläche ja praktisch keine Information trägt und spektral nur die Ortsfrequenz Null in allen Richtungen der Fläche hat. Dadurch ist dieses Beispiel ein sehr exotisches Beispiel (aber natürlich zulässig).
Mich würde auch interessieren, wie du deine Bilder interpretierst. So ganz habe ich es noch nicht verstanden. Was sofort auffällt ist, dass die sinusförmigen Luminazverläufe der Zeilen bei den HD Bildern ein deutlich geringeres Rauschen zeigen als die UHD Bilder. Wie interpretierst du das?
Deine Verweise an das Dithering habe ich bisher noch nie kommentiert, weil ich da keinen Zusammenhang zu unserem Thema sehe. Denn wenn ein Bild "gedithert" ist, sind die Effekte, die wir hier diskutieren, doch wohl kaum noch zu erkennen?? Das dithering überlagert doch alles. Es gibt ja auch sehr viele unterschiedfliche Algorithmen und es ist kaum auszumachen, welche ein Kamerahersteller eventuell implementiert hat.
Gruß Jürgen
Antwort von Roland Schulz:
lieber roland!
... wie weit deine annahme von homogenen flächen tatsächlich in praxis anzutreffen ist, oder ob das nicht viel mehr ein ähnliches trugbild darstellt, wie es andere hier regelmäßig ausbreiten.
Hallo mash,
vielleicht wird unsere Diskussion hier doch noch mal interessant!
Also deine Skepsis bezüglich der homogenen Flächen teile ich. Rolands Argument, dass für diese Flächen die Überlegung der Dynamikerhöhung (8 auf 10 Bit) der Luminanz nicht gilt, ist sicher richtig. Und ich habe auch bisher keine theoretische Erklärung. Es ist wohl so, dass eine graue Fläche ja praktisch keine Information trägt und spektral nur die Ortsfrequenz Null in allen Richtungen der Fläche hat. Dadurch ist dieses Beispiel ein sehr exotisches Beispiel (aber natürlich zulässig).
Mich würde auch interessieren, wie du deine Bilder interpretierst. So ganz habe ich es noch nicht verstanden. Was sofort auffällt ist, dass die sinusförmigen Luminazverläufe der Zeilen bei den HD Bildern ein deutlich geringeres Rauschen zeigen als die UHD Bilder. Wie interpretierst du das?
Deine Verweise an das Dithering habe ich bisher noch nie kommentiert, weil ich da keinen Zusammenhang zu unserem Thema sehe. Denn wenn ein Bild "gedithert" ist, sind die Effekte, die wir hier diskutieren, doch wohl kaum noch zu erkennen?? Das dithering überlagert doch alles. Es gibt ja auch sehr viele unterschiedfliche Algorithmen und es ist kaum auszumachen, welche ein Kamerahersteller eventuell implementiert hat.
Gruß Jürgen
Also, eine allgemeine Behauptung wie "8bit 4:2:0 wird nach Halbierung der Dimensionen 10bit 4:4:4" gilt nur, wenn es unter allen Voraussetzungen gilt.
Ich habe mehrere Gründe aufgezeigt, warum 8->10bit nicht gilt.
Warum haltet ihr Euch immer noch an Kamerabildern etc. fest?
Schon ein UHD 8bit Graukeil zeigt eindeutig, dass homogene Flächen auftreten, damit gilt die Annahme bereits nicht mehr allgemein!
Wenn wir über 3840 horizontale Pixel einen linearen 8bit Verlauf von Y=0 - 255 legen, besitzen horizontal bereits 15 Pixel die gleiche Luminanz, vertikal 2160 Pixel!!! Du kriegst Flächen mit 15x2160 Pixeln!!
Diesen Graukeil kriege ich 100%ig in 4:2:0 abgebildet, es ist technisch nicht ausgeschlossen. Er wird nach Downscale in einen 10bit Wertebereich aber die gleichen Abstufungen zeigen wie zuvor, lediglich die Kanten werden "verändert". Es bleiben 256 Abstufungen, das Inkrement beträgt das Vierfache eines 10bit Inkrements, also die 4fache Skalierung eines 8bit Inkrements!
Ein echter 10bit Graukeil würde in der skalierten 1920 Horizontalen 1024 Abstufungen zeigen!
Eine Downscale in 10bit zeigt sicherlich hier oder da einen überschaubaren Vorteil, es ist aber keinesfalls mit einem echten 10bit Signal vergleichbar!
Allein die Tatsache dass die Farbkomponente "nur" 8bit besitzt und behält schließt die allgemeine Behauptung aus! Es bleibt ein 8bit Signal!!
Antwort von Roland Schulz:
Jetzt nochmal "in einem Satz" vereinfacht und mit "Bildern"...
zum Bild
PDF dazu:http://www.rhs-net.com/misc/420zu444.pdf
Antwort von domain:
Also für mich kristallisiert sich immer mehr heraus, dass beim Downscaling formal tatsächlich 444 entsteht.
Aber was hilft das Formale?
Auch transkodiert in den 10-Bitraum werden weder die Farben, noch die Luminanzwerte in differenzierteren Unterstufen dargestellt, es sei denn, Dithering kommt zum Einsatz, was WoWus Reinheitsgebot allerdings fundamental entgegenstehen würde, mich aber nicht sehr juckt.
Ich habe nichts gegen intelligent interpolierte (manche sagen erfundene) Zwischenwerte, solange sie gut aussehen.
Antwort von Rudolf Max:
Hallo Roland Schulz,
Endlich mal jemand, der es versteht, den Sachverhalt auf einfache und logische Art bildlich darzustellen... (war längst überfällig...)
Din Bild sagt mehr als all das andere Geschwafel und all die Formeln, die ausser Ermüdung (für mich...) kaum Sinn machen...
Danke dir...
Rudolf
Antwort von Jott:
Gutes Stichwort. Gut aussehen. UHD 4:2:0 8Bit in einer HD 10-Bit-Timeline sieht sehr gut aus und lässt sich auch gut graden (letztes Jahr haben wir für eine Airline gedreht, sehr viel Himmel und Sunsets, kein Banding). Das kann man einfach für sich selbst zur Kenntnis nehmen oder sich seitenlang streiten, warum das so ist, oder dass es gar nicht sein kann - jeder wie er mag.
Interessante Betrachtungen jedenfalls.
Antwort von mash_gh4:
ich wollte das ganze ursprünglich ohnehin mit synthetisch generierten verläufen machen. da kann man das alles viel einfacher und deutlicher zeigen. allerdings verliert sich dabei schnell die frage, ob man derartigem auch in der praxis begegnen wird?
wir kennen alle das problem, das gerade diese ganz einfachen farbverläufe in grafikeinblendungen und anime die unguteste banding-neigung zeigen. man versucht das in der praxis häufig zu mildern, indem man ein klein wenig rauschen drüber legt (od. deutlich ausgefeiltere debanding-filter benutzt). das befriedigt zwar das auge des betrachters ein wenig, hat aber mit dithering im engeren sinne noch nicht viel zu tun. spannend wird es erst dort, wo man einen entsprechenden verlauf bzw. ausgagngsdaten tatsäch in höherer bittiefe zur verfügung hat und vor dem requantisieren mit einer in seiner intensität ganz genau anzugebenden störquelle mischt. das erweist sich ausgesprochen vorteilhaft und minimiert die quantisierungsverzerungen. im resultierenden signialverlauf zeigt es sich dann allerdings genau diesen charakteristisch ausgefransten stufen, die ein wenig an pulsweitenmodulierte signale erinnern. aber auch ohne derartige artifizielle hilfsmittel erkennt unterschied unweigerlich daran, dass das zeug plötzlich nicht mehr in gleicher weise von contouring/banding geplagt wird.
was allerdings deutlich gegen das dithern spricht, ist dessen unverträglichkeit mit den meiste kompressionsmethoden. es wäre viel effizienter die ursprünglichen 10bit daten sauber in all ihren abstufungen durchzureichen, als diese wirren muster. allerdings gibt es auch spezielle komprimierungstechniken, die dem rechnung tragen und das bild bzw. dessen informationsgehalt ein klein wenig anders analysieren und umschreiben.
wenn man diese ganze problematik völlig ausklammert, in einem 10bit produktiunsumfeld arbeitet und beim abschließenden 8bit export nicht dithert, sehen die resultate garantiert katstrophaler aus als im billigen amateurumfeld. das ist zum glück aber gar nicht so einfach zu bewerkstelligen, weil unsere programme -- aber eben auch die meisten realen kameras! --, dafür gewöhnlich schon sorge tragen. es gibt ja zum glück entwickler, die um derartige dinge bescheid wissen und dem einfachen anwender alle weiteren mühen abnehmen.
so bald man es aber mit derart aufbereitetem material zu tun hat, ist es mit deinen homogenen flächen vorbei. deshalb auch diese ganz praktischen auswirkungen beim skalieren in der realen welt. sich hier partout an einfachere vorstellungen von einem schönen unverfälschten signal festzuklammern, weil ja alles andere einfach nur böses "rauschen" ist, wirkt auf mich kaum weniger naiv als die allseits bekannten dogmen theoriebegeisterter anderer kollegen hier im forum.
die ganze geschichte ist aber leider wirklich nicht so einfach zu durchschauen. wenn ich ein bisserl zeit finde, kann ich evtl. anfang nächster woche noch ein paar synthetische generierte beispiele nachreichen, um vor allen dingen auch die rolle der kompression in diesem zusammenhang deutlicher herauszuarbeiten. die nächsten zwei tage werde ich mich allerdings leider aus dieser wunderbar anregenden diskussion hier zurückziehen müssen und mich wieder einmal ein bisserl mehr in realer naturbetrachtung üben, ;)
Antwort von Roland Schulz:
Wie mehrfach auch von mir beschrieben bringt es Vorteile, bei einem Downscale in eine 10bit Dynamik zu skalieren - es wird aber nie die Vorteile eines echten 10bit Signals erreichen, im Chromasignal schon gar nicht!
Antwort von Jott:
Ist auch gar nicht notwendig. 8Bit-Kameras erzeugen per se kein Banding, mit solchen Exemplaren wurden schon genug Spielfilme gedreht, und Fernsehen klappt ja auch. Das nur am Rande.
Überführt man - wovon wir hier reden - UHD 4:2:0 8-Bit in eine HD-10Bit-Tineline und dreht dann an Farben, geht das jedenfalls besser, als wenn man in 8 Bit geblieben wäre. Das mag natürlich auch wieder NLE-spezifisch sein, aber in dieser Richtung mal rumzuspielen bleibt jedem unbenommen.
Antwort von Jan:
Da bei 4:2:0 die Farbwerte der umliegenden Pixel für die Farbe des aktuellen Pixels genommen werden, also interpoliert wird, kann beim bloßen Zusammenlegen kein reines 4:4:4 enstehen. Das zeigen dann auch die Testbilder vor einigen Beiträgen, wo etwas vorher interpoliert wurde, kann man später nicht das Signal als vollwertig aufgezeichnetes Material kennzeichnen.
Das erinnert mich an die Fuji EXR-Sensor-Technik, der eine gleichmäßige Pixelanordnung (blau ist genau neben blau, rot neben rot und grün neben grün, nicht wie bei der Bayermatrix verstreut). Diese Sensoren hatten eine Auflösung von 12 Millionen Pixel und konnten durch das Zusammenfassen von den zwei gleichen Pixeln die nebeneinander sind, sechs "große" Millionen Pixel machen. Leider war das Theorie und es kam effektiv nur eine 10-20% verbesserter Lichtempfindlichkeit dazu.
VG
Jan
Antwort von Valentino:
Kann Wolfgang ganz gut verstehen das er hier nicht mehr gegen Windmühlen ankämpfen will.
Alles nette Theorie was ihr da so schreibt, es bleibt aber leider nur Theorie.
Alleine schon die Tatsache, das aus einem 4k Bayer Sensor keine echten 4k RGB zu generieren sind und dazu noch der OLPF und andere Filter in die Suppe spucken, macht es so gut wie unmöglich ein echtes 4k Bild zu generieren.
Die Sache mit dem Bildrauschen und Qualitätsverluste durch das Objektiv darf man bei der Sache auch nicht einfach so unter den Tisch kehren.
Am Ende habt ihr ein 4k Container mit gerade mal einer realen Auflösung von 2 bis 3k, wie ihr daraus ein sauberes HD Bild mit 444 erzeugen wollt kann hier leider keiner erklären.
Ihr verwechselt hier auch öfters das Binning auf Sensorebene mit einem späteren Downscaling, das sind zwei völlig verschiedenen paar Schuhe und können niemals zum gleichen Ergebnis führen.
Mit ein paar Formeln und synthetischen Werten rechnet es sich immer schöner als mit Werten aus der Praxis.
Leider kommt man an dieser bei Video nicht herum, außer man bleibt bei reiner CGI, was aber im Grunde gar kein Video ist.
Ihr könnt hier gerne noch mal zwanzig Seite voll schreiben, aber es wird dadurch nicht richtiger!
Antwort von StanleyK2:
rKann Wolfgang ganz gut verstehen das er hier nicht mehr gegen Windmühlen ankämpfen will.
Alles nette Theorie was ihr da so schreibt, es bleibt aber leider nur Theorie.
...
Mit ein paar Formeln und synthetischen Werten rechnet es sich immer schöner als mit Werten aus der Praxis.
Leider kommt man an dieser bei Video nicht herum, außer man bleibt bei reiner CGI, was aber im Grunde gar kein Video ist.
Ihr könnt hier gerne noch mal zwanzig Seite voll schreiben, aber es wird dadurch nicht richtiger!
Wie wahr. Ich hab da durchaus einen technisch-/wissenschaftlichen Hintergrund. Aber andererseits auch real existierende Kameras/Camcorder und Software. Und das ist für die Praxis entscheidend.
Interessant wären manche Fragen, wenn man Camcorder-Firmware, Codecs oder NLE programmiert. Macht das hier zufällig jemand?
Oder alles nur Sommerloch ...
Antwort von Valentino:
Man muss kein Programmierer sein um das alles zu Verstehen und ein nicht ganz so kleiner Anteil an der ganzen Kameratechnik ist und bleibt auch im digitalen Zeitalter der analoge Teile von der Optik über den Sensor, den erst danach findet die A/D Wandlung statt.
Auch wenn es Erbsenzählerei ist, es sind digital aufzeichnende Kameras und keine Digitalkameras ;-)
Aber am Ende ist es einfach nur das Sommerloch und ich bin immer wieder erstaunt wieviel Zeit hier einige User bei dem Wetter ins Schreiben investieren.
Antwort von wüdara:
"
Aber am Ende ist es einfach nur das Sommerloch und ich bin immer wieder erstaunt wieviel Zeit hier einige User bei dem Wetter ins Schreiben investieren."
Die Forum-Betreiber haben ihre helle Freude...viele Einträge!
Paragraph 1: Ich hab immer Recht
Paragraph 2:Sollte ich -ausnahmsweise -einmal nicht recht haben,dann tritt automatisch Paragr.1 in Kraft! :-))
Antwort von WoWu:
Ich will ins Sommerloch nicht wirklich neu einsteigen, aber Roland trägt hier Phantasiegrafiken vor, die bestenfalls noch für monochromatische Flächen einen gewissen Grad an Gültigkeit haben, zur Klärung des vorliegenden Sachverhalts aber nicht beitragen können, weil die meisten Videos Chromanteile haben und werde dieser Umstand hier natürlich zum Tragen kommt.
Aber bevor sich solche falschen Grafiken weiter verbreiten, sollte man einen Blick darauf werfen, wie es wirklich funktioniert:
Er reduziert jedoch nur monochroma, wie in Beispiel A dargestellt,
richtig ist aber, dass ein Prozess nach Beispiel B abläuft
und als Ergebnis daraus das Beispiel C entsteht, das ohne jeden Zweifel den ursprünglichen 4:2:0 Fehler im Bild enthält.
Ergebnis ist also ein 2:2:0 Bild incl des Fehlers aus der ersten Abtastung.
Ansonsten müsste die obige Formel falsch sein ....
Also, wo ist die Formel falsch und wie muss sie richtig lauten ?
Antwort von srone:
Mit ein paar Formeln und synthetischen Werten rechnet es sich immer schöner als mit Werten aus der Praxis.
Leider kommt man an dieser bei Video nicht herum, außer man bleibt bei reiner CGI, was aber im Grunde gar kein Video ist.
Ihr könnt hier gerne noch mal zwanzig Seite voll schreiben, aber es wird dadurch nicht richtiger!
:-), siehe oben.
lg
srone
Antwort von nic:
Nur, was hätte eine FHD 444-Kamera bei den mittleren Pixeln in Beispiel C angezeigt, wenn die Farbkante durch die Sensel verläuft? Jede aufgezeichnete Farbe ist eine "Falschfarbe"... hier stellt sich nur die Frage ob die Interpolation das visuell gleiche Ergebnis wie die analoge Farbmischung bei halbierter Sensorsuflösung liefert...
Antwort von WoWu:
Jedes Pixel ist nur in der Lage einen einzigen Wert darzustellen. Farbkanten innerhalb eines Pixels sind nicht darstellbar (bei keiner Kamera).
Ausserdem betreten wir hier ein weiteres Problem, dass in der "idealisierten downscaleuwelt" auch komischerweise nicht vorkommt.
Eine Interpolation wird dann geradlinig unter Verwendung des gleichen Skalierungsfaktor auf den drei Komponenten durchgeführt.
Die RGB zu YCbCr-Konvertierung ist relativ rechenintensiv, bei Verwendung der eigentlich dafür vorgesehenen Formel:
Y= 0.299R + 0.587G + 0.114B
Cr= V= (R-Y)*0.713
Cb= U= (B-Y)*0.565
Um Rechenleistung effizienter zu nutzen, beschränken sich die Hersteller in Hardware auf Pixelshift:
Y = R/4 + G/2 + B/4
Cr= V= (R-Y)/2
Cb= U= (B-Y)/2
Das gleiche für YCbCr nach RGB:
R = Y + 1.403V
G = Y - 0.344U - 0.714V
B = Y + 1.770U
Und auch hier wieder die Pixelshift Variante für Hardware:
R= Y+2V
G = Y-U/2-V/2
B = Y+2U
Das führt aber dazu, dass es dabei eine Farbverfälschungen gibt.
Bild Links in YCbCr und dann zurück zu RGB.
Die Farben erscheinen etwas heller.
Das kommt daher, dass der Algorithmus immer zwei Viertel der mittleren Eingangspixel verwenden und jede der anderen zwei nächsten Eingabepixel nur einen Teil.
Zum Beispiel, um zu berechnen E0, 2 Teile E, 1 Teil D und 1 Teil B für die Interpolation verwendet. Dies stellt zusätzlich eine Kantenschärfung im skalierten Bild dar. Deswegen sehen die downscalierten Bilder auch immer so knackig aus und jeder Laie, der zwischen Bildinformation und Kantenschärfung nicht unterscheiden kann, hält sie für schärfer.
Aber da steige ich nicht zusätzlich ein. Dann lieber Sommerloch am Pool.
Ach... vergessen ...noch eine Frage:
Welches NLE war das doch gleich, das in der Timeline nur Y aber nicht CbCr unterabtastet ?
Antwort von srone:
@7nic
interessanter aspekt, jedoch ist das eine die systemgrenze, das andere eine interpolation, bei deinem extrembeispiel, werden beide falschliegen, das rechtfertigt jedoch nicht obige behauptung.
lg
srone
Antwort von Roland Schulz:
Ich will ins Sommerloch nicht wirklich neu einsteigen, aber Roland trägt hier Phantasiegrafiken vor, die bestenfalls noch für monochromatische Flächen einen gewissen Grad an Gültigkeit haben, zur Klärung des vorliegenden Sachverhalts aber nicht beitragen können, weil die meisten Videos Chromanteile haben und werde dieser Umstand hier natürlich zum Tragen kommt.
Aber bevor sich solche falschen Grafiken weiter verbreiten, sollte man einen Blick darauf werfen, wie es wirklich funktioniert:
Er reduziert jedoch nur monochroma, wie in Beispiel A dargestellt,
richtig ist aber, dass ein Prozess nach Beispiel B abläuft
und als Ergebnis daraus das Beispiel C entsteht, das ohne jeden Zweifel den ursprünglichen 4:2:0 Fehler im Bild enthält.
Ergebnis ist also ein 2:2:0 Bild incl des Fehlers aus der ersten Abtastung.
Ansonsten müsste die obige Formel falsch sein ....
Also, wo ist die Formel falsch und wie muss sie richtig lauten ?
Wenn Du mal reingeschaut hättest wäre Dir aufgefallen dass die Phantasiegrafiken für 4:2:0 und 4:4:4 so in den Normen und an fast jeder Straßenecke stehen, zudem auch in "Deiner" Grafik sinnbildlich gleich sind!
Am Sachverhalt ändert auch die Position der Abtastung der Farbkomponente und Dein ständiges, unbewiesenes Infragestellen nichts.
3. aus meiner Grafik bzw. die rechte Abbildung in Deiner Grafik ist eindeutig und ohne jeden Zweifel ein 4:4:4 Bild, ist Dir eigentlich klar was das ist?!?! Das Ergebnis ist eindeutig! Kein Pixel und keine Information steht mit einem anderen in Zusammenhang, lediglich dass sie gemeinsam zu einem 4:4:4 Bild gehören! Es sind individuelle Werte!! Das ist die Definition hinter 4:4:4!!
4:X:X bedingt keine "Abtastung" bei der Darstellung eines Signal (wo steht das??), es drückt lediglich die "Farbunterabtastung" bei der Möglichkeit der Abtastung, Abbildung, Übertragung, Speicherung bzw. Darstellung aus! Schon mal festgestellt dass selbst Monitore und TV Geräte hier Grenzen bei der Bandbreite am Eingang aufweisen und viele Geräte z.B. kein 60p UHD in 4:4:4 oder RGB darstellen können?!?! Da sieht der Windows Desktop in Details (Text) mitunter etwas bescheiden aus! Hat da jetzt einer den Inhalt des Grafikspeichers "abgefilmt!?!
Meine Darstellung und der Prozess ist richtig und anwendbar, ist hier eigentlich mal einem klar geworden dass ihr technische "Definitionen" und einfachste Mathematik in Frage stellt?!?! Der Beweis steckt bereits in der Definition zu 4:2:0! Das Chromasignal liegt bei 4:2:0 bereits genau in der Matrix vor, wie sie nach dem Faktor 2 Downscale benötigt wird, und das auch in Deiner Darstellung!! Das ist der Beweis per Definition!!
B und C aus Deiner Grafik kannst Du bei einem Faktor 2 Downscaling vergessen, es existiert kein Belang so vorzugehen!
Es gilt aus 4:2:0 wird durch Halbierung der horizontalen und vertikalen Dimension 4:4:4, ob es euch schmeckt oder nicht oder ihr es bis zu eurem Tod in Frage stellt!
Was von (fast) allen hier berechtigt in Frage gestellt wird ist ob ein technisches Signal nach dem Prozeß "echtes" 4:4:4 ist - die Antwort würde ich auch in fast jedem Fall mit NEIN bewerten - weil"s am Anfang nämlich auch kein "echtes" 4:2:0 (Bayer Kamera o.ä.) war! Auch das habe ich schon mehrfach angebracht! Echtes 4:2:0 würde bedeuten die Systemgrenze zu 100% auszuloten. Dass das fast unmöglich ist und auch nicht unbedingt erstrebenswert ist (u.A. Gefahr von Aliasing etc.) sollte bekannt sein.
Zudem stelle ich wiederholt den (Un-)Sinn eines solchen Downscalings in Frage!
Das ändert aber nichts daran dass echtes 4:2:0 im Faktor 2 Downscale zu echtem 4:4:4 wird, wie hier immer noch falsch in Frage gestellt wird!!
Dass es so unendlich schwer ist einen Irrtum einzusehen...
Antwort von WoWu:
Alles klar, träum weiter.
Ach ja, die Frage nach dem NLE, das asymmetrisch unterabtastest ?
Welches war das doch gleich ?
Antwort von Roland Schulz:
Alles klar, träum weiter.
Ach ja, die Frage nach dem NLE, das asymmetrisch unterabtastest ?
Welches war das doch gleich ?
..."Glaust Du auch es ist ein Traum?! - Du warst schon immer ein ......, ICH SEH DAS ANDERS!!"
Zitat aus "Zwei bärenstarke Typen" - ...und es ist anders! SORRY!! Klar unterhalb der Gürtellinie, auch nicht so gemeint, passte nur gerade zu unseren hart verschiedenen Ansichten und deiner Provokation ich sei ein Träumer...
...bei Deinen Darstellungen muss man zur späteren Stunde erstmal dahinter kommen was womit gemeint ist, ist alles nicht unbedingt mit rotem Faden durchgängig strukturiert und be- bzw. überschrieben. Obwohl"s für die Sache belanglos ist hab ich mir trotzdem die Mühe gemacht um dahinter zu kommen was in "C" Deiner 22:24 Mail dargestellt ist, ne gelbe Linie ist für mich nicht mehr wirklich "auffällig" gewesen:
Den Downscaler kannste einmotten, er ist so belanglos!
Selbst wenn irgend ein "Fehler" im 4:2:0 vorlag und sich ins 4:4:4 übertrug war es per Definition immer noch 4:2:0 (keine Regel/Definition verletzt) und es wird per Definition immer noch 4:4:4 weil jeder Pixel vollständig individuell ist, mehr sagt 4:4:4 nicht aus!!
Auch mit einer 3-Chip 4:4:4 Kamera kannst Du eine Kante nicht sauber darstellen, die wurde ebenfalls gestern bei einem rot/grün Übergang vielleicht gelb und heute i.d.R. grau!
Die "Falschfarbe" ist da genau so vorhanden, wenn der Bereich auch schmaler ist! Dann gibt es deshalb jetzt auch kein 4:4:4 mehr?!?!
Das hat mit der Farb-/Unterabtastung per Definition überhaupt nichts zu tun! Du kurvst immer um den Pudding um irgendwas auszugraben und alte Leute vorn Nachttisch zu schubsen. Amüsante Versuche, so alt bin ich noch nicht und lach' mich schon wieder rund und scheckig!!
Wie gesagt, "ich" stehe fest auf dickem Eis und wackeln tut an meiner Darstellung und Aussage auch nichts!!!
NLE: Kurzzeitgedächtnis??! Hatte ich ebenfalls ganz zu Anfang bereits in Frage gestellt sowie den Sinn der ganzen Sache hier überhaupt (!!), ändert aber nichts an der Tatsache dass 4:2:0 durch h/v Halbierung 4:4:4 wird, ganz einfach per Definition, ohne Kameras und ohne Träumen!!
P.S.: Versuch"s mit FFMPEG und "nearest neighbor"...
Antwort von HJS:
Nur, was hätte eine FHD 444-Kamera bei den mittleren Pixeln in Beispiel C angezeigt, wenn die Farbkante durch die Sensel verläuft?
das ist die genau die richtige Frage!
WOWU antwortet:
"Farbkanten innerhalb eines Pixels sind nicht darstellbar (bei keiner Kamera)"
Das ist ja trivial.
Geht man von einer 3-Sensor HD Kamera aus, dann werden in diesem Beispiel (Kante verläuft genau in Senselmitte) die Sensel des für Rot zuständigen Chips und die für grün zuständigen jeweils zur Hälfte beleuchtet. Das ergibt wieder "Gelb" als Ergebnis im Bild.
Das heißt, eine 444 HD Kamera würde in diesem Beispiel genau das gleiche Ergebnis liefern wie die Herunterskalierung.
Gruß Jürgen
Antwort von Roland Schulz:
Nur, was hätte eine FHD 444-Kamera bei den mittleren Pixeln in Beispiel C angezeigt, wenn die Farbkante durch die Sensel verläuft?
das ist die genau die richtige Frage!
WOWU antwortet:
"Farbkanten innerhalb eines Pixels sind nicht darstellbar (bei keiner Kamera)"
Das ist ja trivial.
Geht man von einer 3-Sensor HD Kamera aus, dann werden in diesem Beispiel (Kante verläuft genau in Senselmitte) die Sensel des für Rot zuständigen Chips und die für grün zuständigen jeweils zur Hälfte beleuchtet. Das ergibt wieder "Gelb" als Ergebnis im Bild.
Das heißt, eine 444 HD Kamera würde in diesem Beispiel genau das gleiche Ergebnis liefern wie die Herunterskalierung.
Gruß Jürgen
Davon ab, ob's wirklich "heute noch" gelb wird stelle ich in Frage, das liegt an der Qualität der Algorithmen die zur Anwendung kommen. Ich behaupte es ist aktuell in der Regel eher monochrom, aber das ist genau so eine Behauptung wie das es gelb wird. Niemand schreibt seinen Algorithmus vor, er ist nicht allgemeingültig!
Wolfgang eiert ohnehin immer gerne um den heißen Brei um abzulenken, wie bringt uns hier die RGB -> YCbCr Transformation weiter, das ist hier reinste Beschäftigungstherapie und nicht zielführend!!
Meine vier Fragen hat er bis heute nicht beantwortet - ich reduziere sie auf eine: was bedeutet 4:4:4, ohne das jetzt wieder auf irgendwelche natürlichen Quellen etc. zu beziehen???!!!
Was ist 4:4:4 per Definition??? Wir sind hier längst fertig!!!
Antwort von HJS:
...UHD 4:2:0 8Bit in einer HD 10-Bit-Timeline sieht sehr gut aus und lässt sich auch gut graden ....
Wie mehrfach auch von mir beschrieben bringt es Vorteile, bei einem Downscale in eine 10bit Dynamik zu skalieren...
Durch Herunterskalieren von UHD nach HD kann im Allgemeinen die Bittiefe von 8 Bit im Luminanzkanal verbessert werden, im Idealfall um 2 Bit, im Allgemeinen um weniger
ich bin eigentlich auch in der 10bit frage geneigt, dem ganzen eine gewisse berechtigung zu zusprechen.
...macht es in meinen augen schon sinn, diesem rechnerischen auflösungsgewinn beim skalieren tatsächliche eine gewisse signifikanz zuzuschreiben.
Also ich finde, wir haben auch bei diesem Thema durchaus eine gemeinsame Basis gefunden.
Schön wäre, wenn hier diejenigen, die sich mit dem Thema auskennen, nicht nur auf ihrem Nein bestehen würden, sondern z.B. Beiträge liefern könnten, unter welchen Umständen das geht und unter welchen Umständen nicht. Ich bin z.B auch der Meinung, dass der Dynamikgewinn, für den ich hier argumentiere, nicht immer funktioniert.
Gruß Jürgen
Antwort von HJS:
Davon ab, ob's wirklich "heute noch" gelb wird stelle ich in Frage, das liegt an der Qualität der Algorithmen die zur Anwendung kommen. Ich behaupte es ist aktuell in der Regel eher monochrom, aber das ist genau so eine Behauptung wie das es gelb wird. Niemand schreibt seinen Algorithmus vor, er ist nicht allgemeingültig!
ich denke, wir sollten nicht mit den unbekannten Algorithmen noch ein neues Fass aufmachen, weil wir dann nur spekulieren können und jeder kann etwas behaupten, ohne dass man es beweisen kann.
Diesen theoretischen Fall haben wir so eingegrenzt, dass die Kante durch das Sensel gehen soll. Und dafür können wir dann argumentieren.
Gruß Jürgen
Antwort von WoWu:
@Jürgen
Vielleicht solltest Du meine Einlassung ganz lesen und verstehen, denn in Hardware machen die Kameras da eine Pixelshift und erst daraus entsteht die zusätzliche Kantenaufsteilung, die mit diesem Problem nicht direkt zusammenhängt, hätte ich aber erwähnt.
Deine Frage wird durch das Pixelshift beantwortet.
Die Kante ist dabei nur noch ein zusätzlicher Nebeneffekt.
Bleibt aber die Frage, nach dem NLE, das eine asymmetrische Unterabtastung unterstützt.
Keine Antwort ?
Dann ist die ganze Diskussion um 4:4:4 nämlich sowieso Makulatur.
Antwort von HJS:
@Jürgen
Vielleicht solltest Du meine Einlassung ganz lesen und verstehen, denn in Hardware machen die Kameras da eine Pixelshift ...
Deine Frage wird durch das Pixelshift beantwortet.
....
ich habs gelesen, glaube auch, es verstanden zu haben. Das darfst du natürlich anzweifeln.
Was meinst du in diesem Zusammenhang mit Pixelshift?
Das kenne ich bisher nur aus der Projektiontechnik von JVC.
Gruß Jürgen
Antwort von WoWu:
Die Algorithmen stehen doch oben, sogar in der Gegenüberstellung.
Wüsstest Du denn, welches NLE für eine asymmetrische Unterabtastung in Frage kommt, oder auch nicht .
Welches benutzt Du denn, weil Du doch sagst, es würde funktionieren ?
Wäre ja mal schön zu erfahren, wie Du die Matrixen voneinander unabhängig unterabtastest und sie hinterher wieder zusammenbringst und vor allem, mit welchem NLE.
Antwort von HJS:
Die Algorithmen stehen doch oben, sogar in der Gegenüberstellung.
Wüsstest Du denn, welches NLE für eine asymmetrische Unterabtastung in Frage kommt, oder auch nicht .
Welches benutzt Du denn, weil Du doch sagst, es würde funktionieren ?
Wäre ja mal schön zu erfahren, wie Du die Matrixen voneinander unabhängig unterabtastest und sie hinterher wieder zusammenbringst und vor allem, mit welchem NLE.
Also die von dir angegebenen "Algorithmen" tragen zum Thema überhaupt nichts bei. Hast du das eigentlich selber verstanden, was du uns da vorsetzt?
Auf mein Argument, dass eine 444 Kamera das gleiche Ergebnis liefert wie die Herunterskalierung, gehst du gar nicht ein.
Und jetzt versuchst du, mit der Frage nach dem NLE das Ganze als irrelevant, weil nicht realisierbar darzustellen. Sowas nennt man doch Nebelbombenwerfen, oder ?
Ich benutze Adobe CC. Ich kann dir nicht sagen, wie die Skalierungsalgorithmen von Adobe aussehen. Für unser Thema hier geht es um die prinzipielle und theoretische Möglichkeit, nicht um Produkte von Firmen. Und spekulativ: ja, ich glaube dass Adobe in seinen Skalierungsalgorithmen das Potential nutzt, dass das Ausgangssignal zur Verfügung stellt.
Gruß Jürgen
Antwort von Roland Schulz:
@Jürgen
Vielleicht solltest Du meine Einlassung ganz lesen und verstehen, denn in Hardware machen die Kameras da eine Pixelshift und erst daraus entsteht die zusätzliche Kantenaufsteilung, die mit diesem Problem nicht direkt zusammenhängt, hätte ich aber erwähnt.
Deine Frage wird durch das Pixelshift beantwortet.
Die Kante ist dabei nur noch ein zusätzlicher Nebeneffekt.
Bleibt aber die Frage, nach dem NLE, das eine asymmetrische Unterabtastung unterstützt.
Keine Antwort ?
Dann ist die ganze Diskussion um 4:4:4 nämlich sowieso Makulatur.
Wieso muss der Downscale im NLE erfolgen (mag sein dass es da sogar was gibt...) -> FFMPEG mit NN, hatte ich bereits beantwortet!!!
Jetzt Du: Was ist 4:4:4??? Definition auf Pixelbasis bitte, ohne Kameras und Abtastungsfalschfarben und das ganze Lametta!!!
Da warten wir jetzt schon seit Tagen auf eine Antwort von Dir!!
So ein Mist wenn man nur noch mit nem halben Fuß am Abgrund steht und der Wind von allen Seiten bläst!!!
Meine Hand wolltest Du nicht, statt dessen spuckst Du hier weiter rum...
Jetzt spucke ich noch mal zurück!! Deine Darstellung von gestern hat mich zugegeben etwas aus der Kurve geworfen, allein anhand der Farben konnte ich mir da keinen Reim drauf machen...
Unter A gibst Du offen zu dass ich Recht habe, auch wenn die Erklärung offen bleibt was "pseudo" 4:4:4 sein soll. Den Begriff konnte ich bisher nirgends wiederfinden, scheint eine Neuerfindung von Dir zu sein...
Bei B und C hatte ich dann aber "buffer overflow", oder besser "clipping"!! Wie soll das funktionieren?!?!
Als ich vorhin bei Gelb an der Ampel losgefahren bin kam mir wieder... "gelb", wo kommt DAS GELB her?!?! Sowas habe ich in diesem Zusammenhang so noch nie gesehen!!
In Deiner Darstellung C links sehen die Farben im 4:4:4 für"s Auge erstmal "ungefähr!!" nach (im folgenden R,G,B) 0,255,0 für die grünen Bildpunkte und 255,0,0 für die roten aus.
Nach Deiner Unterabtastung unter C Mitte sieht das dann "ungefähr!!" wieder nach 0,255,0 für grün, 255,255,0 für gelb und... was ist eigentlich mit rot passiert, ~200,0,0 aus.
Hast Du dir deinen oder den abgeschriebenen Algorithmus unter B mal angesehen?!?!?! Die Grafik links ist auch FALSCH, auch da haben wir wieder ein leuchtendes gelb, links und rechts daneben steht aber 50%, nicht 2x 50%!!!
Merkst Du eigentlich was für einen Käse du hier ablieferst?!?!
Willst Du uns erzählen dass bei der Unterabtastung leuchtendes gelb an der Kante rauskommt?!?! Hab ich so noch nicht gesehen, ist auch FALSCH gemäß Deinem Algorithmus!!!
Ich hab auch nichts auf den Augen, zudem nen Monitor wo andere zwei Komplettsysteme von kaufen. Auch Photoshop zeigt RGB Werte die subjektiv erstmal nah an den von mir genannten Werten sind.
Die Frage ist zudem warum das rot in der Unterabtastung so verblasst, wobei in dem Bereich nichts unterabzutasten wäre (ohne weitere Filter...), das grün dagegen völlig unverändert bleibt! Magst Du rot nicht ;-)?!?!
Guck Dir mal unter https://en.wikipedia.org/wiki/Chroma_subsampling unter "4:2:0" die Bildbeispiele an!! Ist da irgendwas so "atomgelb" ;-)?!?!?!
In der Realität sieht das nicht annähernd so aus, es sei denn man rechnet mit stark vereinfachten, Algorithmen 100x von RGB zu YCrCb und zurück, das ist aber hier zum Glück nicht erforderlich!
Bei meiner Darstellung bist Du doch auch so genau und willst ne Kommastelle hinter dem glatten Bruch finden!
Ich würde Dir empfehlen, Deine Darstellung oben zu ändern oder zu entfernen, "...bevor sich solche falschen Grafiken weiter verbreiten, sollte man einen Blick darauf werfen..." und feststellen, dass uns hier wiedermal ein x für ein u vorgemacht wird.
Keine Ahnung wo Du das zusammenkopiert hast, richtig in der Darstellung ist es so nicht, verwirrt nur wieder einmal und trägt auch nichts zur "einfachsten Sache auf der Welt", 4:2:0 wird durch Halbierung der horizontalen und vertikalen Dimension zu 4:4:4 bei!
Antwort von HJS:
Willst Du uns erzählen dass bei der Unterabtastung leuchtendes gelb an der Kante rauskommt?!?! Hab ich so noch nicht gesehen,
das kommt höchstens in der Theorie vor, in der Praxis gibt es wegen des OLPF gar keine so scharfen Kanten, an denen dieser Effekt beobachtet werden könnte. Das wird noch nie jemand gesehen haben. Es sei denn bei einer Copmputersimulation.
Gruß Jürgen
Antwort von Roland Schulz:
Willst Du uns erzählen dass bei der Unterabtastung leuchtendes gelb an der Kante rauskommt?!?! Hab ich so noch nicht gesehen,
das kommt höchstens in der Theorie vor, in der Praxis gibt es wegen des OLPF gar keine so scharfen Kanten, an denen dieser Effekt beobachtet werden könnte. Das wird noch nie jemand gesehen haben. Es sei denn bei einer Copmputersimulation.
Gruß Jürgen
...auch in der Theorie hätten wir maximal "die Hälfte", sowas sieht aber dann nicht mehr im Entferntesten nach dem aus was Wolfgang hier zeigt!
Antwort von WoWu:
@ Jürgen,
Du solltest Deine eigene Frage nochmal lesen und auch den gesamten Thread denn die Kante innerhalb eines PIxels wird durch die Art der Abtastungen bestimmt.
Daher mein Verweis darauf, dass Dies durch Pixelshift in der dargestellten Anteiligen Art durchgeführt wird.
Ansonsten nimmt ein Pixel auch nur einen Wert ein (und zwar nur den Luminanzwert hinter der Filterscheibe und wenn sich dieser aus unterschiedlichen Nuancen zusammensetzt, wird er nicht den Wert einer einzigen Nuance (Grauwertes) einnehmen denn ein Pixel kennt überhaupt kein Farbe.
2. Vom Wiederholen , dass eine 3-Chip Kamera den identischen Wert abliefert, wird die Aussage nicht richtiger.
GGf. solltest Du also noch einmal den Unterschied zwischen einer 1-Chip Kamera und einer 3-Chip Kamera genauer nachlesen.
3. Die praktische Verwendbarkeit und dass eine getrennte Matrixhandhabung in gängigen NLEs nicht stattfindet, hab ich früher im Thread bereits mehrfach angesprochen. Lesen des gesamten Threads ist also hilfreich, Aufmerksamkeitslücken zu füllen.
Natürlich gibt es Tools, mit denen solche Algorithem durchgerechnet werden können, und wer macht das ?
Für 99% aller Forentwilnehmer stellt sich die Frage überhaupt nicht und selbst wenn, dann sollten wir uns die Korellationen der Werte nochmal anschauen, was auch in den genannten Aufsätzen thematisiert wird.
Also, das Programm zu haben und eine Umsetzung damit durchzuführen sind selbst für das verbleibende 1% noch zwei paar Schuhe.
Ich stelle also fest, dass Du den Vorgang bisher nicht ausgeführt hast und nur einfach behauptest, es funktioniert.
Prima Basis.
Und was Deinen Einwand bezüglich OLPF und härter Kante betrifft .... jedes Pixel nimmt einen Mischwert ein und grenzt sich zum Nachbarpixels, mit seinem Mischwert als "harte Kante" ab.
Vielleicht solltest Du nochmal nachschlagen, wie Video eigentlich funktioniert und dass "Gelb" nur eine exemplarische Beschreibung (für jeden beliebigen Andern Wert einer Fehlfarbe) war, haben schon andere nicht mitbekommen, da bist Du also in bester Gesellschaft.
Abstraktes Denken schein nicht so Dein Ding zu sein.
Antwort von HJS:
@ Jürgen,
Du solltest Deine eigene Frage nochmal lesen und auch den gesamten Thread... wird die Aussage nicht richtiger.
GGf. solltest Du also noch einmal den Unterschied zwischen einer 1-Chip Kamera und einer 3-Chip Kamera genauer nachlesen.
... Lesen des gesamten Threads ist also hilfreich... Aufmerksamkeitslücken zu füllen.
Ich stelle also fest, dass ... nur einfach behauptest
Prima Basis.
Vielleicht solltest Du nochmal nachschlagen, wie Video eigentlich funktioniert ...haben schon andere nicht mitbekommen, da bist Du also in bester Gesellschaft.
Abstraktes Denken schein nicht so Dein Ding zu sein.
???
Antwort von HJS:
... und wenn sich dieser aus unterschiedlichen Nuancen zusammensetzt, wird er nicht den Wert einer einzigen Nuance (Grauwertes) einnehmen
Genau das habe ich doch gesagt ??????
Sag mal, was ist dein Ziel hier?
Gruß Jürgen
Antwort von WoWu:
Nein, hast Du nicht, Du hast behauptet, es entstünden keine Kanten, die aber entstehen von Pixel zu Pixel sehr wohl.
Außerdem .... wenn durch ein Pixel grün und rot läuft ist das bereits gelb, es entsteht also der Luminanzwert für einen helleren Grauwert, aus dem das De-Bayering unter der Kenntnis des vorgelagerten Farbfilters, dann Gelb errechnet.
Ich lasse jetzt nochmal ganz bewusst außen vor, dass weitere, zusätzliche Kanten durch die ARt der Antastung entstehen, weil Du die Zusammenhänge nur wieder als Nebelkerze bezeichnen würdest, weil Du sie offenbar nicht einordnen kannst.
Antwort von HJS:
Für diejenigen, die hier an der Sache interessiert sind, vielleicht noch eine interessante Beobachtung:
Sony hat den Standard XDCAM HD422 vor einiger Zeit eingeführt.
Für die X70 gibt es seit neuestem ein Upgrade das diesen Standard realisiert. Da die Kamera einen Bayer Sensor hat, hat sie in 4k ein Farbsystem 4:2:0.
ich gehe davon aus, dass das Upgrade per SW den 4:2:2 Standart erzeugt, so wie hier von einigen diskutiert.
Gruß Jürgen
Antwort von Roland Schulz:
@ Jürgen,
Du solltest Deine eigene Frage nochmal lesen und auch den gesamten Thread denn die Kante innerhalb eines PIxels wird durch die Art der Abtastungen bestimmt.
Daher mein Verweis darauf, dass Dies durch Pixelshift in der dargestellten Anteiligen Art durchgeführt wird.
Ansonsten nimmt ein Pixel auch nur einen Wert ein und wenn sich dieser aus unterschiedlichen Nuancen zusammensetzt, wird er nicht den Wert einer einzigen Nuance einnehmen.
2. Vom Wiederholen , dass eine 3-Chip Kamera den identischen Wert abliefert, wird die Aussage nicht richtiger.
GGf. solltest Du also noch einmal den Unterschied zwischen einer 1-Chip Kamera und einer 3-Chip Kamera genauer nachlesen.
3. Die praktische Verwendbarkeit und dass eine getrennte Matrixhandhabung in gängigen NLEs nicht stattfindet, hab ich früher im Thread bereits mehrfach angesprochen. Lesen des gesamten Threads ist also hilfreich, Aufmerksamkeitslücken zu füllen.
Natürlich gibt es Tools, mit denen solche Algorithem durchgerechnet werden können, und wer macht das ?
Für 99% aller Forentwilnehmer stellt sich die Frage überhaupt nicht und selbst wenn, dann sollten wir uns die Korellationen der Werte nochmal anschauen, was auch in den genannten Aufsätzen thematisiert wird.
Also, das Programm zu haben und eine Umsetzung damit durchzuführen sind selbst für das verbleibende 1% noch zwei paar Schuhe.
Ich stelle also fest, dass Du den Vorgang bisher nicht ausgeführt hast und nur einfach behauptest, es funktioniert.
Prima Basis.
Und was Deinen Einwand bezüglich OLPF und härter Kante betrifft .... jedes Pixel nimmt einen Mischwert ein und grenzt sich zum Nachbarpixels, mit seinem Mischwert als "harte Kante" ab.
Vielleicht solltest Du nochmal nachschlagen, wie Video eigentlich funktioniert und dass "Gelb" nur eine exemplarische Beschreibung (für jeden beliebigen Andern Wert einer Fehlfarbe) war, haben schon andere nicht mitbekommen, da bist Du also in bester Gesellschaft.
Die nächste "Nebelgranate" mit gleichzeitiger Denunzierung 99% aller Forenteilnehmer, Glückwunsch!!!
Vielleicht sollten die Schiedsrichter Dir mal wieder die "Gelbe Karte" zeigen, damit Du wieder ein Gefühl für Farben kriegst, besonders gelb ;-)!!
Ich glaube die lachen sich im Hintergrund aber selbst nur noch kaputt und freuen sich, dass hier mal wieder Feuer im Lager ist ;-)!!! Würde mich allein mal interessieren wieviele hier im Hintergrund einfach nur mitlesen und zusehen, wie das Blattgold der goldenen Kuh Stück für Stück abblättert.
Du kannst hier noch Dein halbes Buch posten, willst ohnehin nur dass wir Dir die ganzen Fehler raussuchen, das wird mir auf Dauer dann aber doch zu umfangreich!
Wolfgang, was bedeutet 4:4:4 auf Pixelebene - wir warten immer noch auf die Antwort!! Was ist "pseudo 4:4:4", die Einsicht zu meinem 2:0 Sieg ;-) ;-) ;-)???
Wir wollen die Antworten, vorher lassen wir Dich nicht mehr mitspielen ;-) ;-) ;-)!
Der ganze Kakao den Du hier ausschüttest wird irgendwann sauer, Du kannst es zur Schadensbegrenzung ganz einfach beenden.
Antwort von WoWu:
Ich dachte, 4:4:4 ... ist doch kein Unterschied zu einer 3-Chip ....
Die Hoffnung stirbt immer zuletzt.
Antwort von HJS:
... dann werden in diesem Beispiel (Kante verläuft genau in Senselmitte) die Sensel des für Rot zuständigen Chips und die für grün zuständigen jeweils zur Hälfte beleuchtet...
Gruß Jürgen
Du hast scheinbar meinen Gedanken nicht verstanden. Das Sensel mittelt alle wahrnehmbare Strahlung, die während der Belichtungszeit auf seine Fläche fällt. Das hier zu diskutieren ist langsam an der Albernheitsschwelle. Findest du das eigentlich noch gut??
Natürlich sind die Pixel getrennt. Oder hast du mich so verstanden, dass ich die ganze Zeit von einer analogen Bildaufnahmeröhre spreche?
Mein Argument mit dem OLPF ist allerdings wohl nicht richtig, ziehe ich zurück.
Gruß Jürgen
Antwort von WoWu:
@Roland ...
Deine Postings gehen mittlerweile ungelesen in den Orkus weil Von so wenig Substanz, dass man kaum drauf antworten kann.
Basics stehen bei Wicki...
Antwort von Roland Schulz:
Nein, hast Du nicht, Du hast behauptet, es entstünden keine Kanten, die aber entstehen von Pixel zu Pixel sehr wohl.
Außerdem .... wenn durch ein Pixel grün und rot läuft ist das bereits gelb, es entsteht also der Luminanzwert für einen helleren Grauwert, aus dem das De-Bayering unter der Kenntnis des vorgelagerten Farbfilters, dann Gelb errechnet.
Schwachsinn!! Wenn grün und rot durch einen Pixel laufen, was ja nur bei ner Foveon oder 3 Chip geht, haben wir wieder eine Farbe die sich zu 50% aus rot und grün zusammensetzt!!
Das noch als gelb zu bezeichnen ist eine absolute Übertreibung!!
Aber mit Definitionen gibt's ja ohnehin die ein- und andere Schwierigkeit...
Antwort von WoWu:
@ Jürgen
Nochmal ... die einfallenden Photonen erzeugen lediglich einen Luminanzwert, der im De-Bayering entsprechend der vorgelagerten Filterscheibe gewichtet wird.
Ist der einfallende Wert ein Gemisch aus Grün und Rot, ist er abweichend von den EInzelwerten GRÜN oder ROT und nimmt keinen der beiden Werte ein.
S/W auf einem Pixel würde also immer ein graues Pixel ergeben.
Entsprechend der Filterscheibe, hinter der der Wert entstanden ist, wird der Mischwert einem RGB Wert zugeordnet.
Es entsteht als eine Fehlfarbe, bereits in dem Pixel und damit eine Kante, da die Fehlfarbe sich von den beiden Originalfarben unterscheidet.
Art und Menge der Fehlfarbe wird zusätzlich durch das Verhältnis des Pixelshifts beeinflusst, also der Mengengewichtung des Pixels.
Antwort von Roland Schulz:
@Roland ...
Deine Postings gehen mittlerweile ungelesen in den Orkus weil Von so wenig Substanz, dass man kaum drauf antworten kann.
Basics stehen bei Wicki...
WAS IST 4:4:4???? Beantworte die Frage, lass die Belletristik!!!
Antwort von WoWu:
Hab ich oben schon angerissen, wenn Du meine Postings nicht liest, ist das Dein Problem, aber das erklärt, dass Du sie nicht verstehst.
Antwort von Roland Schulz:
Wolfgang, was bedeutet 4:4:4 auf Pixelebene - wir warten immer noch auf die Antwort!!
@Roland ...
Basics stehen bei Wicki...
...damit hätte ich dann Recht, auch eine Art und Weise das Feld zu verlassen...
Antwort von HJS:
@wowu
das hatte ich damals gesagt:
Nur, was hätte eine FHD 444-Kamera bei den mittleren Pixeln in Beispiel C angezeigt, wenn die Farbkante durch die Sensel verläuft?
das ist die genau die richtige Frage!
WOWU antwortet:
"Farbkanten innerhalb eines Pixels sind nicht darstellbar (bei keiner Kamera)"
Das ist ja trivial.
Geht man von einer 3-Sensor HD Kamera aus, dann werden in diesem Beispiel (Kante verläuft genau in Senselmitte) die Sensel des für Rot zuständigen Chips und die für grün zuständigen jeweils zur Hälfte beleuchtet. Das ergibt wieder "Gelb" als Ergebnis im Bild.
Das heißt, eine 444 HD Kamera würde in diesem Beispiel genau das gleiche Ergebnis liefern wie die Herunterskalierung.
Gruß Jürgen
es ist ja rührend, wie du dich um meine Fortbildung bemühst. Wenn du mein oben zitiertes Post noch mal ansiehst, dann siehst du, dass ich deine Erläuterungen schon damals als trivial bezeichnet habe.
Mein Eindruck ist mittlerweile, dass du einfach recht behalten willst und befürchtest, dass deine Autorität angezweifelt wird. Und du wehrst dich mit Verunglimpfungen, Nebelbomben, Ignorieren von Argumenten und Abwertungen von Personen.
Schade!
Gruß Jürgen
Antwort von WoWu:
Du meinst auch, Angriff sei die beste Verteidigung und wenn man schon keine sachlichen Argumente mehr hat, dann muss eben ein Satz Polemik her.
Hilfreicher wäre es gewesen, Dich selbst um Deine Bildung zu bemühen. Es sollte Dir zu denken geben, dass andere das tun.
Du kannst weder theoretisch noch praktisch untermauern, warum Deine Theorie stimmen soll.
Du ignorierst wissenschaftliche Aufsätze, die sich mit der Thematik auseinander gesetzt haben und schwimmst in elementaren technischen Zusammenhängen.
Leg mir doch einfach die Fakten vor und überzeug mich, dass die bisherigen Veröffentlichungen in dieser Sache falsch sind und die bunten Blog-Fhantasien richtig.
Nur mit obskuren Behauptungen kannst Du hier im Forum nur bei denen Punkten, die noch weniger, als Du von der Sache verstehen.
Pech, für Dich.
Mir geht es aber darum, dass nicht noch mehr von dem Internetmist hier verbreitet wird.
Dass er schon bei so manchem Einäugigen auf fruchtbaren Boden gefallen ist, ist schlimm genug.
Antwort von HJS:
...muss eben ein Satz Polemik her.
Hilfreicher wäre es gewesen, Dich selbst um Deine Bildung zu bemühen. Es sollte Dir zu denken geben, dass andere das tun.
Du ignorierst wissenschaftliche Aufsätze, ...
und schwimmst in elementaren technischen Zusammenhängen.
...nur mit obskuren Behauptungen ...
die noch weniger, als Du von der Sache verstehen.
...Pech, für Dich.
... manchem Einäugigen .
wie gehabt
Antwort von Roland Schulz:
Ich denke die meisten hier werden Wolfgang eine fundierte Fachkenntnis nicht aberkennen, auch ich tue das ganz bestimmt nicht!!
Das Verhalten welches hier nach dem Abbiegen in eine Einbahnstraße mit Sackgasse aber mal wieder an den Tag gelegt wurde empfinde ich einfach nur armseelig!!
Antwort von WoWu:
Das sei Dir unbenommen.
Ändert aber nichts daran, dass Du mit Deiner unbestätigten Annahme falsch liegst.
Da sollte nun jeder selbst wissen, welchen Argumenten er folgt.
Mich wundert eben nur, dass nicht schon alle NLE -und Kamerahersteller schon lange auf den Zug aufgesprungen sind und andere immernoch 3-Chip bzw 4-Chip Kameras bauen, wenn die Lösung aller Probleme doch so nahe liegt.
Vielleicht liegt das ja doch daran, dass sich der eine oder andere Haken dahinter verbirgt.
Antwort von Roland Schulz:
Das sei Dir unbenommen.
Ändert aber nichts daran, dass Du mit Deiner unbestätigten Annahme falsch liegst.
Da sollte nun jeder selbst wissen, welchen Argumenten er folgt.
Meine Annahme ist per Definition bewiesen, ich habe Recht!!
Wenn Du endlich mal meine Frage "was bedeutet 4:4:4 auf Pixelebene" selbst beantworten würdest, würde Dir das auch selbst klar - aber das ist es ohnehin schon längst, hast nur ne zu dicke Delle im Ego das auch zuzugeben, was ;-)?!?!
Wir können das noch bis in alle Ewigkeit weiterführen, nur irgendwann wird, wenn nichts dazwischenkommt, die Zeit für mich entscheiden...
Immerhin stehen wir nach den paar Tagen schon bei knapp 5.000 Zugriffen auf diesen Thread, da soll mal einer sagen hier wäre nichts mehr los!!!
Ich denke das haben wir doch ganz gut hingekriegt, oder ;-)?!?! Was zerlegen wir als nächstes?! Mit meinem komfortablen 2:0 Vorsprung kannst Du dir mal was überlegen wo du gewinnen möchtest...
Gratulation auch an Hokusfokus79, sehr guter Einstieg!!!
Antwort von Roland Schulz:
...Wow - die 5.000er Marke ist überschritten!!!!
Zur Feier des Tages gibt's von mir nen handgeschnitzten Witz zu 4:2:0
...kommt nen Ostfriese zum Bauern und sagt: 4 Eier, 2 jeweils für meine Frau und mich, weil ich 0 in der Hose habe um einen Fehler zuzugeben ;-) ;-) ;-)!!!
Mist, ist ja dann 4:2:2:0, auch kein Alphakanal mehr um mich zu maskieren...
Fällt "jemandem" was zu 4:4:4 ein - "Freiwillige" vor!!!
Antwort von Jott:
Es drang noch nicht zu allen durch, dass es um's Downscaling von UHD zu HD geht und nicht um 4:2:0-zu-4:4:4-Alchemie ohne gleichzeitiges Scaling um den Faktor 4.
Antwort von Jan:
Auch wenn es schwer fällt, genießt das Wochenende !
Antwort von wüdara:
manchen Rentnern fällt es schwer, ein neues Betätigungsfeld zu finden,das ist bei Hrn.Schulz nicht anders.
Nur, bei ihm heißt es Bestätigungsfeld und das ist natürlich viel,viel wichtiger als alles Andere:-))
Antwort von Roland Schulz:
Auch wenn es schwer fällt, genießt das Wochenende !
...pssst, bzgl. der Signatur, "wahrscheinlich" schreibt man mit "h", weil's von Wahrheit kommt ;-)!!
Ansonsten: dito!!
Antwort von Roland Schulz:
manchen Rentnern fällt es schwer, ein neues Betätigungsfeld zu finden,das ist bei Hrn.Schulz nicht anders.
Nur, bei ihm heißt es Bestätigungsfeld und das ist natürlich viel,viel wichtiger als alles Andere:-))
Wowu hat schon nen enormen Fanclub - er darf andere fälschlicherweise als Träumer und Lügner darstellen. Wenn man sich dann mit Argumenten rechtfertigt ist man trotzdem noch der Dumme!!
Denke am Ende haben wir trotzdem alle viel Spaß gehabt, oder nicht ;-)?!?!
Antwort von WoWu:
manchen Rentnern fällt es schwer, ein neues Betätigungsfeld zu finden,das ist bei Hrn.Schulz nicht anders.
Nur, bei ihm heißt es Bestätigungsfeld und das ist natürlich viel,viel wichtiger als alles Andere:-))
Wowu hat schon nen enormen Fanclub - er darf andere fälschlicherweise als Träumer und Lügner darstellen. Wenn man sich dann mit Argumenten rechtfertigt ist man trotzdem noch der Dumme!!
Fast wie bei Porsche, wo man nem Turbo S Kunden beim Motorschaden erstmal nen Überdreher nachweisen will...
Denke am Ende haben wir trotzdem alle viel Spaß gehabt, oder nicht ;-)?!?!
Da muss ich Dir kurz doch noch recht geben.... das mit dem "Dummen" das stimmt.
Und was Deine "Fakten" betrifft ... Du weißt doch, das Internet nutzt nur dem, der nicht alle glaubt.
Ansonsten gehört die Bühne wohl jetzt all denen, die bei 4:4:4 und Downscaling keine Gemeinsamkeit entdecken können.
Viel Spaß noch ....
Antwort von Roland Schulz:
Ansonsten gehört die Bühne wohl jetzt all denen, die bei 4:4:4 und Downscaling keine Gemeinsamkeit entdecken können.
Viel Spaß noch ....
...eine Bühne ganz allein für Dich - das ist doch mal was!!! Ganz großes Kino - wir schauen Dir auch alle zu!! So ein Meister braucht doch nen ordentlichen Abgang...
Dann erzähl' uns doch endlich mal was zu 4:4:4 bezogen auf die Pixelebene!!
Wir lachen auch nicht, versprochen!! Ich würde klatschen, echter Beifall und RESPEKT - wenn Du es doch noch schaffst über deinen eigenen Schatten zu springen!!
Antwort von mash_gh4:
Aber bevor sich solche falschen Grafiken weiter verbreiten, sollte man einen Blick darauf werfen, wie es wirklich funktioniert:
zum Bild
ist dir eigentlich aufgefallen, dass diese grafik einen wirklich goben fehler enthält!
die Y werte, die du hier dem "pseudo 4:4:4 2K" output zuordnest, geben offenbar immer nur den pixel links-oben im ursprungsbild wider. ist das wirklich deine vorstellung von sauberem skalieren?
das hat zwar mit farbsubsampling auf den ersten blick noch gar nichts zu tun, allerdings kann man hier natürlich auch einem ganz ähnlichen irrtum aufsitzen, wenn das sgn. "chrominance decimation nicht sauber durchgeführt wird bzw. nicht den inhalt aller betroffen samples mitberücksichtigt.
Antwort von Roland Schulz:
Aber bevor sich solche falschen Grafiken weiter verbreiten, sollte man einen Blick darauf werfen, wie es wirklich funktioniert:
zum Bild
ist dir eigentlich aufgefallen, dass diese grafik einen wirklich goben fehler enthält!
die Y werte, die du hier dem "pseudo 4:4:4 2K" output zuordnest, geben offenbar immer nur den pixel links-oben im ursprungsbild wider. ist das wirklich deine vorstellung von sauberem skalieren?
das hat zwar mit farbsubsampling auf den ersten blick noch gar nichts zu tun, allerdings kann man hier natürlich auch einem ganz ähnlichen irrtum aufsitzen, wenn das sgn. "chrominance decimation nicht sauber durchgeführt wird bzw. nicht den inhalt aller betroffen samples mitberücksichtigt.
Ist mir auch aufgefallen. Na ja, kann man ankreiden, muss man aber nicht. Wolfgang oder der Ersteller von dem das zusammenkopiert wurde hätte vielleicht einen Strich/Apostroph als Zeichen der Ableitung an die neue Date schreiben können, das würde "ich" jetzt aber nicht zu hart verurteilen.
Im Endeffekt gibt die Beschreibung doch wohl "nur" die Position des Pixels in der gegenständlichen Matrix wieder. Nen kleiner Strich hätte da aber sicher nicht geschadet - ich sag's ja, nen Lektor muss her.
Da der Betrachter die Positionen leicht selbst verfolgen kann hatte ich mir diese Arbeit in meiner Darstellung gespart, habe auch bewußt keine Rechenmethode bei der "Zusammenfassung" der einzelnen Y Pixel beschrieben weil's für die eigentliche Betrachtung irrelevant ist. So gibt's auch keinen Diskussionsgrund.
Mich persönlich hat in B und C eher das subjektiv "full well" ;-) gelb gestört, das entsteht in dieser Form bei weitem nicht, auch wenn der Farbwinkel der gleiche bleibt. Warum das rot in C Mitte plötzlich so blass aussieht, grün sich aber nicht verändert wurde auch noch nicht erklärt.
Ich denke wenn wir 100 Menschen fragen würden die mit "Farben" umgehen, ob sich "das gelb" eher aus einer 100% rot/grün Mischung oder der erwarteten 50% rot/grün Mischung zusammensetzt, würde "ich" die Antwort klar in der ersten Variante erwarten. Die wäre aber im Zusammenhang doch komplett falsch.
Der von mir beschriebene Wiki Eintrag demonstriert auch klar am rot grün Übergang, das so ein gelb wie in der Grafik gezeigt bei weitem nicht eintritt. In meiner Umgebung sehe ich das ähnlich wie im Wiki. Mich hat's zunächst etwas verwirrt. Hat auch nichts mit der Darstellung am Monitor o.ä. zu tun.
Antwort von Jan:
Roland Schulz - peinlich von mir, ist mir überhaupt nicht aufgefallen, obwohl es aber bei normalem Hinsehen sofort in das Auge sticht.
Ich will nicht noch eine neue Diskussion anzetteln, aber wenn es denn wirklich so einfach ist, aus 4K 4:2:0 ein hochwertiges FHD-Signal mit 4:4:4 zu machen, warum kann das kein Consumergerät ? Das sollte doch kein Problem sein, da es inzwischen die Rechenpower in den Kameras erlauben sollte, so etwas intern hinzubekommen. Jetzt kommt sicher die Frage, welcher Normalkunde braucht denn 4:4:4 ? H.264 erlaubt ja sogar ein 4:4:4-Profil. Das wäre doch eine neue Werbemasche im Consumerbereich, wenn ganz normale Consumerkameras ein FHD H.264 4:4:4 aufzeichnen könnten. Der Masse bringt das zwar nichts, aber man kann es weit hergeholt mit RAW vergleichen oder zumindest in die Richtung anpreisen. Könnte besser wirken, als die aktuelle 4K-Nachfrage oder die eher schlechte HDR-Camorderfunktion einiger Panasonics.
VG
Jan
Antwort von cantsin:
die Y werte, die du hier dem "pseudo 4:4:4 2K" output zuordnest, geben offenbar immer nur den pixel links-oben im ursprungsbild wider.
Wie kommst Du darauf? Ich glaube, Du liest die Grafik verkehrt. (Bei der 4K-4:2:0-Abtastung entsteht an der rot-grünen Farbkante eine Falschfarbe, die beim Runterskalieren auf 2K erhalten bleibt, weil bei diesem Runterskalieren wegen der Unterabtastung im Ausgangsmaterial ja keine neuen Farbwerte berechnet/gemittelt werden).
Aber ich sehe ein anderes Problem bei WoWus Grafik: Ja, im 4K-4:4:4-Modus wird die Farbkante sauber aufgelöst und kann dann auch sauber, ohne Falschfarbe, nach 2K-4:4:4 runterskaliert werden. Was aber wäre, wenn die Kamera gleich - ohne Skalieren, sondern sensor-nativ - 2K 4:4:4 aufgenommen hätte? Dann wäre wegen der geringeren spatialen Auflösung ebenfalls die Falschfarbe an der Kante entstanden. Insofern könnte man argumentieren, dass die Farbauflösung bzw. -qualität des runterskalierten 4K-4:2:0-Materials identisch mit dem von sensornativen 2K-4:4:4-Material sind.
Antwort von TheBubble:
Ich will nicht noch eine neue Diskussion anzetteln, aber wenn es denn wirklich so einfach ist, aus 4K 4:2:0 ein hochwertiges FHD-Signal mit 4:4:4 zu machen, warum kann das kein Consumergerät ?
Aus dem Grund, weswegen man mit Chroma-Unterabtastung überhaupt angefangen hat: Es sind weniger Daten zu speichern, zu verarbeiten und zu übertragen.
Auch müsste man in Kameras gar nicht von 4:2:0 nach 4:4:4 umrechnen, denn man könnte über 4:4:4 direkt verfügen.
Antwort von Jan:
Ich will nicht noch eine neue Diskussion anzetteln, aber wenn es denn wirklich so einfach ist, aus 4K 4:2:0 ein hochwertiges FHD-Signal mit 4:4:4 zu machen, warum kann das kein Consumergerät ?
Aus dem Grund, weswegen man mit Chroma-Unterabtastung überhaupt angefangen hat: Es sind weniger Daten zu speichern, zu verarbeiten und zu übertragen.
Auch müsste man in Kameras gar nicht von 4:2:0 nach 4:4:4 umrechnen, denn man könnte über 4:4:4 direkt verfügen.
Danke, aber wir befinden uns im Jahr 2016, da sollte so etwas ja möglich sein. Das Zeilensprung-Verfahren war damals auch sinnvoll, heute ist es mehrheitlich nur noch Quark.
VG
Jan
Antwort von Roland Schulz:
Ich will nicht noch eine neue Diskussion anzetteln, aber wenn es denn wirklich so einfach ist, aus 4K 4:2:0 ein hochwertiges FHD-Signal mit 4:4:4 zu machen, warum kann das kein Consumergerät ?
Aus dem Grund, weswegen man mit Chroma-Unterabtastung überhaupt angefangen hat: Es sind weniger Daten zu speichern, zu verarbeiten und zu übertragen.
Auch müsste man in Kameras gar nicht von 4:2:0 nach 4:4:4 umrechnen, denn man könnte über 4:4:4 direkt verfügen.
Im Prinzip alles richtig, wobei, jetzt wirklich mal in der Praxis, kaum eine Kamera echtes 4:4:4 schaffen wird, es sei denn es steht Foveon oder 3-Chip drauf. Selbst aktuelle Obersamplingkameras schaffen kaum eine anständige rot/blau Auflösung, die besonders kritisch ist da hier die wenigsten Informationen/Sensel bei einem Bayersensor vorliegen. Da tun sich die meisten 4K Modelle richtig schwer gegen ne FHD 3-Chip Kamera.
Weiterhin wird ganz klar der Markt zwischen Consumer, Semipro- und Pro bzw. der Preisklasse abgegrenzt.
Ich z.B. würde mir eher durchgängige, echte 10bit im bezahlbaren Rahmen wünschen, wobei auch das relativ ist.
Antwort von Roland Schulz:
Ich will nicht noch eine neue Diskussion anzetteln, aber wenn es denn wirklich so einfach ist, aus 4K 4:2:0 ein hochwertiges FHD-Signal mit 4:4:4 zu machen, warum kann das kein Consumergerät ?
Aus dem Grund, weswegen man mit Chroma-Unterabtastung überhaupt angefangen hat: Es sind weniger Daten zu speichern, zu verarbeiten und zu übertragen.
Auch müsste man in Kameras gar nicht von 4:2:0 nach 4:4:4 umrechnen, denn man könnte über 4:4:4 direkt verfügen.
Danke, aber wir befinden uns im Jahr 2016, da sollte so etwas ja möglich sein. Das Zeilensprung-Verfahren war damals auch sinnvoll, heute ist es mehrheitlich nur noch Quark.
VG
Jan
Machbar ist das sicher, aber nicht "wirtschaftlich". Wenn Du heute alles "verschenkst" kannst Du morgen nichts mehr verkaufen und dem Hersteller geht es schlechter als es ihm ohnehin schon geht. Übermorgen ist er pleite und wir können keine neuen Spielzeuge mehr kaufen ;-)...
Antwort von Jott:
Für unkomprimierte Aufzeichnung bräuchte man ganz schöne Brecher, insbesondere Speichermedien mit gaaanz viiiielen Terabyte (man will ja bitteschön die Schulaufführung der Kids ohne Medienwechsel aufzeichnen können). Wundert mich ein wenig, dass ihr von so was im Consumerbereich träumt. Wozu?
Consumer bekommen für einen runden Tausender schon heute Sachen, von denen vor nicht allzu vielen Jahren Profis nur träumen konnten. Wenn heute noch füchterlich aussehendes Zeug gefilmt wird, dann liegt das nicht mehr am Equipment.
Antwort von Roland Schulz:
Für unkomprimierte Aufzeichnung bräuchte man ganz schöne Brecher, insbesondere Speichermedien mit gaaanz viiiielen Terabyte (man will ja bitteschön die Schulaufführung der Kids ohne Medienwechsel aufzeichnen können). Wundert mich ein wenig, dass ihr von so was im Consumerbereich träumt. Wozu?
Consumer bekommen für einen runden Tausender schon heute Sachen, von denen vor nicht allzu vielen Jahren Profis nur träumen konnten. Wenn heute noch füchterlich aussehendes Zeug gefilmt wird, dann liegt das nicht mehr am Equipment.
Richtig, wobei ich immer feststellen muss das viele Geräte auch wieder künstlich verschlechtert werden, damit man mit dem kleinen Billigkram nicht zu professionell werden kann. So fehlt ja z.B. bei den Sony Consumercams seit Jahren die Möglichkeit, komplett manuell filmen zu können oder Bildparameter einzustellen.
Möglich wäre das ohne Zweifel, das hat auch nichts damit zu tun dass man den User nicht überfordern möchte, das ist einfach nur Produktpolitik!
Na ja, off topic, denke wir sind hier aber ohnehin (längst) fertig.
4:2:0 wird bei Halbierung der h/v Dimensionen zu 4:4:4, 8bit bleibt "8bit"!
Nur der Sinn der ganzen Sache steht zumindest für mich in der Praxis weiterhin in Frage, da man zum einen 3/4 an "Systemluminanzauflösung" vernichtet, kaum Kameras findet die nach dem Downscale 4:4:4 Farbauflösung auch praktisch nur annähernd erreichen würden, kaum noch (relevante) Software finden wird die nicht direkt die native Auflösung unterstützen würde und wenig Software findet die 4:4:4 überhaupt weiterverabreiten geschweige denn das Ganze überhaupt 1:1 wiedergeben und darstellen kann - hab ich was vergessen?!
Antwort von mash_gh4:
die Y werte, die du hier dem "pseudo 4:4:4 2K" output zuordnest, geben offenbar immer nur den pixel links-oben im ursprungsbild wider.
Wie kommst Du darauf? Ich glaube, Du liest die Grafik verkehrt.
danke! da hast du recht! ich hab die Y werte tatsächlich falsch interpretiert, nämlich als float angabe, statt als position/index innerhalb der matrix.
was den farbfehler an den übergängen betrifft, ist das ganze ja höchst unspektakulär, weil genau das selbe ja auch passiert, wenn man 4:4:4 material skaliert. im verkleinerten hd1080-resultat, gibt's keinen unterschied, ob die werte aus 4:2:0 oder 4:4:4 uhd2160 quellen generiert wurden.
Aber ich sehe ein anderes Problem bei WoWus Grafik: Ja, im 4K-4:4:4-Modus wird die Farbkante sauber aufgelöst und kann dann auch sauber, ohne Falschfarbe, nach 2K-4:4:4 runterskaliert werden. Was aber wäre, wenn die Kamera gleich - ohne Skalieren, sondern sensor-nativ - 2K 4:4:4 aufgenommen hätte?
ich glaube, dass es es ein ziemlicher unfug ist, die entsprechende ausgangsmatrix unbedingt gleich auf pysikalischer auflösung oder realen senseln in verbindung zu bringen. wenn man danach strebt, ist es gescheiter, man verlangt gleich die raw daten direkt vom sensor vor dem debayering, elektronischen entzerren von objektven etc. worauf sich die ausgangsmatrix hier aber bezieht, sind definitiv nicht mehr einzelne bildpunkte, wie sie der sensor sieht, sondern die digitale repräsentation eines bildes.
...wenn es denn wirklich so einfach ist, aus 4K 4:2:0 ein hochwertiges FHD-Signal mit 4:4:4 zu machen, warum kann das kein Consumergerät?
wie hier ohnehin bereits bereits mehrfach erwähnt, ist das natürlich in der praxis ohnehin der fall!
die unterabtatastung spielt wirklich nur am transportweg eine rolle. sowohl innerhalb der kamera, wie auch in praktisch allen unseren neueren bild- und videoverabeitungsprogrammen wird intern mit RGB in viel höherer genauigkeit gerechnet. das führt dazu, dass der beschriebene effekt sich quasi ganz von selbst einstellt, wenn du einfach nur das 4K material in deine timeline importierst, bearbeitest aber eben irgendwann am schluss in verkleinerter weise raus renderst.
ich persönlich hab kein problem damit, meine kamera nicht so sehr als billliges produktionsmittel für 4K zielaulösung zu verstehen, sondern eher als aufnahmegerät, das manche videotypischen transport- und speicherprobleme mit einem technischen kunstgriff geschickt umschifft, so dass man dann letzten endes in den gebräuchlichen zielauflösungen ein besseres resultat erhält, als mit geringer auflösenden kameras.
technisch sollte man vielleicht zu wowus grafik bzw. der grundsätzlichen problematik noch eine kleinigkeit hinzufügen: die ganze geschichte zerfällt bei näherer betrachtung in zwei schritte, die in der wowuschen grafik nicht wirklich klar getrennt sind:
a.) RGB werte, wie sie auch auch in der kamera gewöhnlich in weit mehr als 8 od. 10bit auflösung ursprünglich zur verfügung stehen, werden in ihre Y'CbCr entsprechnung und 8 oder 10bit auflösungsbeschränkung übersetzt.
b) im falle von 4:2:0 werden aber nur die Y' werte der vier benachbarten pixeln unverfäscht aufgezeichnet, während aus den vier Cb-Cr-wertepaaren nur ein einzelner mittelwert gebildet und in form eines vertretenden wertepaars weitergereicht wird.
empfangsseitig wird Y'CbCr in heutigen programmen sofort wieder in vier unabhängige RGB pixel mit 16 od. 32bit fließkommadarstellung bzw. rechengenauigkeit zurückübersetzt und für alle weiteren bearbeitungsschritte herangezogen. das ganze dreht sich also wirklich nur um den flaschenhals der übertragung.
wichtig ist diese trennung der beiden schritte deshalb, weil man oft geneigt ist, den RGB werten 8 oder 10bit abstufungen zuzuschreiben, was leider in dieser einfachen weise nicht stimmt.
Antwort von MLJ:
@All
Off-Topic:
Zunächst finde ich es nicht gut wie Teile dieser Diskussion geführt wurden nachdem ich mich durch die ganzen Beiträge durchgelesen habe und hätte mir mehr Sachlichkeit gewünscht statt persönlicher Anfeindungen.
Zum Thema:
Es sollte jedem klar sein dass man aus einem 4:2:0 nie "echtes" 4:4:4 zaubern kann ohne Fehlfarben dabei zu generieren. Das ist der Grund warum man das Format während der Produktion und Schnitt nicht wechselt, Codec inklusive um die Qualität nicht zu "verschlimmern".
Ich schlage vor ihr schaut euch mal diese Seiten an:
https://en.wikipedia.org/wiki/YCbCr
https://en.wikipedia.org/wiki/YPbPr
https://msdn.microsoft.com/en-us/librar ... 85%29.aspx
http://wolfcrow.com/blog/whats-the-diff ... and-ycbcr/
Diese hier besonders:
https://forums.adobe.com/thread/825920
Auf die Frage "Warum wird dann 4:2:0 verwendet und kein 4:4:4 ?" gibt es eine simple Antwort: Es ist das schnellste Format und einfacher zu komprimieren als 4:2:2 oder 4:4:4 denn eine verlustfreie Variante wäre einfach zu teuer. Ein weiterer Grund für 4:2:0 ist dass DVD und BluRay sowie viele Internet Portale dieses Format verwenden oder favorisieren.
Beim "Downscaling" einen "Nearest Neighbour" Algorithmus zu wenden ist die schlechteste Lösung, hier sind die wichtigsten Unterschiede:
Nearest neighbor (point sampling)
Choose the nearest source pixel. This results in the crispest video, but has sparkling and "chunkiness" problems. It is the fastest resampling mode and is useful for previews.
Bilinear (triangle interpolation filter)
Compute the desired pixel by linearly averaging the closest four source pixels. This gives a considerably better result than nearest neighbor, but results in a lot of blurring and gives diamond-shaped artifacts when enlarging. This is the resampling mode for most 3D texture mappers and interpolating video hardware overlays. High-ratio shrink operations (<~60% or so) will give aliasing with this mode and for those the precise bilinear mode should be used instead.
Bicubic (cubic spline interpolation filter)
Compute the desired pixel by fitting cubic spline curves to the closest 16 source pixels. This gives a sharper result than the bilinear filter, although when enlarging it results in a slight halo (ringing) around edges. High-ratio shrink operations (<60>4 for shrinking. This mode is the same as bilinear for enlargement but gives better results when shrinking.
Precise bicubic (cubic spline decimation filter)
Compute the desired pixel by applying a triangle filter to the closest N source pixels, where N=16 for enlarging and N>16 for shrinking. This mode is the same as bicubic for enlargement but gives better results when shrinking. Three different modes are given, A=-1.0, A=-.75, and A=-0.6. These vary the "stiffness" of the cubic spline and control the peaking of the filter, which perceptually alters the sharpness of the output. A=-0.6 gives the most consistent results mathematically, but the other modes may produce more visually pleasing results.
Lanczos3 (three-lobed decimation filter)
Compute the desired pixel by applying a three-lobed sinc filter to the closest N source pixels, where N=64 for enlarging and N>64 for shrinking. This produces slightly better results than the precise bicubic mode, at the expense of slower speed and more haloing (ringing). However, for a single pass the difference is very small and you should consider using precise bicubic instead.
Quelle: VirtualDub
Damit bin ich raus aus diesem Thema da alles andere bereits hier zur Genüge und ausführlich geschrieben wurde.
Cheers
Mickey
Antwort von Bommi:
Roland Schulz - peinlich von mir, ist mir überhaupt nicht aufgefallen, obwohl es aber bei normalem Hinsehen sofort in das Auge sticht.
Wot??? Das ist ein Rechtschreibfehler gewesen? Und ich hab dich all' die Monate als den Erfinder der 'Regressiven Ironie' bewundert
:-/
Si tacuisses, philosophus mansisses. ;-)
Ich will nicht noch eine neue Diskussion anzetteln, aber wenn es denn wirklich so einfach ist, aus 4K 4:2:0 ein hochwertiges FHD-Signal mit 4:4:4 zu machen, warum kann das kein Consumergerät ?
Aus dem Grund, weswegen man mit Chroma-Unterabtastung überhaupt angefangen hat: Es sind weniger Daten zu speichern, zu verarbeiten und zu übertragen.
Auch müsste man in Kameras gar nicht von 4:2:0 nach 4:4:4 umrechnen, denn man könnte über 4:4:4 direkt verfügen.
So isses.
Bei den meisten Foristen (inklusive WoWu; obiges 'Hersteller-Argument' ist ja auch seines) scheint der Eindruck zu sein, dass eine 4:2:0-Aufzeichnung eine minderwertige Video-Qualität wegen minderwertiger Produktionsmittel bedeutet. Das stimmt nicht. Es ist eine Möglichkeit, massiv Bandbreite einzusparen. Und weil 4:2:0 an das menschliche Sehvermögen angepasst ist, könnte man es mit den psychoakustischen Modellen der Audiokomprimierung vergleichen.
Für einen Consumer ist 4:2:0 also perfekt, und zwar nicht nur dann, wenn er seine Aufnahme gar nicht verarbeiten will, sondern auch dann, wenn er sie noch ein wenig aufbereiten will. Denn wegen der deutlich reduzierten Datenmenge kann er mit der ihm zur Verfügung stehenden Hard- und Software mehr an Qualiät herausholen, als ihm 4:4:4 in seinem ohnehin minimalen Workflow bieten würde (zumal er final ohnehin nach 4:2:0 enkodieren müsste).
Ein Profi wird auf Komprimierung verzichten, wo immer es möglich und praktikabel ist.
Das Zeilensprung-Verfahren war damals auch sinnvoll, heute ist es mehrheitlich nur noch Quark.
Ist es nicht, sondern eine auch heute noch phantastische Methode, die Bandbreite eines Videos zu halbieren. Leider wird es nicht mehr angeboten. Ich hätte nichts dagegen, wenn z.B. meine FZ1000 4K mit 50i/60i bei 100 MBit/s aufzeichnen würde. Technisch wäre es problemlos möglich.
- hab ich was vergessen?!
Vergessen nicht, aber vielleicht übersehen?
4:4:4 ist kein heiliger Gral, in dessen Besitz man erst mühsam gelangen muss, um einen Schluck daraus nehmen zu können. 4:4:4 bedeutet einfach nur, dass jeder (wahrnehmbare) Bildpunkt seine individuelle Farbe darstellt (und das hat der liebe Gott ja ohnehin so vorgesehen).
Bei einer 4:2:0-Aufzeichnung teilen vier Bildpunkte sich eine Farbe, und zwar einen errechneten durchschnittlichen Farbwert. Bei der Dekodierung der Aufzeichnung wird dieser eine Farbwert auf alle vier Bildpunkte angewandt, was zu einer Unschärfe des Bildes bei der Farbe führt. Und hier haben wir den tatsächlichen Nachteil der Datenreduktion via Farbunterabtastung nach 4:2:0 - die Farbunschärfe.
Die Farbunschärfe als Teil der Bildunschärfe vermindert sich bei jedem Downscaling. Bei jedem!
Wir alle haben schon die Erfahrung gemacht, dass ein verunglücktes Foto oder ein Foto aus einer Billig-Digitalkamera oder ein zu stark komprimiertes Foto, auf dem z.B. eine Rasenfläche oder Konturen matschig sind, nach einer Reduktion der Auflösung knackiger aussehen. Nichts anderes passiert beim Downscaling eines 4k-Videos nach Full HD auch mit der Abbildung von Farbe.
Und hier ist der Grund, warum ich dieses Posting hier absetze:
wenn ich
4k aufnehme, und dieses 4k footage dann
auf 1920x1080 ändere ... habe ich dann DEFINITIV ein 1080 4:4:4 ??
Ja, das hast du dann definitiv. Aber das ist für dich nur von Vorteil im Fall schwacher Hardware, denn vorher hattest du etwas besseres: 4:2:0 in 4k!
4:4:4 ist fürs Keyen und fürs Grading viel besser als 4:2:0 - aber nur bei gleicher Auflösung.
Wenn dir 4k-Footage zur Verfügung steht und dein Rechner es verarbeiten kann, dann nutze es gefälligst! Das 4k-Footage hat nämlich - bezogen auf das final down-gescalte Full HD-Video - die gleiche Farbschärfe PLUS die vierfache Helligkeitsschärfe.
Außerdem kann man die bekannten Vorteile von '4k zu Full HD' nutzen: Kadrieren, Zoomen, Schwenken, Tilten - alles in Post. Je kleiner der jeweils verwendete Ausschnitt aus dem 4k-Video ist, umso geringer ist der erzielbare Gewinn an Farbschärfe. Aber der Vorteil, alle Verarbeitungsschritte auf mehr Bildpunkte anwenden zu können (somit Redundanz zur Verfügung zu haben), ist sicherlich in jedem Fall größer als ein vorangestellter Downscale auf Full HD in 4:4:4.
So. Das wollt' ich mal eben loswerden trotz meiner Sorge, damit dienstag_01 aufgeweckt zu haben, der dann fröhlich krähend aus seiner Kiste springt.
Dank an Roland Schulz für die Zeit, die er in das Thema investiert hat.
Antwort von Roland Schulz:
WAS WAR DENN DAS ;-)?!?!?!
@All
Off-Topic:
Zunächst finde ich es nicht gut wie Teile dieser Diskussion geführt wurden nachdem ich mich durch die ganzen Beiträge durchgelesen habe und hätte mir mehr Sachlichkeit gewünscht statt persönlicher Anfeindungen.
Das läuft hier häufiger so und gleicht ggf. nen zu flachen Blutdruck aus ;-) - ne, schon richtig, müsste auch nicht sein, "man" ließ sich aber nicht überzeugen und fing an zu pöbeln. Da ich mir aber nicht in die Socken p..... lasse hat sich das dann aufgeschaukelt. Andere vertraten ihre Meinung mit Publikationen und "Professoren" im Rücken - als ich Kind war hatte mein Papi auch immer Recht und war quasi das Gesetz - auch die wurden denke ich mal überzeugt, sind aber im Nichts verschwunden - auch gut!
Ich denke "gewonnen" hat hier keiner, einige haben eher verloren!
Verloren haben wowu und ich denke ich, und zwar ein wenig an Respekt voreinander. Andere sind irgendwann auch in den ein oder anderen Strom geraten und sind "verkauft" worden, wer wie und durch wen sei jetzt mal dahingestellt.
Vielleicht haben einige ein paar neue Erkenntnisse erlangt, weil man einfach noch mal neu über eine Sache nachgedacht hat oder sogar was Neues dazu gelernt hat, ggf. auch ein falsches Verständnis aufgeklärt hat.
Am Ende ist für mich hier und heute alles in Ordnung und vergessen, man hat "diskutiert" und ein paar Emotionen ins Spiel gebracht. Für mich ist alles gut und vergessen!! Wolfgang?!?!
Zum Thema:
Es sollte jedem klar sein dass man aus einem 4:2:0 nie "echtes" 4:4:4 zaubern kann ohne Fehlfarben dabei zu generieren.
Die Fehlfarben sind schon drin, die stecken sowohl im 4:2:0 als auch im 4:4:4, da allerdings etwas "schmaler". Beim Downscaling kommen aber keine neuen dazu, das ist ausgeschlossen da die Farbmatrix des 4:2:0 1:1 in das 4:4:4 bei Halbierung der h/v Dimension übernommen werden kann!
Das ist der Grund warum man das Format während der Produktion und Schnitt nicht wechselt, Codec inklusive um die Qualität nicht zu "verschlimmern".
Ich schlage vor ihr schaut euch mal diese Seiten an:
https://en.wikipedia.org/wiki/YCbCr
https://en.wikipedia.org/wiki/YPbPr
https://msdn.microsoft.com/en-us/librar ... 85%29.aspx
http://wolfcrow.com/blog/whats-the-diff ... and-ycbcr/
Diese hier besonders:
https://forums.adobe.com/thread/825920
Denke darüber sind wir hier (fast) alle hinaus, die den Thread "im Detail" mitverfolgt haben ;-).
Auf die Frage "Warum wird dann 4:2:0 verwendet und kein 4:4:4 ?" gibt es eine simple Antwort: Es ist das schnellste Format und einfacher zu komprimieren als 4:2:2 oder 4:4:4 denn eine verlustfreie Variante wäre einfach zu teuer. Ein weiterer Grund für 4:2:0 ist dass DVD und BluRay sowie viele Internet Portale dieses Format verwenden oder favorisieren.
Bei den meisten Bayer Kameras bringt"s einfach nix 4:2:2 oder höher einzusetzen und Bandbreite zu verballern bzw. das Verhältnis zwischen Luminanzauflösung und Farbauflösung Richtung Farbe zu verschieben, damit die verfügbare Bandbreite oder "Bitrate" in Richtung Luma einzuschränken.
Wenn die Quelle aber mehr kann tut man immer gut daran, im Workflow das bestmögliche Format zu wählen und erst zum Schluss in das Zielformat zu gehen. Wenn Du eine 50i BD erstellen willst solltest Du schon in 50p aufnehmen wenn es geht, so lässt sich beim Schnitt ggf. hier oder da nochmal croppen. Hätten wir bereits 50i bei der Aufnahme eingesetzt wäre da nicht mehr viel machbar. Ebenso verhält es sich mit der Quantisierung, Bitrate, Unterabtastung usw..
Beim "Downscaling" einen "Nearest Neighbour" Algorithmus zu wenden ist die schlechteste Lösung, hier sind die wichtigsten Unterschiede:
Nearest neighbor (point sampling)
Choose the nearest source pixel. This results in the crispest video, but has sparkling and "chunkiness" problems. It is the fastest resampling mode and is useful for previews.
Aus dem Kontext (WoWu) sollte klar hervorgegangen sein, dass eine Methode in Frage gestellt wurde, die das Downscaling wie von mir beschrieben überhaupt beherrscht. Nearest Neighbor wird prinzipbedingt das Chromasignal NICHT verändern oder interpolieren. Das bei den anderen Methoden nachzuvollziehen oder gar nachzuweisen würde eher schwierig.
Dazu muss man im Thread aber echt "am Gas" bleiben um den Hintergrund und Sinn zu verstehen. Ansonsten gebe ich Dir Recht bzgl. NN...
Antwort von Roland Schulz:
Bei den meisten Foristen (inklusive WoWu; obiges 'Hersteller-Argument' ist ja auch seines) scheint der Eindruck zu sein, dass eine 4:2:0-Aufzeichnung eine minderwertige Video-Qualität wegen minderwertiger Produktionsmittel bedeutet. Das stimmt nicht. Es ist eine Möglichkeit, massiv Bandbreite einzusparen. Und weil 4:2:0 an das menschliche Sehvermögen angepasst ist, könnte man es mit den psychoakustischen Modellen der Audiokomprimierung vergleichen.
Immer gut wenn es andere besser wissen was ich sehe und auch höre ;-)!
Hätte ich genug Bandbreite und eine ordentliche Quelle wäre "nativ" immer besser!
Ein Profi wird auf Komprimierung verzichten, wo immer es möglich und praktikabel ist.
Da ist doch mal ein wahres Wort gesprochen!!!
Das Zeilensprung-Verfahren war damals auch sinnvoll, heute ist es mehrheitlich nur noch Quark.
Ist es nicht, sondern eine auch heute noch phantastische Methode, die Bandbreite eines Videos zu halbieren. Leider wird es nicht mehr angeboten. Ich hätte nichts dagegen, wenn z.B. meine FZ1000 4K mit 50i/60i bei 100 MBit/s aufzeichnen würde. Technisch wäre es problemlos möglich.
Aber wehe Du willst mal croppen, ne slomo oder nen Zeitraffer machen ;-)!!!
- hab ich was vergessen?!
Vergessen nicht, aber vielleicht übersehen?
4:4:4 ist kein heiliger Gral, in dessen Besitz man erst mühsam gelangen muss, um einen Schluck daraus nehmen zu können. 4:4:4 bedeutet einfach nur, dass jeder (wahrnehmbare) Bildpunkt seine individuelle Farbe darstellt (und das hat der liebe Gott ja ohnehin so vorgesehen).
Bei einer 4:2:0-Aufzeichnung teilen vier Bildpunkte sich eine Farbe, und zwar einen errechneten durchschnittlichen Farbwert. Bei der Dekodierung der Aufzeichnung wird dieser eine Farbwert auf alle vier Bildpunkte angewandt, was zu einer Unschärfe des Bildes bei der Farbe führt. Und hier haben wir den tatsächlichen Nachteil der Datenreduktion via Farbunterabtastung nach 4:2:0 - die Farbunschärfe.
Die Farbunschärfe als Teil der Bildunschärfe vermindert sich bei jedem Downscaling. Bei jedem!
Wir alle haben schon die Erfahrung gemacht, dass ein verunglücktes Foto oder ein Foto aus einer Billig-Digitalkamera oder ein zu stark komprimiertes Foto, auf dem z.B. eine Rasenfläche oder Konturen matschig sind, nach einer Reduktion der Auflösung knackiger aussehen. Nichts anderes passiert beim Downscaling eines 4k-Videos nach Full HD auch mit der Abbildung von Farbe.
...alles bekannt und Teil der Diskussion ;-), wobei man beim Rasen jetzt nicht unbedingt 4:4:4 bräuchte, ein gutes Beispiel warum hier Luma klar vorgeht, die Farbe ist "relativ" gleich, ES SEI DENN ES STÜNDEN ROTE MINIBLÜMCHEN IN DER WIESE ;-)!!!
Und hier ist der Grund, warum ich dieses Posting hier absetze:
wenn ich
4k aufnehme, und dieses 4k footage dann
auf 1920x1080 ändere ... habe ich dann DEFINITIV ein 1080 4:4:4 ??
Ja, das hast du dann definitiv. Aber das ist für dich nur von Vorteil im Fall schwacher Hardware, denn vorher hattest du etwas besseres: 4:2:0 in 4k!
DEFINITV (allgemein) FALSCH!!! Selbst die "Profisoftware" EDIUS (ich mag das!!) kann intern überhaupt KEIN 4:4:4 :-p ;-)!!! "Besser" war"s vorher, richtig!! - der Grund warum wowu und ich diesen (Un)Sinn auch mehrfach in Frage gestellt haben.
4:4:4 ist fürs Keyen und fürs Grading viel besser als 4:2:0 - aber nur bei gleicher Auflösung.
Das nächste wahre Wort - aber auch bereits bekannt und diskutiert, zur Erinnerung nach dem ganzen Stress aber nochmal GUT!!
Wenn dir 4k-Footage zur Verfügung steht und dein Rechner es verarbeiten kann, dann nutze es gefälligst! Das 4k-Footage hat nämlich - bezogen auf das final down-gescalte Full HD-Video - die gleiche Farbschärfe PLUS die vierfache Helligkeitsschärfe.
SO SIEHT"S AUS!!!
Antwort von Jan:
Das Zeilensprung-Verfahren war damals auch sinnvoll, heute ist es mehrheitlich nur noch Quark.
Ist es nicht, sondern eine auch heute noch phantastische Methode, die Bandbreite eines Videos zu halbieren. Leider wird es nicht mehr angeboten. Ich hätte nichts dagegen, wenn z.B. meine FZ1000 4K mit 50i/60i bei 100 MBit/s aufzeichnen würde. Technisch wäre es problemlos möglich.
Neben dem was Roland zu dem Thema gesagt hat, macht es fast keinen Sinn mehr aktuell mit Halbbilder zu arbeiten. Unsere aktuellen Wiedergabegeräte arbeiten ja alle progressiv, auch wenn sie mit Halbbildern umgehen können, was aber eben deinterlaced werden muss, und das eher eine Nachteil als einen Vorteil ist. Und das die Datenflut bei 50P viel größer als bei 50i sein soll, ist auch Quatsch. Ich habe dazu die letzten Jahre viele Kameras durchgetestet, die noch über eine Vielzahl an Frameraten mit Halbbildern- und Vollbildern aufzeichnen. Man erhält eben nicht die doppelte Datenmenge bei der 50P-Aufzeichnung gegenüber einer 50i Aufzeichnung mit gleicher Auflösung. Die meisten aktuellen Varianten (Beispiel H.264) sind dafür verantwortlich. Bei Intraframeaufzeichnung mag das stimmen, nur wird das aktuell eher nur im Profisegment angeboten. Panasonic beispielsweise hatte wirklich lange Zeit in den Video-Kameras zwei Modis der besten Bildqualität, FHD/50i mit 24 MBit und FHD/50P mit 28 MBit. Das waren gerade mal 4 MBit-Unterschied. Bei Sony-Videokameras ist das ähnlich. Die FZ1000 hat den 24 MBit-Modus mit 50i gestrichen und bietet eben "nur" den 50i-Modus mit 17MBit an, den gabe es aber früher auch bei den Panasonic-Videokamera neben 24 Mbit/50i und 28 Mbit/50P.
Eben weil keine reine Einzelbildaufzeichnung bei H.264 oder vergleichbaren Codecs mehr durchgeführt wird, ist die Framerate für den Speicherplatz weniger ausschlaggebend. Ich hatte das auch mal hier bei Nikon-DSLR dargelegt, wieviel Platz den 1080 mit 25P, 30P, 50i oder 50P-Aufzeichnung gebraucht wird, die Unterschiede waren nicht so groß, wie man es nach der Framezahl und Halbbild- und Vollbildaufzeichnung hätte denken können. Beispielsweise ist eben eine FHD/25P-Datei nicht halb so groß wie eine FHD/50P-Datei der gleichen Kamera.
VG
Jan
Antwort von Jott:
Dieser 50i-Quatsch ist heute Standard bei Fernsehanstalten und beileibe nicht verschwunden. Ist für Consumer natürlich irrelevant und sinnlos, aber wer was mit TV zu tun haben will, muss umdenken. Fernseher können prima mit 1080i50 und 576i50 umgehen - ganz einfach weil sie müssen! Siehst du in der Fernseher-Abteilung deines Marktes in voller Pracht. Hat jetzt aber mal gar nichts mit dem Thema zu tun.
Antwort von Valentino:
Beispielsweise ist eben eine FHD/25P-Datei nicht halb so groß wie eine FHD/50P-Datei der gleichen Kamera.
Der Grund dafür liegt in der Natur der GoP Struktur. Es wird ja zwischen den Keyframes immer nur die Differenz gespeichert und wenn man jetzt die Zeitliche Auflösung mit der Verdoppelung der Bildrate verändert, so wird die Differenz zwischen den Bildern kleiner. Damit wird die Datei am Ende meistens 1,3 mal größer und nicht doppelt so groß wie bei reiner Intra-Frame Aufzeichnung.
Wenn man ein 25p Video einfach auf 50p hochzieht (alle Bilder zweimal zeigt und keine Bewegungen hinzuzurechnen), so sollte das 50p Video sogar fast gleichgroß bleiben.
Alles Nix Neues.
@Roland Schulz
Durch dein "Geschrei" und das wiederholen deiner Thesen werden diese nicht richtiger.
So langsam kann man diesen Thread schließen.
Antwort von Jan:
Ich dachte es wäre klar, wenn man auf eine rein progressive Kette (Kamera+TV/Monitor) setzt , dass das dann Vorteile bietet. Auch wenn ein Deinterlacing bei den Fernsehern gut durchgeführt wird, ist es trotzdem verlustbehafteter als eine reine progressive Aufnahme. Mir ist schon klar das viele TV-Sender immer noch interlaced ausstrahlen, das habe ich aber nicht verneint. Es ging nur um die aktuellen Kameras, die beide Möglichkeiten bieten. In dem Fall macht eine Interlaced-Aufnahme fast nie Sinn, auch weil wie von mir beschrieben die Vollbild-Datei kaum größer ausfällt. Da die aktuellen Speicherkarten recht schnell und günstig sind, macht das noch weniger Sinn, wegen ein paar Bit auf das Halbbild zu setzen. Beim TV und den hohen Sendekosten sieht die Sache aber wieder anders aus, aber das wird sich früher oder später auch ändern.
VG
Jan
Antwort von Jan:
Beispielsweise ist eben eine FHD/25P-Datei nicht halb so groß wie eine FHD/50P-Datei der gleichen Kamera.
Der Grund dafür liegt in der Natur der GoP Struktur. Es wird ja zwischen den Keyframes immer nur die Differenz gespeichert und wenn man jetzt die Zeitliche Auflösung mit der Verdoppelung der Bildrate verändert, so wird die Differenz zwischen den Bildern kleiner. Damit wird die Datei am Ende meistens 1,3 mal größer und nicht doppelt so groß wie bei reiner Intra-Frame Aufzeichnung.
Wenn man ein 25p Video einfach auf 50p hochzieht (alle Bilder zweimal zeigt und keine Bewegungen hinzuzurechnen), so sollte das 50p Video sogar fast gleichgroß bleiben.
Alles Nix Neues.
Für Bommi scheint das aber etwas neues zu sein....
VG
Jan
Antwort von Roland Schulz:
@Roland Schulz
Durch dein "Geschrei" und das wiederholen deiner Thesen werden diese nicht richtiger.
So langsam kann man diesen Thread schließen.
Was bedeutet 4:4:4 bezogen auf die Pixelebene ;-) !?!?!?!
Antwort von Jott:
Die Produktiionsinfrastrukter der Sender basiert auf XDCAM 422 oder AVC Intra. Beides kann und kennt kein 1080p50, so einfach ist das. Vieles ist im Zuge der immer noch nicht abgeschlossenen Umstellung auf HD neu angeschafft worden oder wird gerade angeschafft. Daher bleibt Interlaced noch lange erhalten, denn neben dem abgeschafften 720p bleibt in dieser veralteten Infrastruktur nur 1080i50 für flüssige Bewegungen. So wird auch überall gesendet, nur wenige konvertieren für den Sendeweg zu 720p runter.
Vor diesem Hintergrund sind die hier diskutierten 4K-Dinge Luxussorgen hoch zehn! Wenn klamme Hobbyisten die millionengestopften Broadcaster technisch mit links überholen, ist das schon lustig.
Antwort von TheBubble:
Daher bleibt Interlaced noch lange erhalten, denn neben dem abgeschafften 720p bleibt in dieser veralteten Infrastruktur nur 1080i50 für flüssige Bewegungen. So wird auch überall gesendet, nur wenige konvertieren für den Sendeweg zu 720p runter.
DVB-T2 HD wird bereits in 1080p50 gesendet. Es ist also gar nicht so abwegig, dass zukünftig auch auf anderen Verbreitungswegen in dieser Auflösung gesendet werden wird.
Daher ist es durchaus sinnvoll, zukünftig ohne Zeilensprungverfahren zu produzieren.
Antwort von Jott:
Das musst du den Sendern erzählen. Die DVB-Inhalte werden aufgeblasen.
Die verlangen von Zulieferern explizit 1080i50 (oder 25p). Mit 1080p50 kannst du dort nicht punkten. No way nach Pflichtenheften. Gibt's nicht. Wann sich das mal ändert, steht in den Sternen.
Und der aufgeregte Slashcamer fordert 4K 10Bit 4:2:2 50p für alle ein! Was für ein Unterschied!
Antwort von TheBubble:
Das musst du den Sendern erzählen. Die DVB-Inhalte werden aufgeblasen.
Das habe ich auch gelesen. Allerdings soll laut c't 13/2016 bei den Nachrichten eines Senders wenigstens das Logo in 1080p erscheinen. Es müsste folglich (beim DVB-T2 HD Betreiber) inzwischen in 1080p50 angeliefert werden.
Was die Privaten über DVB-T2 HD machen weiß ich - mangels Entschlüsselungsmodul - bisher nicht. Hat da jemand aktuelle Infos?
Antwort von Bommi:
Für Bommi scheint das aber etwas neues zu sein....
Was ist denn das für eine schräge Unterstellung!?! Zu 25p vs. 50p hab ich mich weder hier noch anderswo geäußert.
Ich habe geschrieben, dass ich mit meiner Consumer-Kamera gerne 4k-Video als i50 bzw. i60 aufzeichnen würde. Mehr als 100 MBit/s müssten und sollten dabei nicht gespeichert werden. Kann schon sein, dass ein Video-Encoder ein progressives Bild wegen 'mehr Fleisch' effektiver komprimieren kann als Interlaced, aber der Unterschied dürfte sich unteren einstelligen Prozentbereich befinden. Interlaced bedeutet ja nur eine niedrigere vertikale Auflösung
warum sollte die wesentlich schlechter zu komprimieren sein?
Ich habe dazu die letzten Jahre viele Kameras durchgetestet, die noch über eine Vielzahl an Frameraten mit Halbbildern- und Vollbildern aufzeichnen. Man erhält eben nicht die doppelte Datenmenge bei der 50P-Aufzeichnung gegenüber einer 50i Aufzeichnung mit gleicher Auflösung.
Da hat die Kamera sich wohl gedacht: "Donnerwetter, nun hat der gute Jan also auf Interlaced umgeschaltet. Wahrscheinlich will er eine Blu-ray erstellen und strebt dazu einen Interlaced-Workflow von der Kamera bis zur Scheibe an. Dann will ich mal geschwind die Kompression reduzieren, um ihm möglichst hochwertiges Footage zu liefern. Die dazu notwendige Kapazität habe ich ja, weil bei Interlaced nur halbe Pixelzahl pro Frame anfällt."
Die FZ1000 hat den 24 MBit-Modus mit 50i gestrichen und bietet eben "nur" den 50i-Modus mit 17MBit an, den gabe es aber früher auch bei den Panasonic-Videokamera neben 24 Mbit/50i und 28 Mbit/50P.
Ja, früher vs. heute. In der FZ kann der AVCHD-Codec noch Interlaced enkodieren, wobei 17 MBit/s noch AVCHD-Disk-kompatibel ist und darüber nicht. Bei einer Consumer-Kamera, die 4k mit 100 MBit/s aufzeichnen kann, ist 1080i einfach unnötig. Bei einer EB- oder Streaming-Kamera dagegen nicht. Für 4k würde Interlaced ohne Mehraufwand die doppelte Bildwiederholrate ermöglichen.
Kleine Info zum Deinterlacen:
Oft haben die Leute noch immer eine falsche Vorstellung davon. Das liegt auch daran, dass es meist falsch oder umständlich erklärt wird. Wer den Wikipedia-Eintrag zum Deinterlacing liest, muss zwangsläufig Depressionen bekommen. Falsch ist es nicht, was dort steht und für den historisch Interessierten vielleicht sogar spannend. Aber nur das dort beschriebene adaptive Verfahren hat etwas mit der Realität zu tun.
Ich schreib mal kurz runter, wie ich mir mein Recherche-Ergebnis gemerkt habe (ist also keine offizielle Wahrheit):
Ein heutiger Deinterlacer generiert die fehlende Hälfte eines Bildes. Er macht es, indem er von jeder fehlenden Zeile die entsprechende Zeile aus dem vorhergehenden und dem nachfolgenden Frame nimmt und daraus eine neue Zeile interpoliert. Diese erzeugte Zeile wird an die Zeilen darüber und darunter angepasst, und zwar unter Zuhilfenahme von Bildanalyse des aktuellen Frames und Bewegungsanalyse einiger umliegenden Frames.
Dieses Deinterlacen funktioniert so gut, dass selbst billigste No-name TV-Geräte, BD-, DVD- und Media-Player es perfekt in Echtzeit beherrschen. Software, angetrieben von GHz-CPU's und mit aller Zeit der Welt, kann's noch besser. Interlaced würde somit auch im Akquise-Codec einer Consumer-Kamera Sinn machen, wie es früher bei AVCHD für Full HD der Fall war. Und darum hätte ich gern 4k i50 bei 100 MBit/s.
Antwort von TheBubble:
Dieses Deinterlacen funktioniert so gut, dass selbst billigste No-name TV-Geräte, BD-, DVD- und Media-Player es perfekt in Echtzeit beherrschen.
Da möchte ich widersprechen.
Software, angetrieben von GHz-CPU's und mit aller Zeit der Welt, kann's noch besser. Interlaced würde somit auch im Akquise-Codec einer Consumer-Kamera Sinn machen, wie es früher bei AVCHD für Full HD der Fall war. Und darum hätte ich gern 4k i50 bei 100 MBit/s.
Interlacing macht heute nur selten und zukünftig keinen Sinn mehr. Je schneller das Zeilensprungverfahren verschwindet, desto besser.
Wenn man die Datenrate senken will, dann kann man das anderweitig besser tun.
Antwort von cantsin:
Dieses Deinterlacen funktioniert so gut, dass selbst billigste No-name TV-Geräte, BD-, DVD- und Media-Player es perfekt in Echtzeit beherrschen. Software, angetrieben von GHz-CPU's und mit aller Zeit der Welt, kann's noch besser. Interlaced würde somit auch im Akquise-Codec einer Consumer-Kamera Sinn machen, wie es früher bei AVCHD für Full HD der Fall war. Und darum hätte ich gern 4k i50 bei 100 MBit/s.
Sorry, aber das ist doch Unsinn. Wenn es Dir schon um radikale Datenersparnis durch halbierte vertikale Auflösung geht, dann wäre ein anamorphes 1920x540p-Bild, für das dann das Abspielgerät die fehlenden Zeilen interpolieren würde, besser als 1080i - übrigens auch besser zu komprimieren.
Das Zeilensprungverfahren ist ein Überbleibsel aus der Zeit der Fernsehröhre, als Kathodenstrahlen nicht schnell genug waren, um ein vollaufgelöstes Bild zu zeichnen und stattdessen jeweils ein Habbild per Durchlauf an den Schirm warfen.
Im Zeitalter von Flatscreens ist Interlacing kompletter Blödsinn.
Antwort von Roland Schulz:
@Roland Schulz
Durch dein "Geschrei" und das wiederholen deiner Thesen werden diese nicht richtiger.
So langsam kann man diesen Thread schließen.
Was bedeutet 4:4:4 bezogen auf die Pixelebene ;-) !?!?!?!
Semesterferien ;-)?!? Kein Prof. greifbar???
Antwort von Jan:
Das Zeilensprung-Verfahren war damals auch sinnvoll, heute ist es mehrheitlich nur noch Quark.
Ist es nicht, sondern eine auch heute noch phantastische Methode, die Bandbreite eines Videos zu halbieren. Leider wird es nicht mehr angeboten. Ich hätte nichts dagegen, wenn z.B. meine FZ1000 4K mit 50i/60i bei 100 MBit/s aufzeichnen würde. Technisch wäre es problemlos möglich.
Da brauchst du dich jetzt auch nicht mehr rauszureden, wie man deinem Text entnehmen kann, hattest du davon keine Ahnung und eben geglaubt, dass die Datenrate bei gleicher Auflösung bei Vollbilddarstellung doppelt so groß ist bei gleicher Framerate. Eben noch nichts von Interframe-Kompression gehört, die auch in deiner FZ1000 eingesetzt wird. Deine Deinterlaced-Beurteilung setzt dem noch die Krone auf. Das ansich ist überhaupt kein Problem, wenn nicht dein Wichtigtuer und Belehrton in jedem deiner Beiträge mitwirken würde.
Und wenn Jott dir jetzt mit 50i zur Seite springt, weil es ja für das Verkaufen des Material an Sender sinnvoll ist, möchte ich hier gern fragen, wer verkauft Material regelmäßig an Sender ? 5 Slashcamuser von 50.000 Slashcam-Usern ? Liege ich da richtig ?
PS: Hier sind aktuell leider immer mehr Dampfplauderer der schlimmen Sorte als Kenner der Materie am Werk, dazu dieser oft überhebliche verletztende Ton. Und wenn der User falsch liegt, dreht man den Kontext einfach um, und versucht sich rauszuwinden, obwohl man auch mal eingestehen könnte, dass man falsch lag. Schade, dass war zu Beginn des neu gestarteten Forums im Jahr 2005 noch ganz anders hier, ich hoffe mal nicht, dass das der Untergang von Slashcam bedeutet. Es macht nämlich mehrheitlich wenig Spaß hier etwas zu schreiben, ohne blöd von der Seite angemacht zu werden. Die Seite wird nicht mehr mit guten Ratschlägen und Tipps verbunden, sondern von mehreren Usern als Commedy-Seite gesehen.
VG
Jan
Antwort von Roland Schulz:
Das Zeilensprung-Verfahren war damals auch sinnvoll, heute ist es mehrheitlich nur noch Quark.
Ist es nicht, sondern eine auch heute noch phantastische Methode, die Bandbreite eines Videos zu halbieren. Leider wird es nicht mehr angeboten. Ich hätte nichts dagegen, wenn z.B. meine FZ1000 4K mit 50i/60i bei 100 MBit/s aufzeichnen würde. Technisch wäre es problemlos möglich.
Da brauchst du dich jetzt auch nicht mehr rauszureden, wie man deinem Text entnehmen kann, hattest du davon keine Ahnung und eben geglaubt, dass die Datenrate bei gleicher Auflösung bei Vollbilddarstellung doppelt so groß ist bei gleicher Framerate. Eben noch nichts von Interframe-Kompression gehört, die auch in deiner FZ1000 eingesetzt wird. Deine Deinterlaced-Beurteilung setzt dem noch die Krone auf. Das ansich ist überhaupt kein Problem, wenn nicht dein Wichtigtuer und Belehrton in jedem deiner Beiträge mitwirken würde.
Und wenn Jott dir jetzt mit 50i zur Seite springt, weil es ja für das Verkaufen des Material an Sender sinnvoll ist, möchte ich hier gern fragen, wer verkauft Material regelmäßig an Sender ? 5 Slashcamuser von 50.000 Slashcam-Usern ? Liege ich da richtig ?
PS: Hier sind aktuell leider immer mehr Dampfplauderer der schlimmen Sorte als Kenner der Materie am Werk, dazu dieser oft überhebliche verletztende Ton. Und wenn der User falsch liegt, dreht man den Kontext einfach um, und versucht sich rauszuwinden, obwohl man auch mal eingestehen könnte, dass man falsch lag. Schade, dass war zu Beginn des neu gestarteten Forums im Jahr 2005 noch ganz anders hier, ich hoffe mal nicht, dass das der Untergang von Slashcam bedeutet. Es macht nämlich mehrheitlich wenig Spaß hier etwas zu schreiben, ohne blöd von der Seite angemacht zu werden. Die Seite wird nicht mehr mit guten Ratschlägen und Tipps verbunden, sondern von mehreren Usern als Commedy-Seite gesehen.
VG
Jan
Jan, ich glaube bei uns allen gehen hier mal die Emotionen durch, Dummschwätzer gibt's hier sicherlich auch einige, aber zum Tode verurteilt ist Interlace bestimmt noch nicht, zudem in H.264 und auch in H.265 noch potente, adaptive Mechanismen implementiert sind, mit Interlaced effektiv umzugehen.
Ich bin zwar auch absolut kein Fan von Interlaced Video, "etwas" Bandbreite spart's im Broadcast aber immerhin noch.
Bzgl. der Forenmitglieder glaube ich Deine Schätzung nicht ganz. Es sind aktuell 35288 "Members" angemeldet, davon haben >7000 noch nie einen Post geschrieben, denke mal die Anzahl der "Leichen" ist damit ebenfalls im 5 stelligen Bereich.
Wenn ich manche Diskussion so mitlese denke ich schon das wir hier >>>5 Mitglieder haben die an Sender liefern.
Ich hab mit all dem nichts zu schaffen, verdiene mein Geld anders, kann aber wirklich nicht verstehen, wie man heute als Sender noch auf Interlaced "bestehen" kann!! Das kann doch nicht sein, ist das Geld so knapp wenigstens die Annahme technisch zu ermöglichen?!?! Aus 50p kann man das Ganze immer noch auf ~6Mbit zerschrotten und interlacen! Die Aufnahme und die Verarbeitung erwarte ich eigentlich auf einem höheren Niveau...
Für die "letzte Meile" halte ich "persönlich diplomatisch" Inetrlaced immer noch für eine berechtigte Alternative. Die verfügbare Bandbreite ist zwar gestiegen, explodiert aber nicht.
Antwort von Jott:
Die Sender verlangen nicht Interlaced, weil es toll ist, sondern weil ihre Infrastruktur so aufgebaut ist und nichts anderes packt. Auch aktuell. Daher zum Beispiel der neue Sony-Broadcast-Camcorder, der NUR 1080i kann. Punktgenau für die Zielgruppe. Fällt der Groschen? Das hat auch nichts mit Bandbreitenersparnis beim Senden zu tun. Sie können und wollen halt kein 1080p50 verarbeiten, haben 720p50 bei der Akquisition abgeschafft, weil das 720er-Raster keinen Sinn mehr macht - was bleibt noch übrig mit 50 Bewegungsphasen für flüssige Realbilder? Bingo. So einfach ist das.
Zur Seite springen. Lächerlich. Es geht um eine Parallelwelt, mit der fast alle hier nichts zu tun haben, das ist sicher richtig. Aber sie existiert.
Erst mit UHD wird Interlaced verschwinden, vorher bleibt es an der Broadcastwelt kleben wie ein Kaugummi an der Sohle.
UHD 8Bit 4:2:0 sieht dagegen so gut aus, dass die Slashcam-Probleme damit schon weh tun. Ist immerhin Blu-ray mal vier, sozusagen, und wer hat ein Problem mit Blu-ray? Du meine Güte.
Antwort von WoWu:
@Bommi
Ich weiß zwar nicht, woher Du die Erkenntnis hast, Interlace würde mit der halben Bandbreite auskommen, aber sie ist auf jeden Fall falsch.
Es hat zahlreiche Vergleiche gegeben, die Interlace, progressiv gegenüber stellen, meistens auf der Basis identischer Bandbreiten, aus denen heraus dann der Störabstand gemessen wurde.
Das ist die Methode, solche Dinge zu vergleichen. Der bessere Störabstand entspricht dann auch im Umkejrschluss der geringeren Bandbreite, wenn man einen identischen Störabstand voraussetzt.
Es gibt nur einen Fall, in dem Interlace die Nase vorn hat und das ist bei 2MBit/s oberhalb dieser Bandbrmeite hat Progressiv die besseren Ergebnisse.
Es ist also, geht man einmal nicht von solchen Telefonbandbreiten aus, so, dass Interlace die schlechtere Bandbreiteneffizienz hat.
Es gibt dazu auch eine kurze Studie von Thompson Frankreich, weil bestimmt gleich wieder jemand aufpoppt, der was Anderes gehört hat, die zwar schon etwas älter ist, aber an Interlace hat seit der Zeit keiner mehr weiterentwickelt, an progressiv allerdings schon, sodass sich die Ergebnisse in Richtung progressiv eher verbessert haben werden.
In this paper, the coding efficiency of both progressive and interlaced scanning formats are compared by means of PSNR values and subjective picture quality analysis. The main goal was to evaluate the impact of using a progressive transmission format compared to the existing interlaced one. It leads to the conclusion that the absence of interlaced artifacts (mainly line flicker) allows the use of a greater compression factor in the case of progressive processing and display. At the same bit-rate an all progressive broadcasting chain, from the source capture to the final display, is thus preferable to an all interlaced one, except for an increased hardware complexity if twice the number of pels is scanned. Moreover, with interlaced display, the progressive transmission can be considered at least as good as the interlaced one and generally better if progressive sources are encoded. Unfortunately, the conclusions are not so clear when dealing with interlaced sources : the loss of resolution supersedes sometimes the reduction of blocking effects and the conversion from progressive to interlaced scanning after decoding can either improve (post-filtering of the coding artifacts) or decrease (loss of resolution) the picture quality depending on the source sequences available.
Consequently, it has been shown that progressive does not lead to a loss of performances, that on the contrary it brings a more stable picture quality, even if the MPEG-2 standard has been optimized for interlaced signals.
Thus, from a picture quality point of view, progressive scanning is a very attractive format for the transmission, and even more for the visualization of pictures. In addition, progressive can be used as an intermediate step towards progressive broadcasting of TV signals without loss of performances compared to the existing interlaced format. This is even more interesting when a smaller picture size is considered, to comply with the actual MP@ML profile (of course comparable picture quality is assumed).
Finally, if the MPEG-2 compression performances can not be significantly increased moving towards progressive scanning, compatibility with the multimedia applications (Computer, Broadcasting, Transmission, Virtuality, Film, ...) will be simplified and more efficient. This is perhaps the best way to go to.
http://www.stephanepigeon.com/Docs/pg.pdf
Die Studie hat, wie nachzulesen ist, außerdem alle NACHTEILE des Interlace Verfahrens in Bezug auf Artefaktbildung weggelassen und sich auf den reinen Störabstand, also die Bitrateneffizienz konzentriert.
Würde man diese Topics mit beleuchten, würde das zwar nichts am Störabstand ändern, aber ganz sicher an der Einschätzung der übertragbaren Qualität, denn Bildqualität an der Bamdbreite festzumachen ist grundfalsch.
Übrigens ist die Studie in MPEG2 entstanden, das speziell auf Inzerlace ausgerichtet ist.
Würde man solche Tests in MPEG4 machen, wären die Differenzen übrigens nochmals zugunsten von progressiv größer.
Nur hat da kein Mensch mehr Interesse dran, weil Interlace bald sowieso Geschichte ist, was das Abtastverfahren betrifft.
Auf dem Ünertragungsweg sieht das noch einwenig anders aus, aber da stecken dann eben progressive Bilder in einem Interlace Datenstrom und selbst für eine 4K Ausstrahlung ist ein solcher sequentiell aufgeteilter Datenstrom vorgesehen, aber das hat alles nichts mehr mit der Interlace Abtastung zu tun, die von Dir hier angesprochen ist.
Unter'm Strich: Interrlace ist in der Datenrate nur bei 2MBit/s geringfügig besser, darüber aber schlechter und schon gar nicht 50% effizienter.
@Jott
Auch nur die halbe Wahrheit, weil sich die Abnahmebedingungen des IRT sich nur auf Mainstream Content bezieht, darin aber auch gesagt wird, dass d Premiumcontent andern Anforderungen unterlegt und abgesprochen wird.
Dann kommt nämlich 10Bit 1080p/50 dabei raus. (SYSTEM 4)
Außerdem beziehst Du Dich auf "die Sender" .... stimmt auch nicht, ZDF nimmt 720p/50 vorrangig, weil dann keine Wandlung zum Ausstrahlumgsformat vorgenommen werden muss und die Verluste geringer sind.
Außerdem ist jede Interlace Infrastruktur auch in der Lage, progressive Bilder mit dem korrekten Flagging, als psf zu verarbeiten, was auch in den IRT Specs Berücksichtigung findet.
Insofern bezieht sich Interlace nicht ausschließlich auf die Abtastung.
Antwort von sgywalka is back:
Jott!
80% der sog. aufgestellten Senderhirachie ist interlaced aufgestellt. Und wie es aussieht
wird das noch bis 2021 rum so bleiben. Aber nun wegen dem 9bit (?) anfangen sich die
Augen aus zu kratzen? Wozu.
Die Hersteller lachen sich einen ab, interne 10 bit-aufzeichnugn ist längst in den Startlöchern ( und wh wieder 12-18 subertolle Formate und Karten und Adapter und die gute alte Verkaufsshow ever..) aber:
Sagten ja schon einige hier, ich glaubs auch schon... die pEST Smartphone.
4k 1-zoll prores / oder anderer normaler 10 bit-Hauscodec/ = D.O.A.
Ab den Zeitpunkt kannst hier über nur noch Arri, Red, Bmc, Sony-Canon-Panasonic reden.
Und ihre ab nun wieder 120.000 Euro Kameras.
The golden Age for Rebels 2012-2016
Seits a bissi net, so a Wirbel wegen dem, geh... never Grüsse
Antwort von Jott:
"Außerdem beziehst Du Dich auf "die Sender" .... stimmt auch nicht, ZDF nimmt 720p/50 vorrangig, weil dann keine Wandlung zum Ausstrahlumgsformat vorgenommen werden muss und die Verluste geringer sind."
Die (um)entscheiden sich gerade zu 1080i-Akquise wie die ARD und alle anderen.
Was wäre denn dein Tipp für das Ende von Interlaced-Akquise (Definition: 1080i verschwindet endgültig als Anforderung aus den Pflichtenheften)? Welches Jahr? Real betrachtet, nicht als verdrängendes Wunschdenken?
Skywalka hat vorgelegt: 2021.
Antwort von Roland Schulz:
Guckt mal was allein H.264 für Interlaced Video bereits auf der Pfanne hatte, das gab's so im hier referenzierten MPEG-2 (Thomson Artikel) noch nicht (der ohnehin nur bei SD Video relevanten Einsatz im Broadcast findet, BD agiert da noch zweigleisig) :
http://ngcodec.com/news/2014/1/22/how-d ... aced-video
Bei realem Inhalt die Effizienz hinter einer Kompression zu beurteilen finde ich am Schreibtisch aber dennoch schwierig.
In der Theorie "hätte" ich noch Potential bei Interlace gesehen, zumal adaptive Methoden zur Verfügung stehen, die bei relativ statischen Bildern "Richtung 1080/25p" agieren und bei Bewegungen, wo Details im Vergleich weniger auffallen, "Richtung ~"540/50p"~".
Ob ein progressiver Interframecodec aber nicht vielleicht doch besser agiert, finde ich schwierig abzuschätzen und nachzuweisen, zumal es da auch von der Qualität der Implementierung des Codecs abhängt und subjektive Komponenten Abhängigkeiten zeigen.
Trotzdem, "für mich" hat Interlace wenn überhaupt maximal noch auf der "letzten Meile" was zu suchen.
Am Ende hat allerdings selbstverständlich der Kunde das Sagen und stellt die Anforderungen. 50p nach 50i zu kriegen ist allerdings auch kein Hexenwerk, umgekehrt wird's schon aufwändiger.
Antwort von WoWu:
Das verlinkte Papier gibt leider nichts her, weil es lediglich die Ünertragungs-Methoden benennt, die in unterschiedlichen Codecs möglich sind aber nichts zur Bitrateneffizienz.
Was immer das in diesem Zusammenhang auch bringen soll erschließt sich mir daher nicht.
Antwort von Roland Schulz:
Das verlinkte Papier gibt leider nichts her, weil es lediglich die Ünertragungs-Methoden benennt, die in unterschiedlichen Codecs möglich sind aber nichts zur Bitrateneffizienz.
Was immer das in diesem Zusammenhang auch bringen soll erschließt sich mir daher nicht.
Sorry, will nicht wieder anfangen, aber das Thomson Sheet ist dagegen von gestern, da sich alles noch auf MPEG-2 bezieht und hier keine adaptive Encodierung wie in H.264/265 vorgesehen ist, zumal in der Praxis bei der Übertragung "nur" im SD Bereich eingesetzt wird.
Es ging im verlinken Text darum, dass der H.264/265 Codec bzw. Encoder, sofern implementiert, adaptiv erkennen kann und agiert, ob er in der jeweiligen Szene besser komplett progressiv codiert (Frame) oder "interlaced" (Field) codiert. Ob daraus jetzt ein Vorteil entsteht darf jetzt jeder selbst für sich selbst "versuchen" abzuleiten.
Ich wollte nur aufzeigen dass moderne Codecs "noch" für Interlaced aufgestellt oder sogar optimiert sind, man die Tür hier noch nicht zu gemacht bzw. Interlace abgeschrieben hat.
Die "Bitrateneffizienz" abzubilden ist ohnehin schwierig, über z.B. PSNR und SSIM abzuleiten mag für manche Situationen passen, für andere nicht. Qualitätsvergleiche bei Encodern werden oft auch nach subjektiven Wahrnehmungen entschieden (wie im Thomson sheet ebenfalls erwähnt).
Das Unterschiede da sind stellt man ganz schnell fest wenn man z.B. ein optimiertes x.264 Setup gegen nen Sandy-Bridge Quick-Sync Encoder o.ä. stellt. Die Bitrate ist am Ende vergleichbar, bei der Qualität liegen aber Sprünge dazwischen. Das würde ich mit "Bitrateneffizienz" bezeichnen. Das jetzt wirklich zu "messen" ist schwierig, genau so wenig wie man die Qualität im Audiobereich von ATRAC, PASC, MP3 oder AAC etc. wirklich "messen" kann.
Veröffentlichte Vergleiche beruhten meistens auf Hörtests mit subjektiven Wahrnehmungen.
In Frage steht zudem, ob die Algorithmen im Codec ggf. auf Progressive oder Interlaced hin optimiert sind oder das eine nur als ergänzende Funktion zum anderen implementiert wurde. Qualitätsunterschiede gibt"s auf jeden Fall.
Welcher Encoder jetzt in der Thomsonuntersuchung zum Einsatz kam bleibt auch offen, von daher ist das auch nicht viel wert.
Antwort von WoWu:
Sorry, aber das ist wieder mal ziemlich an den Haaren herbeigezogen, abgesehen davon, dass es selbst in MPEG2 adaptive Data schema gab, war MPEG 2 ohnehin für Interlace optimiert.
http://www.ece.ucsb.edu/wcsl/Publicatio ... SPIE07.pdf
Dass man in MPEG4 auf die Kombination von progressiv und Intrlace in einem Bild zurückgegriffen hat, bedeutet nicht, dass Interlace Schemata verbessert wurden.
Und dass man Datenrateneffizienz nicht über die SNR Messen kann, musst Du den Broadcastern und Encodingleuten mal erzählen.
Die machen das dann alle falsch.
Und wenn Du mir jetzt noch einreden willst, dass Interlace Bilder besser sind, als progressives Material, dann können wir ja gern mal die Artefakte einer Interlace Abtastung genauer ins Auge fassen, mal sehn, wo dann Interlace bleibt.
Es bleibt also dabei ... Interlace hat eine schlechtere Bitrateneffizienz gegenüber progressiv.
Im Übrigen gibt es in HEVC auch kein MBAFF oder PAFF mehr.
Das Thema ist also ohnehin begraben.
Übrigens war Thomson Brand immer führender Hersteller von Encodertechnologie ... und ist es heute noch.
Nur mal so.... was die Implementierung betrifft.
Antwort von Roland Schulz:
Sorry, aber das ist wieder mal ziemlich an den Haaren herbeigezogen, abgesehen davon, dass es selbst in MPEG2 adaptive Data schema gab, war MPEG 2 ohnehin für Interlace optimiert.
http://www.ece.ucsb.edu/wcsl/Publicatio ... SPIE07.pdf
Dass man in MPEG4 auf die Kombination von progressiv und Intrlace in einem Bild zurückgegriffen hat, bedeutet nicht, dass Interlace Schemata verbessert wurden.
Und dass man Datenrateneffizienz nicht über die SNR Messen kann, musst Du den Broadcastern und Encodingleuten mal erzählen.
Die machen das dann alle falsch.
Und wenn Du mir jetzt noch einreden willst, dass Interlace Bilder besser sind, als progressives Material, dann können wir ja gern mal die Artefakte einer Interlace Abtastung genauer ins Auge fassen, mal sehn, wo dann Interlace bleibt.
Es bleibt also dabei ... Interlace hat eine schlechtere Bitrateneffizienz gegenüber progressiv.
Im Übrigen gibt es in HEVC auch kein MBAFF oder PAFF mehr.
Das Thema ist also ohnehin begraben.
Übrigens war Thomson Brand immer führender Hersteller von Encodertechnologie ... und ist es heute noch.
Nur mal so.... was die Implementierung betrifft.
Die MPEG-2 Adaption hat null komma nichts mit der Adaption auf frame- oder fieldbasierte Kompression zu tun, welche ich angebracht hatte und welche immer noch in H.265 enthalten ist.
Warum hat Thomson in Deinem Sheet betont, dass man auch noch subjektive Tests gemacht hat, weil PSNR alles über die Ausgabequalität aussagt oder warum?! Was wer immer wie falsch macht lassen wir mal offen...
Interlacebilder sind keinesfalls allgemein besser als Progressive, das habe ich nie behauptet!
Was stellen wir eigentlich wozu in Vergleich? 1080i zu 25p oder 50p??
Antwort von WoWu:
Was verstehst Du denn unter Adaptiver Kompression, weil Du sagst, sie hätte nicht mit der von MPEG 2 zu tun ?
Sowohl die Möglichkeit, kompressionsalgorithmen dem Bildinhalt anzupassen, als auch die Möglichkeit einer skalierbaren Übertragung sind in MPEG2 möglich. Nur nannte man das damals Graceful Degradation.
Es hat nur nie jemand benutzt, aber es ist in MPEG2 enthalten.
Und was die Vergleichsfrage in Bezug auf 25 oder 50 angeht, so spielt das in Bezug auf die Übertragungseffizienz keine Rolle, weil die Performanzdifferenzen zumindest auf ein vergleichbares Niveau gebracht werden müssen, um überhaupt eine Effizienz vergleichen zu können.
Und das mit der "letzten Meile" musst Du mir auch nochmal erklären.
Willst Du ein Signal (bei Kabelfernsehen) vom Strassenverteiler bis zum Hausanschluss nochmal formatwandeln, denn das ist "die letzte Meile" ?
Was soll das denn werden ?
Das kann doch nun wirklich nicht Dein Ernst sein.
Sorry, aber ich kann mich mal wieder des Eindrucks nicht erwehren, dass Du nicht wirklich weißt, wovon Du sprichst.
"für mich" hat Interlace wenn überhaupt maximal noch auf der "letzten Meile" was zu suchen.
Antwort von Roland Schulz:
Was verstehst Du denn unter Adaptiver Kompression, weil Du sagst, sie hätte nicht mit der von MPEG 2 zu tun ?
Sowohl die Möglichkeit, kompressionsalgorithmen dem Bildinhalt anzupassen, als auch die Möglichkeit einer skalierbaren Übertragung sind in MPEG2 möglich. Nur nannte man das damals Graceful Degradation.
Es hat nur nie jemand benutzt, aber es ist in MPEG2 enthalten.
Und das mit der "letzten Meile" musst Du mir auch nochmal erklären.
Willst Du ein Signal (bei Kabelfernsehen) vom Strassenverteiler bis zum Hausanschluss nochmal formatwandeln, denn das ist "die letzte Meile" ?
Was soll das denn werden ?
Das kann doch nun wirklich nicht Dein Ernst sein.
Sorry, aber ich kann mich mal wieder des Eindrucks nicht erwehren, dass Du nicht wirklich weißt, wovon Du sprichst.
"für mich" hat Interlace wenn überhaupt maximal noch auf der "letzten Meile" was zu suchen.
Ich bezog mich bei "Adaptiv" in meinem urpsrünglichen Post auf die Erkennung zwischen Progressive und Interlace Anteilen im Bild selbständig und adaptiv in Abhängigkeit vom Bildinhalt durch den Codec - das kann H.264/265, MPEG-2 nicht.
MPEG-2 entscheidet selbständig nicht zwischen Interlace und Progressive im laufenden Stream und optimiert darauf hin die Kompression.
Dass auch MPEG-2 adaptive Algorithmen für andere Aufgaben besitzt habe ich nicht ausgeschlossen, da gebe ich Dir Recht, war aber wie bereits beschrieben nicht der Fokus - richtig lesen!!
Die "letzte Meile" ist für einen Nachrichtentechniker zugegeben nicht ganz..., nein unglücklich ausgedrückt!
Ich meine damit das Verlassen der Sendeanstalt, nicht z.B. DSLAM -> APL. Sorry wenn ich mich hier interpretierbar ausgedrückt habe!!
Und was die Vergleichsfrage in Bezug auf 25 oder 50 angeht, so spielt das in Bezug auf die Übertragungseffizienz keine Rolle, weil die Performanzdifferenzen zumindest auf ein vergleichbares Niveau gebracht werden müssen, um überhaupt eine Effizienz vergleichen zu können.
Das mach" mir mal vor, welches Niveau hat 1080i wirklich?!
Dazu von mir gleich mehr...
Antwort von Roland Schulz:
Hab gerade auf dem Heimweg bei ~300 Interlace am Mittelstreifen gehabt und nochmal über die Sache mit der Effizienz nachgedacht - nein, keine 300 auf dem Heimweg, effizient schon gar nicht ;-)!
Also, bei nochmaligem drüber Nachdenken behaupte ich, dass man die Effizienz zwischen 1080i und 1080(25/50p) nicht pauschal bewerten kann.
Was vergleichen wir womit?! 1080i mit 1080 25p? Da gehe ich mit dass 1080i "schwerer" zu komprimieren ist als 25p. Nur zum Verständnis:
Wenn wir das 1080i mit der modernsten Kompression über Topfield und Bottomfield als 2x540p übereinander in einen Frame legen, würden wir im Bild enthaltene Flächen auseinanderreissen und die Effektivität der Kompression klar einschränken.
Würden wir Top- und Bottomfield nacheinander in jeweils einem 540p Frame abbilden, hätten wir ständig alternierende Bilder, was ebenfalls nicht effektiv ist. Zwei 540p Streams parallel zu encodieren wäre das Selbe wie 2x540p Top-/Bottom übereinander in einem Frame.
Ich würde deshalb hier behaupten, dass 1080 25p effizienter zu codiedern ist als 1080i.
Aber, 1080i gibt uns mehr Informationsgehalt als ein 1080 25p, oder nicht?! Wir könnten nach Erkennung eines statischen Bildes Top- und Bottomfield zur Kompression in ein 25p Bild legen so wie es am Ende dargestellt wird, also z.B. das Topfield in die ungeraden und das Bottomfield in die geraden Zeilen. Das wäre ohne Zweifelsohne ein 25p Bild, allerdings auch nur "schön" bei statischem Inhalt. Jetzt hätten wir exakt das selbe Bild wie bei einem klassischen 25p, damit exakt die selbe Effizienz!!
Haben wir aber Bewegung im Bild entsteht der bekannte Kammeffekt im zuletzt beschriebenen "Progressive-Bild", welcher sich in Makroblöcken durch die "hohen vertikalen Frequenzanteile" nicht mehr so einfach komprimieren lässt. Es müsste also eine höhere Bitrate aufgewendet werden als zuvor, alternativ in die zuvor betrachtete Variante 2x540p gehen, welche "weniger Effizient" ist. Wir haben jetzt aber auch "mehr (Bewegungs-)information" im Bild als zuvor, die hohen Frequenzanteile durch die "Halbbildverschiebung" beweisen das.
Betrachtet man dagegen ein 1080i Bild gegen ein 1080 50p Bild ist klar, dass das 50p Bild bei nicht statischem Inhalt mehr Information, nämlich die "doppelte vertikale Auflösung" zur Verfügung stellt. Dann bräuchten wir aber auch eine höhere Bitrate um die nach Wahrscheinlichkeit höhere Anzahl von "kompletten" Intra-Bildern etc. abzubilden. Wie hoch ist der praktische Mehraufwand an Bitrate, wie hoch ist dagegen der Gewinn an Bildqualität für den Menschen??
Ich behaupte allgemein kann man die Frage nach Effizienz der Übertragung zwischen Interlace und Progressive nicht beantworten, auch PSNR geben nur begrenzt Auskunft über die Qualität eines dynamischen Bildes im Vergleich zu dem, wie es ein Mensch hinterher wahrnehmen und beurteilen würde.
Niemand wird beweisen können, dass PSNR die Qualität genau so beurteilt, wie sie der psychovisuellen Wahrnehmungen eines Menschen entspricht!! PSNR stellt fest dass das komprimierte Signal ein Maß an Abweichungen zu einem Ursprungssignal aufweist. Das es Abweichungen zum Ursprung gibt ist uns bei einer verlustbehafteten Kompression wie MPEG2, H.264 oder H.265 ohnehin klar denke ich.
Wie stark wir diese Abweichungen als Mensch aber wirklich wahrnehmen, darüber sagt PSNR nichts aus!
"Ich" stelle nichts weiter fest als was ich bereits beschrieben habe, nämlich dass auch aktuellste Codecs Optimierungen für Interlacevideo enthalten - die Effizienz darf gerne ein Seetest mit verschiedenem Inhalt und verschiedenen Personen beantworten - genau so wie es bei Audiocodecs auch gemacht wird.
...ähhhm, was hat das jetzt noch mit 4:2:0 -> 1/2*1/2 zu tun ;-) ;-) ;-)?!?!
Antwort von Roland Schulz:
...wir sind übrigens bald bei 7.000 Klicks ;-)!!
Antwort von mash_gh4:
...wir sind übrigens bald bei 7.000 Klicks ;-)!!
und fast genauso weit weg vom eigentlichen thema...
Antwort von WoWu:
Ich weiß nicht, ob Dir schonmal aufgefallen ist, dass MBAFF kein Interlace und auch kein progressiv ist, sondern ein eigenes Falgging hat.
Mir ist dann wohl entgangen, dass wir mittlerweile ein drittes Format vergleichen, das es übrigens in HEVC sowieso nicht mehr gibt.
Ich dachte immer, wir vergleichen die Dateneffizienz eines Interlace Datenstroms mit dem einer progressiv Codierung .... dann muss man das aber auch tun und nicht ein drittes Hybrid-Scanformat mit ins Spiel bringen, zumal das in der Ausstrahlung sowieso nicht zu gebrauchen ist, weil Blockmatching nicht rückwärts kompatibel ist und nach wie vor 80% der TV Geräte dabei aussteigen.
Die BBC und irgend ein italienischer Sender haben das mal für Fußball benutzt, aber sind schnell wieder davon ab gekommen.
Übrigens stellt sich die Frage, worin der Effizienzgewinn eigentlich besteht. Überwiegend eigentlich darin, dass man ein p/50 Signal nur noch mit der halben Menge statischer Bildinhalte versorgt, weil die ohnehin im Speicher des Players abgelegt sind.
Es ist also kein Vorzug von Interlace, weil die Bildgewinnung aus progressivem p/50 Material geschieht. Die interne Verarbeitung selektiert also "non progressive" Bildbestandteile, weil CMOS ohnehin progressive ausliest.
Das ganze hat also auch noch, wenn man es genau betrachtet, herzlich wenig mit Interlace zu tun, es wird nur immer (fälschlicherweise) damit in Zusammenhang gebracht.
Antwort von StanleyK2:
Herrje, ob das hier noch mal ein Ende findet?
Anderserseits: rekordverdächtige flame-wars müssen schon über 1000 Postings haben.
Antwort von Roland Schulz:
Ich weiß nicht, ob Dir schonmal aufgefallen ist, dass MBAFF kein Interlace und auch kein progressiv ist, sondern ein eigenes Falgging hat.
Mir ist dann wohl entgangen, dass wir mittlerweile ein drittes Format vergleichen, das es übrigens in HEVC sowieso nicht mehr gibt.
Ich dachte immer, wir vergleichen die Dateneffizienz eines Interlace Datenstroms mit dem einer progressiv Codierung .... dann muss man das aber auch tun und nicht ein drittes Hybrid-Scanformat mit ins Spiel bringen, zumal das in der Ausstrahlung sowieso nicht zu gebrauchen ist, weil Blockmatching nicht rückwärts kompatibel ist und nach wie vor 80% der TV Geräte dabei aussteigen.
Die BBC und irgend ein italienischer Sender haben das mal für Fußball benutzt, aber sind schnell wieder davon ab gekommen.
Übrigens stellt sich die Frage, worin der Effizienzgewinn eigentlich besteht. Überwiegend eigentlich darin, dass man ein p/50 Signal nur noch mit der halben Menge statischer Bildinhalte versorgt, weil die ohnehin im Speicher des Players abgelegt sind.
Es ist also kein Vorzug von Interlace, weil die Bildgewinnung aus progressivem p/50 Material geschieht. Die interne Verarbeitung selektiert also "non progressive" Bildbestandteile, weil CMOS ohnehin progressive ausliest.
Das ganze hat also auch noch, wenn man es genau betrachtet, herzlich wenig mit Interlace zu tun, es wird nur immer (fälschlicherweise) damit in Zusammenhang gebracht.
Was zum Teufel ist "Falgging"?!?! Manchmal kommen hier wunderliche Sachen an den Tag...;-)
Warum schon wieder so provokativ und angreifend?!?!
Hat irgendwer behauptet dass H.265/HEVC "MBAFF" hat?!?!?! Habe ich WO geschrieben?! Nirgends!!! Versuche nicht ständig mir das Wort im Mund umzudrehen, da drin sitzt noch alles fest und es wackelt nichts!
Achtung aufgepasst, jetzt kommt was Neues ;-): S A F F !!
Wenn das Abspielgerät bei entsprechend standardkonformen "getaggtem" Content aus dem Tritt gerät hat da wohl wer seine Hausaufgaben schlecht gemacht...
Über den Rest was ich über Effizienz geschrieben habe mal nachgedacht?! Theoretisch und hier werden wir das definitiv nicht lösen!!
Was das jetzt alles wieder mit nem CMOS zu tun hat möchte ich mal wissen, hab mehrfach geschrieben dass ich Interlace maximal "auf der letzten Meile" (ich denke viele haben"s verstanden), also auf dem Weg vom Sender zum Endgerät sehe, da wo die Bitrate immer noch "knapp" ist.
Davon ab "könnte" man wenn man wollte nen Interlaced CMOS bauen, man macht schließlich auch Lineskipping und Windowing und den ganzen Zauber, also überhaupt keine Kunst!! SOLL MAN ABER NICHT !!!
Maximal vor der Übertragung zum Kunden kann man drüber nachdenken, und wer aus 50p kein 50i hinkriegt hat"s System nicht verstanden oder versucht"s mit"m Movie Maker auf nem Siemens S4 ;-).
Antwort von Roland Schulz:
Herrje, ob das hier noch mal ein Ende findet?
Anderserseits: rekordverdächtige flame-wars müssen schon über 1000 Postings haben.
...eigentlich hab"n wir uns ganz doll lieb ;-) ;-) ;-)!!!
Antwort von StanleyK2:
...
...eigentlich hab"n wir uns ganz doll lieb ;-) ;-) ;-)!!!
Trotzdem würde ich an deiner Stelle mal was anderes rauchen bzw. schlucken ...
Antwort von Roland Schulz:
...
...eigentlich hab"n wir uns ganz doll lieb ;-) ;-) ;-)!!!
Trotzdem würde ich an deiner Stelle mal was anderes rauchen bzw. schlucken ...
Irgend nen Problem oder was nicht klar verstanden?!?!
Antwort von WoWu:
Was zum Teufel ist "Falgging"?!?!
Aber was eine Flag ist, weist Du ?
Oder auch nicht ?
Hat irgendwer behauptet dass H.265/HEVC "MBAFF" hat?!?!?! Habe ich WO geschrieben?! Nirgends!!!
Ja, hier:
Die MPEG-2 Adaption hat null komma nichts mit der Adaption auf frame- oder fieldbasierte Kompression zu tun, welche ich angebracht hatte und welche immer noch in H.265 enthalten ist.
Und nachdem wir nun definiert haben, dass Du MBAFF damit meinst, ist das ziemlich eindeutig, nur dass Du statt HEVC, H.265 geschrieben hast.
Über den Rest was ich über Effizienz geschrieben habe mal nachgedacht?!
Soviel wie "die letzte Meile" die war genauso daneben.
Was das jetzt alles wieder mit nem CMOS zu tun hat möchte ich mal wissen
Sowas kann man nachlesen, nur soll mich das jetzt wundern, dass solche Zusammenhänge nicht bekannt sind ?
50p kein 50i hinkriegt
Das ist ja mein Reden, guck Dir mal an, wie MBAFF funktioniert, dann wirst Du auch die Zusammenhänge zum CMOS und den p/50 verstehen.
Das hat nämlich mit Interlace Abtastung rein gar nichts mehr zu tun sondern ist ein eigenständiges Scanverfahren, das sich aus progressiv abgetasteten Bildern zusammensetzt, nur dass sich wiederholende Makroblöcke nicht nochmals ausserhalb eines definierten Feldes übertragen werden, was über das Flag mitgeteilt wird, sodass diese Makroblöcke im Bildspeicher bleiben.
Das funktioniert leider völlig anders, als Interlace.
Interlace maximal "auf der letzten Meile"
Du brauchst gar nicht rudern .... das hat schon jeder richtig verstanden.
Speziell, wenn es sich um fast 40.000 Meilen über eine Satausstrahlung handelt. Kann man ja gar nicht verwechseln.
Antwort von Roland Schulz:
Was zum Teufel ist "Falgging"?!?!
Aber was eine Flag ist, weist Du ?
Oder auch nicht ?
...na wenn da mal "Flag" gestanden hätte...->
Hat irgendwer behauptet dass H.265/HEVC "MBAFF" hat?!?!?! Habe ich WO geschrieben?! Nirgends!!!
Ja, hier:
Die MPEG-2 Adaption hat null komma nichts mit der Adaption auf frame- oder fieldbasierte Kompression zu tun, welche ich angebracht hatte und welche immer noch in H.265 enthalten ist.
Und nachdem wir nun definiert haben, dass Du MBAFF damit meinst, ist das ziemlich eindeutig, nur dass Du statt HEVC, H.265 geschrieben hast.
...-> ich habe zumindest immer noch nichts über MBAFF im Ursprung geschrieben, ich habe über ein Verfahren geschrieben welches während der Komprimierung Interlace und Progressive erkennen, unterscheiden und adaptiv agieren kann! MBAFF war Dein Kind, meins heißt SAFF und kommt halt in H.265/HEVC vor!!
...und bevor Du definieren darfst was ich geschrieben habe und gemeint haben will brauchst Du mehr als Straßenbahnschienen um mich aus der Spur zu werfen - ich hab" ziemlich breite Reifen!!
Flag <> Tag... ach was, Kindergarten!
Über den Rest was ich über Effizienz geschrieben habe mal nachgedacht?!
Soviel wie "die letzte Meile" die war genauso daneben.
Na ja, die letzte Meile hatte ich ja aufgeklärt, denke das sollte klar sein und sinnbildlich in ner Produktionslinie passt das dann auch (ungefähr ;-) ). Vom Mond aus betrachtet spielt das gar keine Rolle!
Was das jetzt alles wieder mit nem CMOS zu tun hat möchte ich mal wissen
Sowas kann man nachlesen, nur soll mich das jetzt wundern, dass solche Zusammenhänge nicht bekannt sind ?
Ne, erklär mal wo ich was über das Kamerasyndrom zu Lesen finde - immer kommst Du mit Kameras um die Ecke, das kann man abstrahieren! Es spielt wieder einmal überhaupt keine Rolle ob die Quelle jetzt aus nem CMOS, nem progressive CCD oder ner CGI oder sonst woher kommt!!!
50p kein 50i hinkriegt
Das ist ja mein Reden, guck Dir mal an, wie MBAFF funktioniert, dann wirst Du auch die Zusammenhänge zum CMOS und den p/50 verstehen.
Das hat nämlich mit Interlace Abtastung rein gar nichts mehr zu tun sondern ist ein eigenständiges Scanverfahren, das sich aus progressiv abgetasteten Bildern zusammensetzt, nur dass sich wiederholende Makroblöcke nicht nochmals ausserhalb eines definierten Feldes übertragen werden, was über das Flag mitgeteilt wird, sodass diese Makroblöcke im Bildspeicher bleiben.
Das funktioniert leider völlig anders, als Interlace.
Ist Dir klar dass die Makroblöcke erst nach der Entscheidung in progressive oder interlace zu komprimieren entstehen?!?! Auch klar dass man interlace auf verschiedene Art (wie von mir beschrieben) als progressive codiert, der Interlaceeffekt am Ende aber bestehen bleibt?!
Interlace maximal "auf der letzten Meile"
Du brauchst gar nicht rudern .... das hat schon jeder richtig verstanden.
Speziell, wenn es sich um fast 40.000 Meilen über eine Satausstrahlung handelt. Kann man ja gar nicht verwechseln.
...hast ja doch Sinn für Humor ;-)! Die letzte Strecke in der Produktionsstrecke definiere ICH für UNS jetzt mal als die letzte Meile - ist doch nicht sooo schwierig und abstrakt, oder ;-)?!?! Aber wenn"s ohnehin mittlerweile jeder verstanden hat brauch" ich auch keine 40.000 Meilen rudern!
Antwort von WoWu:
Mit den breiten Reifen hast Du wohl Recht... schade, dass sie alle platt sind.
Antwort von Roland Schulz:
...die Zitiererei wird langsam zu komplex - lass" uns neu anfangen sonst gehen uns die Leser aus weil"s zu kompliziert zu lesen wird, man am Ende das Popcorn raucht und die zu schluckenden Pillen über die letzten 40.000 Meilen bis zum Mond spuckt ;-)!!
Antwort von Roland Schulz:
Mit den breiten Reifen hast Du wohl Recht... schade, dass sie alle platt sind.
Ganz platt oder nur unten????
Sorry, hab Runflat, die sehen nur so platt aus ;-)!!
Antwort von WoWu:
Die 40000 Meilen haben mit dem Mond nichts zu tun sondern sind vom Boden, einmal zum Satelliten in geostationärer Umlaufbahn (32.O00 km) und wieder zum Sät Empfänger.
Das sind bummelig 40.000 Meilen, also ein ganz normaler Sendeweg und hat mit dem Mond nichts zu tun.
Antwort von Roland Schulz:
Die 40000 Meilen haben mit dem Mond nichts zu tun sondern sind vom Boden, einmal zum Satelliten in geostationärer Umlaufbahn (32.O00 km) und wieder zum Sät Empfänger.
Das sind bummelig 40.000 Meilen, also ein ganz normaler Sendeweg und hat mit dem Mond nichts zu tun.
Kommt "Sät" aus dem Norden?!?!? Meine Güte, nen bisschen gelacht haste bestimmt auch, nicht?!?!? Ich geb" mir hier so eine Mühe, weil wir ja sachlich nicht auf nen Nenner kommen!
Antwort von Roland Schulz:
...wenn wir mal gemeinsam produktiv geworden wären hätte ne Scart-Kupplung BNC Stecker drin gehabt ;-)!!
Antwort von WoWu:
ne, aber mit 30 den ersten Herzinfakt.
SAFF ist übrigens nichts Anderes als das Einbetten eines Signals beliebiger (geringerer) Auflösung in ein gesamtes HEVC Frame und funktioniert auch nur auf GOP Basis, die bei HEVC, genau wie bei H.264 von IDR zu IDR ziemlich Lang sein kann.
Das ist also nichts weiter, als ein Tool, wie eine Kapsel, in die Du jede beliebige Bildauflösung einbetten kannst und hat mit Interlace nix am Hut, da findet keine Verkammung oder soetwas statt da findet immer ein volles Bild statt.
Antwort von Roland Schulz:
Da bin ich bald ne Dekade drüber weg - ohne Herzinfarkt ;-)!!
So wie ich's verstanden habe kann SAFF interlaced fields oder frames speichern. Mit der Group-OP haste natürlich Recht, kann mir auch nicht vorstellen das es anderswo anders funktioniert hat, das geht nie framegenau adaptiv!! Verkammt braucht's aber auch nicht gespeichert werden -> zwei halbhohe Vollbilder... Verkammung erst wieder beim Auspacken.
Ich geh' schlafen - gute Nacht!!
Antwort von MLJ:
@Roland Schulz
Zitat:
"Was bedeutet 4:4:4 bezogen auf die Pixelebene ;-) !?!?!?!"
Zitat ende.
Bedeutet nur das es keine Reduzierung im Chroma gibt. Wenn du meine verlinkten Seiten aufgerufen und gelesen hättest würdest du diese Frage nicht immer wieder hier stellen ;)
Off-Topic:
Was Interlacing/De-Interlacing betrifft so wirfst du da vieles durcheinander und schlage vor du machst einen neuen Thread auf denn dieser Thread ist nun wirklich genug "zerpflückt", meinst du nicht ? :) Man sollte zumindest hier beim eigentlichem Thema bleiben wenn dieser Thread weiter "leben" soll ;)
Cheers
Mickey
Antwort von Roland Schulz:
@Roland Schulz
Zitat:
"Was bedeutet 4:4:4 bezogen auf die Pixelebene ;-) !?!?!?!"
Zitat ende.
Lieber Mickey,
ich habe alles verstanden und auch eine Grafik dazu erstellt, dabei ständig Deine u.A. Aussage gepredigt! Es gab nur zwei drei Mitglieder hier, die es nicht vestanden haben oder wollten bzw. eine andere Meinung durchzusetzen versuchten. Deshalb habe genau diesen Leuten die Frage erneut gestellt, damit sie sich die Bestätigung selbst liefern können!
Wenn Du "am Gas" geblieben wärst wäre Dir das sicher klargeworden ;-)!!
Bedeutet nur das es keine Reduzierung im Chroma gibt. Wenn du meine verlinkten Seiten aufgerufen und gelesen hättest würdest du diese Frage nicht immer wieder hier stellen ;)
Off-Topic:
Was Interlacing/De-Interlacing betrifft so wirfst du da vieles durcheinander und schlage vor du machst einen neuen Thread auf denn dieser Thread ist nun wirklich genug "zerpflückt", meinst du nicht ? :) Man sollte zumindest hier beim eigentlichem Thema bleiben wenn dieser Thread weiter "leben" soll ;)
Cheers
Mickey
Auch Interlace habe ich komplett verstanden und versucht meine Ansicht zu vermitteln, warum ich Interlace "auf der letzten Meile", um Verwechselungen zu vermeiden, auf der Strecke von der Sendeanstalt bis zum Endgerät noch nicht für gestorben betrachte.
Ich bin keineswegs ein Interlaceverfechter, mein Standpunkt ist der, dass es bis zur Übertragung nichts mehr zu suchen hat, Ü-Wagen dürften als Ausnahme gelten.
Ansonsten lies Dich mal durch, macht alles Sinn auch in Bezug auf moderne Codecs, die Interlace immer noch mit adaptiven Codierungen optimiert unterstützen. Wenn Du hier nur die letzten drei Posts liest stehst Du nur im Wald, erkennst den Zusammenhang nicht.
Die Idee hier Interlace reinzubringen kam übrigens nicht von mir...
Antwort von MLJ:
Hallo Roland,
sorry, du hattest Recht und wollte dich in keiner Weise "angreifen", okay ?
Zitat:
"Ansonsten lies Dich mal durch, macht alles Sinn auch in Bezug auf moderne Codecs, die Interlace immer noch mit adaptiven Codierungen optimiert unterstützen. Wenn Du hier nur die letzten drei Posts liest stehst Du nur im Wald, erkennst den Zusammenhang nicht.
Die Idee hier Interlace reinzubringen kam übrigens nicht von mir..."
Zitat ende.
So langsam nimmt dieser Thread einfach Dimensionen ein wo kaum einer mehr einen Zusammenhang findet ohne alles lesen zu müssen um den Faden nicht zu verlieren ;)
Was "4:4:4 auf Pixelebene" betrifft so dachte ich, dass diese Frage noch für dich (!) und NICHT für andere offen ist. Das kam in deinen Beiträgen leider nicht klar hervor, deswegen mein Kommentar an dich dazu, also nichts für Ungut ;)
Interlace/De-Interlace:
Ich sehe uns noch lange damit konfrontiert und nicht als "gestorben" an. Auch die Auswirkungen auf die Bandbreite und Bitrate ist eher Theorie als Praxis was die "Ersparnis" angeht. Diese Webseite veranschaulicht was es mit Interlaced/Progressiv so auf sich hat. Ist zwar nicht ganz neu aber Interessant:
http://www.100fps.com/
Trotzdem schlage ich vor dass du, sofern sich hier die Beiträge wegen Interlaced weiter anhäufen, einen neuen Thread ins Leben rufst, ist jetzt schon schwierig zu folgen :) Und ja, du hast Interlaced richtig verstanden :)
Zitat:
"Wenn Du "am Gas" geblieben wärst wäre Dir das sicher klargeworden ;-)!!"
Zitat ende.
Ich hatte mich deswegen ausgeklinkt weil hier bereits alles geschrieben wurde, was es zum (eigentlichem) Thema zu schreiben gab ;)
Cheers
Mickey
Antwort von srone:
lustige diskussion, alles eine frage der sichtweise, wo der amateur glaubt, ein mehr an informationen zu bekommen, der broadcast purist, dankend ablehnt, denn eine interpolation, ist und bleibt eine interpolation, was läuft schief im signalweg, dass ich überhaupt interpolieren muss?
lg
srone
Antwort von Roland Schulz:
...was läuft schief im signalweg, dass ich überhaupt interpolieren muss?
Da 3-Chipper heute rar gesät sind, müssen wir fast immer irgendwas interpolieren, und wenn nur beim Debayering - so traurig das auch ist!
Antwort von Jott:
Wäre das ein Problem, würde Hollywood zusammenbrechen mit seinen Alexas und REDs.
Antwort von Roland Schulz:
Wäre das ein Problem, würde Hollywood zusammenbrechen mit seinen Alexas und REDs.
*IRONIE EIN*
..."da" kommt ja auch grundsätzlich nur Schrott bei raus!!
*IRONIE AUS*
...weil nicht Sony drauf steht ;-)!!
Antwort von srone:
...was läuft schief im signalweg, dass ich überhaupt interpolieren muss?
Da 3-Chipper heute rar gesät sind, müssen wir fast immer irgendwas interpolieren, und wenn nur beim Debayering - so traurig das auch ist!
tja, und da fängt sichtweise an, was ist die wahrheit, auf was "will" ich mich einlassen?
lg
srone
Antwort von WoWu:
Auch viele 3-Chiper sind nicht frei von Interpolation weil speziell in den höheren Auflösungen oft mit PixelShift gearbeitet wird. Und PixelShift Verfahren "schielen" nun mal und machen nicht nur doppelte Kanten sondern auch interpolierte Bilder. Deswegen sind oft bei 3-Chipern farbige Flächen so schwammig und durch das Shiften geht auch die MTF in den Keller.
Nicht immer sind die Vorteile von 3-Chip drin, wenn 3-Chip drauf steht.
Und wenn dann noch ein schlechtes, nicht angepasstes Objektiv drauf sitzt, sind die Ergebnisse manchmal enttäuschender als mit einer 1-Chip.
Antwort von Roland Schulz:
Richtig, besonders Panasonic fällt mir da ein, wobei andere sicherlich auch nicht immer ganz nativ waren.
Zudem kann ein 3-Chipper auch lichtschwächer sein, weil das vorgelagerte Prisma Licht schluckt. Bei nem 1-Chipper ohne Prisma kann aus den grünen Pixeln, welche in doppelter Anzahl der roten und blauen vorliegen, theoretisch mehr an Helligkeitsinformation (nicht Auflösung) gewonnen werden als aus dem/den Sensoren hinter dem Prisma.
Nichts ist perfekt...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
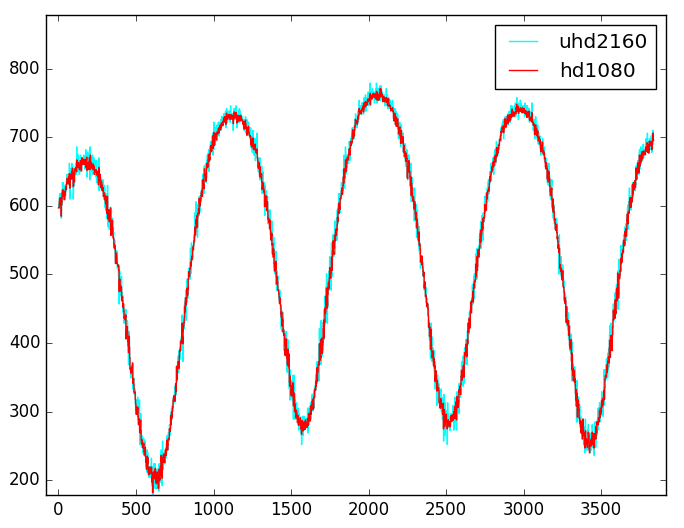{kind=link}
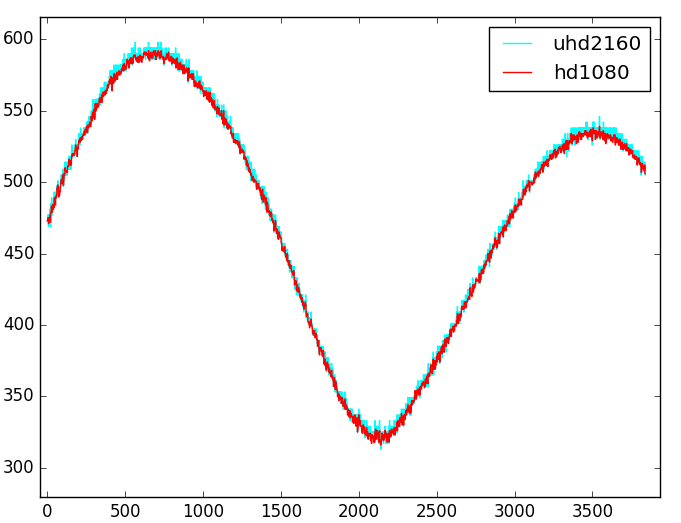{kind=link}
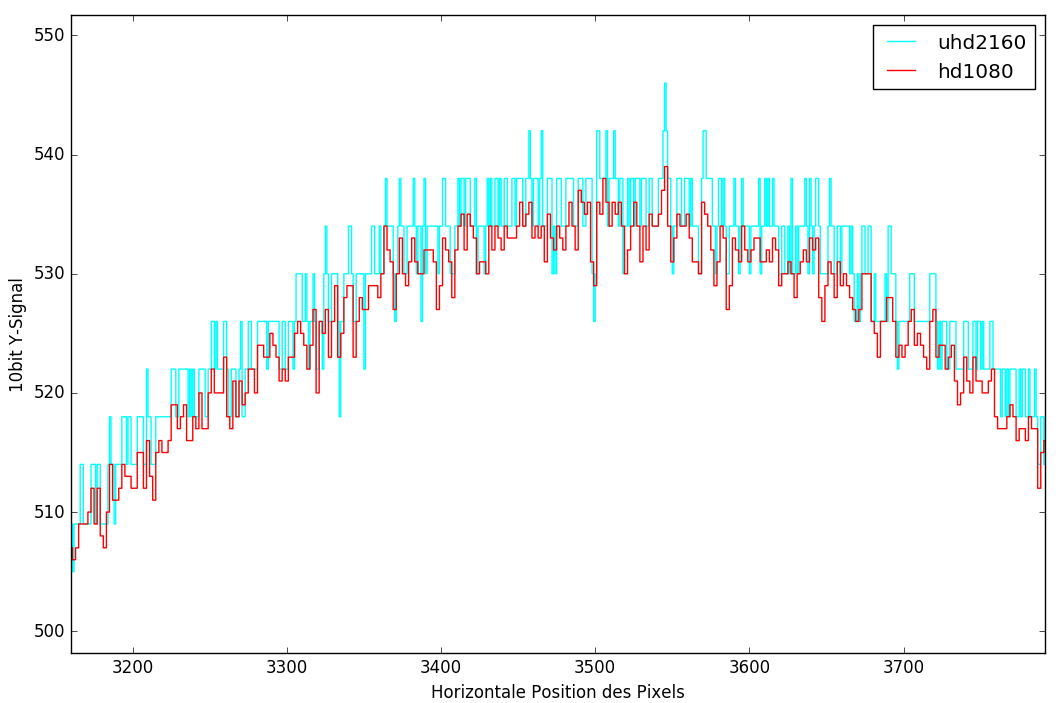{kind=link}
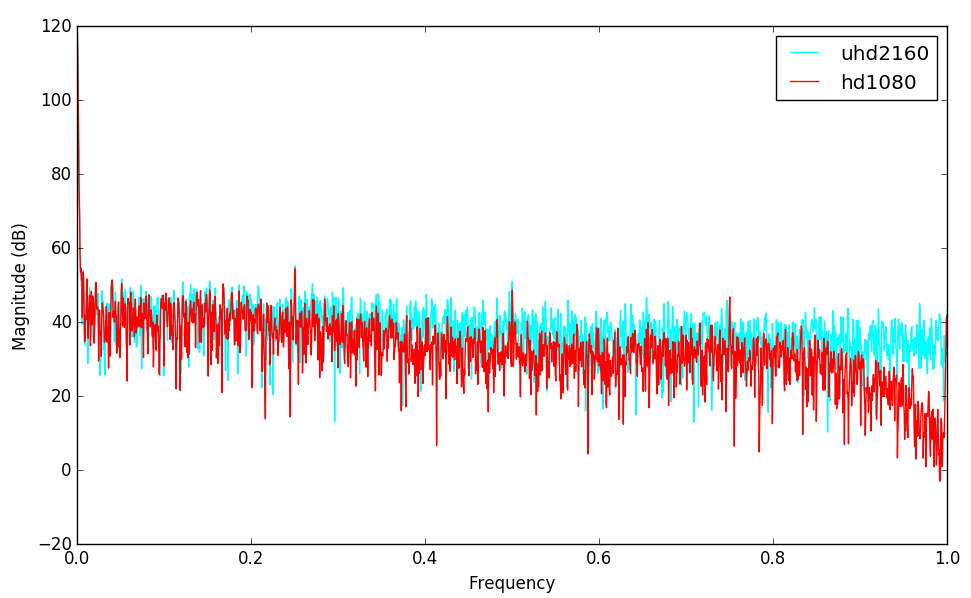{kind=link}
{kind=link}
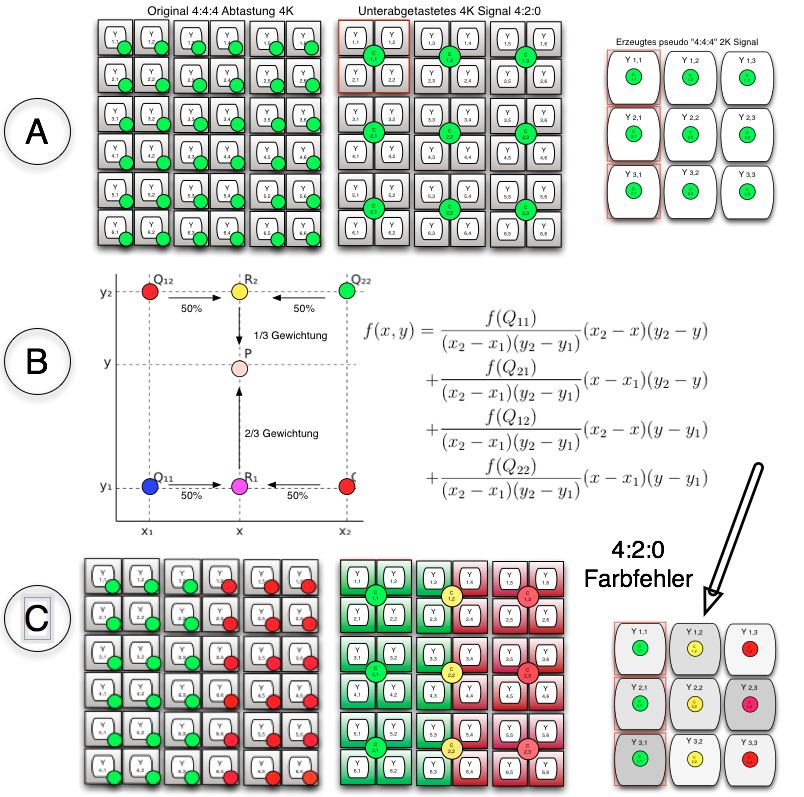{kind=link}